
通義千問的圖像推理能力,最近有了大幅提升。
2024 年,大模型領域要卷什么?
如果沒有思路的話,不妨看看各家大廠都在押注什么方向。
最近一段時間,先是 AI target=_blank class=infotextkey>OpenAI 推出 GPT-4V,讓大模型擁有了前所未有的圖像語義理解能力。

谷歌隨后跟上,發布的 Gemini 成為了業界第一個原生的多模態大模型,它可以泛化并無縫地理解、操作和組合不同類型的信息,包括文本、代碼、音頻、圖像和視頻。

很明顯,新的方向就是多模態。繼 GPT-4 在語言方向的里程碑式突破之后,業界普遍認為「視覺」是下一個爆發的賽道。畢竟人類的五感之中有 80% 是視覺信息,未來的大模型也應該充分利用更多種類的感官,以此探索實現 AGI 的路徑。
不只有 GPT-4V、Gemini,在這個充滿潛力的方向上,國內的技術力量同樣值得關注:最近的一個重要發布就來自阿里,他們新升級的通義千問視覺語言大模型 Qwen-VL-Max 在上周正式發布,在多個測評基準上取得了好成績,并實現了強大的圖像理解的能力。
我們還記得 Gemini 發布之后,谷歌馬上被曝出給 Demo 加速。這讓人們對新技術產生了一些質疑,并開始好奇:在當下的各路多模態大模型中,到底哪家比較強?
Demo 不作數,實際一測便知。有人拿著自己的名片給 GPT-4V 和 Qwen-VL-Plus 看,高下立見了:值得注意的是,去年底升級的 Plus 版還不是 Qwen-VL 的最強版本,最近發布的 Max 才是。


圖源:https://x.com/altryne/status/1742597044781395982?s=20
在 Qwen-VL-Plus 發布后,國內也有人拿 Gemini 演示視頻里的問題對它進行了測試,發現所有問題 Qwen-VL-Plus 完全都能回答上來。

一系列測評看下來,我們確實可以說,Qwen-VL 的整體能力已經達到了媲美 GPT-4V 和 Gemini 的水平,在多模態大模型領域實現了業內領先。
Qwen-VL 如何追平 GPT-4V、Gemini?
事實上,通義千問的視覺理解大模型已經經歷了幾輪迭代。
早在去年 8 月,阿里就放出了 Qwen-VL 模型的第一個版本,并很快對通義千問進行了升級。Qwen-VL 支持以圖像、文本作為輸入,并以文本、圖像、檢測框作為輸出,讓大模型真正具備了「看」世界的能力。
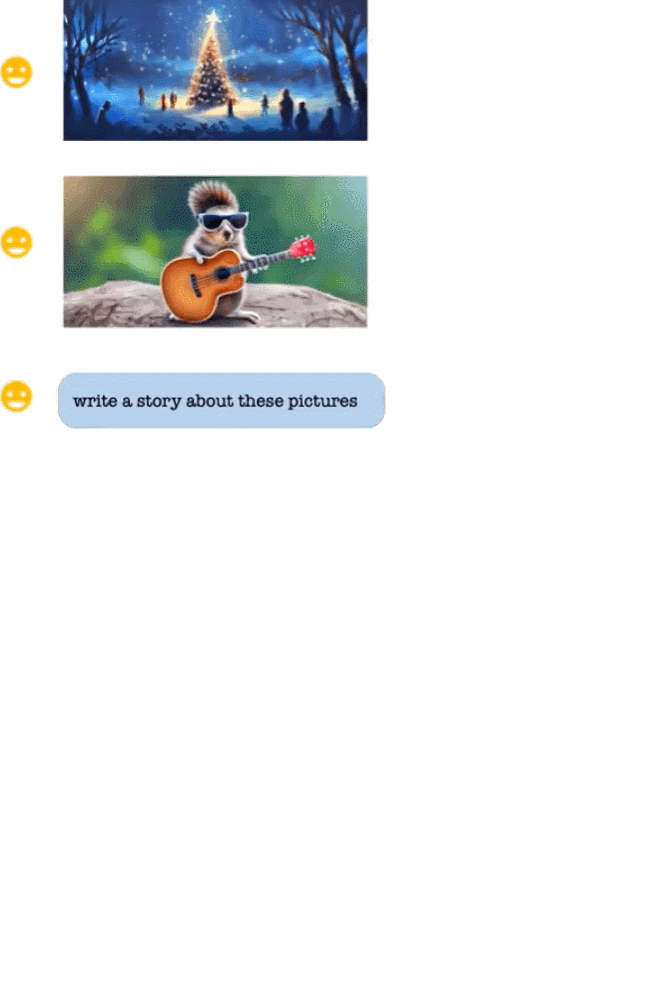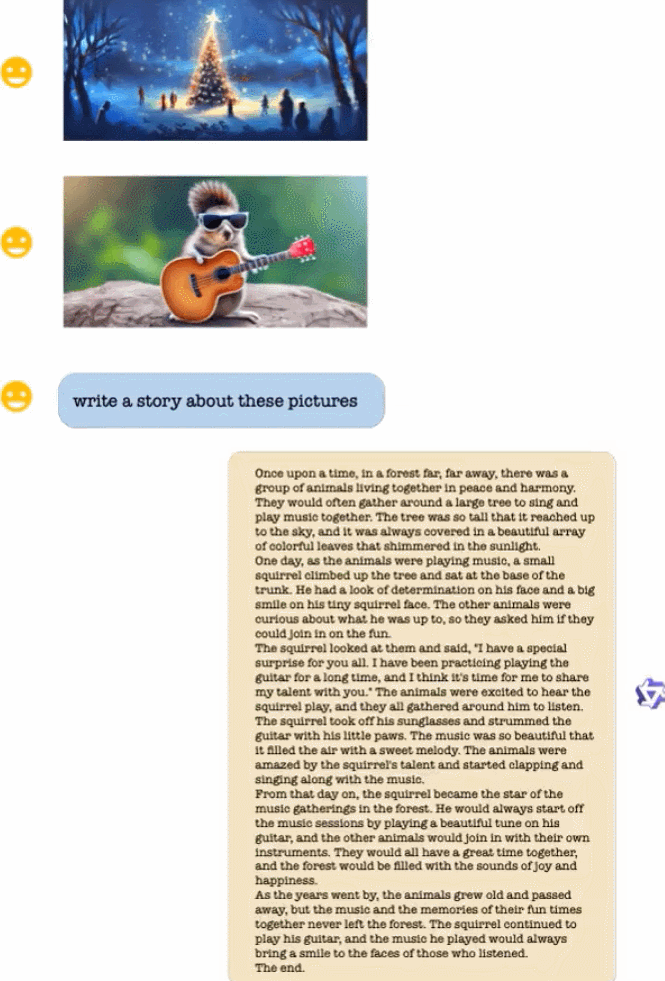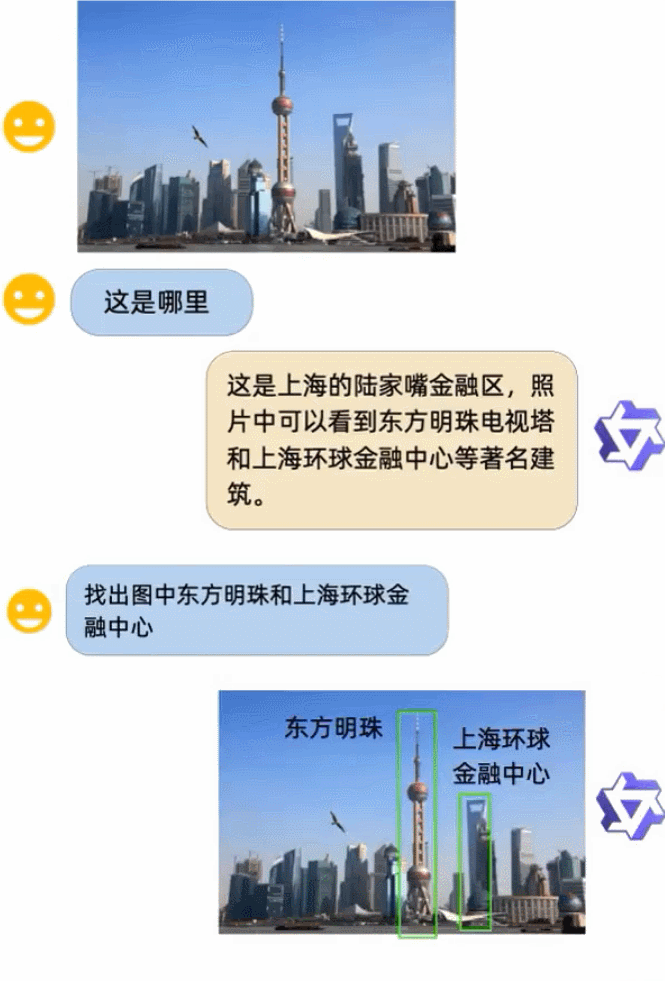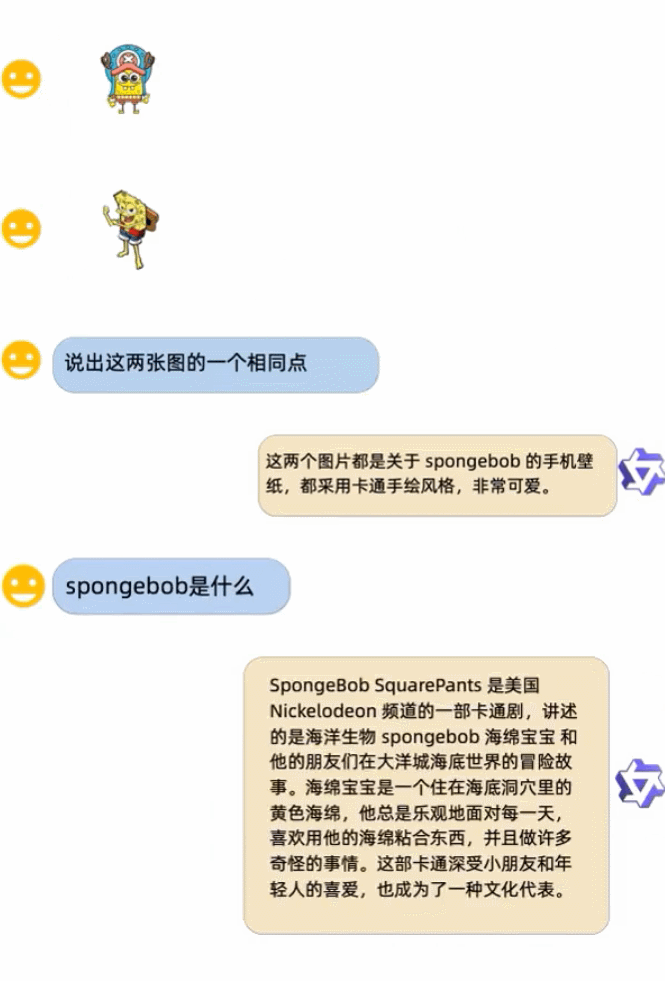
圖片來源:https://Twitter.com/Gorden_Sun/status/1696021151753855331
經歷了幾個月的改進,Qwen-VL 的整體能力又有了一個躍升,陸續推出 Plus 和 Max 兩大升級版本,限時免費使用。用戶可以在通義千問官網、通義千問 App 直接體驗 Max 版本模型的能力,也可以通過阿里云靈積平臺(DashScope)調用模型 API。

相比于開源版本的 Qwen-VL,這兩個模型在多項圖文多模態標準測試中獲得了堪比 Gemini Ultra 和 GPT-4V 的水準,并大幅超越此前開源模型的最佳水平。
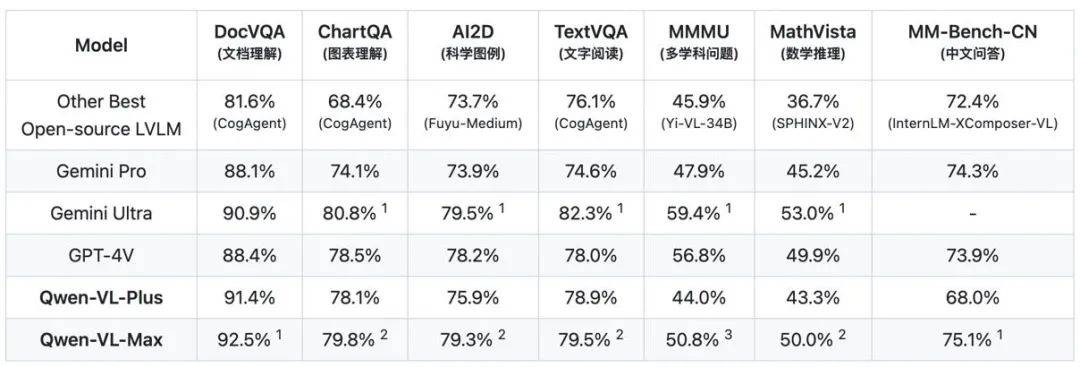
在多模態大模型性能整體榜單 OpenCompass 中,Qwen-VL-Plus 緊隨 Gemini Pro 和 GPT-4V,占據了前三名的位置。
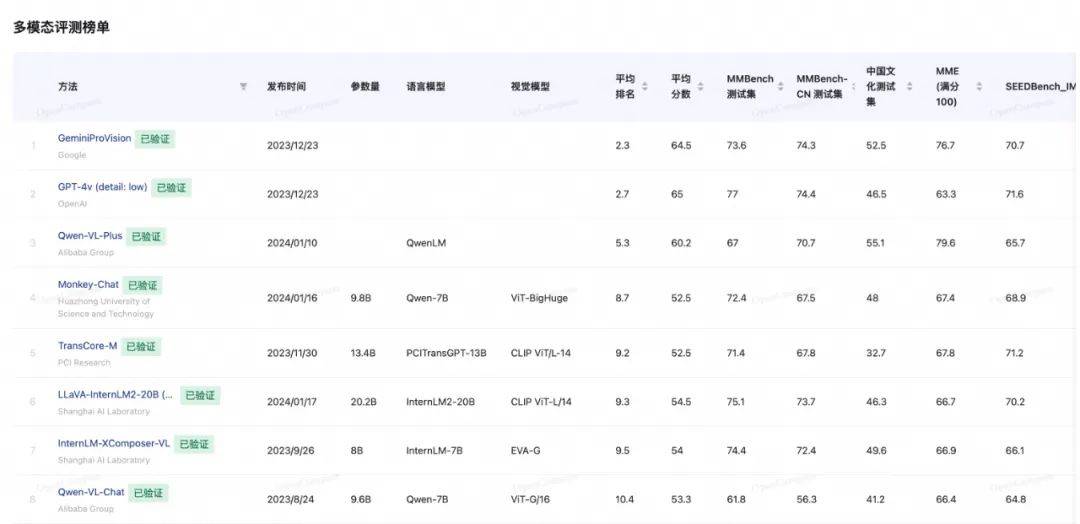
圖片來源:https://opencompass.org.cn/leaderboard-multimodal
Qwen-VL Plus 和 Max 支持百萬像素以上的高清圖,甚至各種極端長寬比的圖片。

它們不僅有高水平的基準評測性能,在真實場景中展現出來的解決問題的能力也有顯著提高,不僅可以輕松進行對話,識別名人、地標,生成文本內容,視覺推理能力也有明顯改善。
開發者一手實測
Qwen-VL 發布以來,從開源社區到社交網絡上,我們已經看到了一系列「花活」。
接下來,我們從普通用戶的角度,再來考驗一下升級版的 Qwen-VL。
給它一張《繁花》里面 90 年代初的上海灘照片:

通義千問識別出了這里是上海外灘,還能介紹一下黃浦江的景色,以及上海海關大樓等特定建筑物。
劇中提到的炒飯內含多少卡路里?

看起來大模型可以理解并聯系一些知識。
除了基礎的描述和識別能力外,Qwen-VL 模型還具備視覺定位能力和針對畫面指定區域進行問答的能力。比如,根據指示進行目標檢測。

如果你在截圖上圈住一部分,它可以對其中的內容進行解釋:
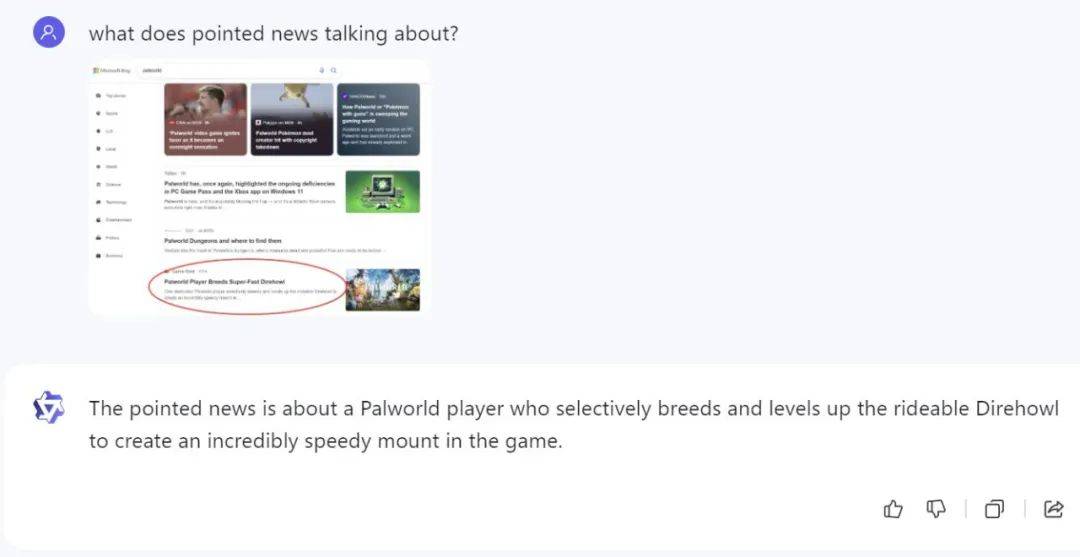
新升級的 Qwen-VL 模型最顯著的進步之一是基于視覺完成復雜推理的能力,比如理解流程圖這種復雜的表示形式:

與此同時,升級后的 Qwen-VL 處理圖像中文本的能力也有了顯著提高,不管是識別中文還是英文文本。Qwen-VL-Plus/Max 可以有效地從表格和文檔中提取信息,并將這些信息重新格式化,以滿足自定義輸出要求。
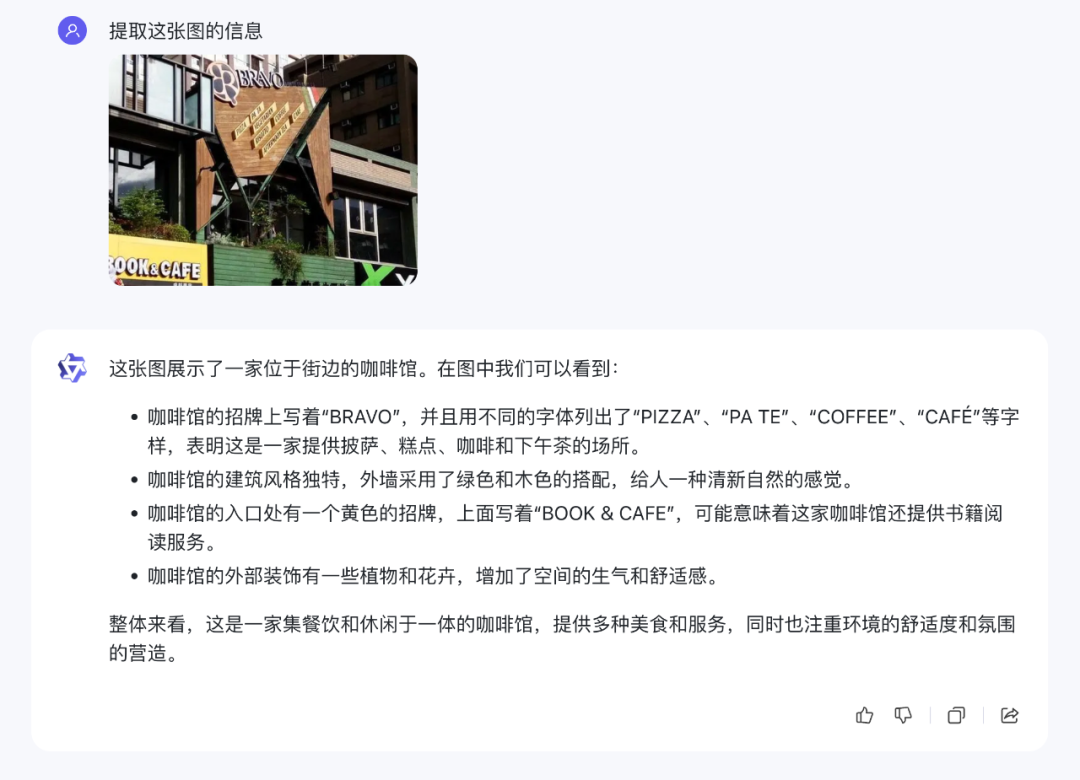

四個多月就有如此進步,這就讓人們開始感嘆,阿里通義千問大模型更新夠快,能力夠強。
阿里多模態大模型,正在爆炸式發展
能夠達到如今的水準,Qwen-VL 的技術實力不是一朝一夕煉成的。
在多模態大模型方向上,阿里很早就開始布局。從 2021 年 M6 系列的預訓練 - 微調模式,到 2022 年 OFA (One-For-All) 系列的統一模態表示和任務的模式,再到 OFASys 的系統化 AI 學習的嘗試,通義千問團隊的目標是做出和人一樣能聽、能看、能理解 & 溝通的通用 AI 模型(系統)。
2022 年,阿里開源了 OFA。OFA 能通過自然語言來描述一個圖文多模態任務,比如輸入「描述一下這張圖片」,模型就會嘗試去產生一個合適的圖像描述,打破了大家對通用多模態任務模型效果不如專用多模態模型的傳統觀念。這篇被 ICML 2022 接收的論文思路啟發了后續的許多研究,被谷歌、微軟、Meta 等眾多國際大廠所引用,是近年來多模態方向的高引論文之一。
2023 年以來,通義千問團隊延續了 OFA 的研究路線,利用通義千問語言模型的能力,彌補了過去多模態模型在新任務泛化能力上的缺陷,相關成果就是 2023 年下半年我們看到的開源圖文多模態模型 Qwen-VL 和音頻多模態模型 Qwen-Audio。

與此同時,阿里云通義實驗室的一系列視覺生成類成果,也徹底火出了圈,社交網絡上時不時可以看到利用通義 AI 技術生成的動圖。
比如只需一張圖片即可生成跳舞視頻的 Animate Anyone,在國內外都引發了大量關注:

再比如實現真人百變換裝的 Outfit Anyone。這項技術不僅能夠精確地處理服裝的變形效果,并且能調整以適應不同的姿勢和體形,實現更加逼真的試穿體驗。無論是動畫形象還是真人,都可以一鍵換裝,讓「QQ 秀」真正升級成了真人版。

此外,通義實驗室的文生視頻模型 I2VGen-XL 也是實實在在地火了一把,生成的視頻兼顧高清、高分辨率、平滑、美觀,毫不遜于 Gen2、Pika 效果。


I2VGen-XL 生成視頻結果。
眾所周知,通用人工智能的求索之路相當漫長,而大模型的技術突破,已經為我們指出了一個光明的方向。過去一年多,人們見證了一場激烈的 AI 技術角逐,賽道上不乏來自中國的選手。
以往,大模型領域的廠商大多以 OpenAI 為標桿,需要承認的是,OpenAI 的最新一代對話大模型 GPT-4 仍然在語言領域保持著領先優勢。
但在接下來的 2024 年,在下一個最具爆發潛力的技術方向 —— 多模態大模型上,中國的技術與產品或可與 OpenAI、谷歌這樣的選手掰一掰手腕。像 Qwen-VL 這樣的國產大模型,能否實現從追平到進一步超越?會不會再誕生一批爆款應用?這些都是接下來一年值得期待的事情。
長遠來看,在多模態大模型進一步實用化之后,我們以后可以更加理直氣壯,讓 AI 自動識別圖像和音頻中的內容,進行總結、摘要和分析,新技術勢必會大幅度提升我們的工作效率;我們在 AR、VR 世界中與環境的交互也會更加便捷,可穿戴設備的體驗將會更具真實感,新應用可以大幅改進娛樂和日常體驗。
更加直觀的是,多模態大模型能夠根據每個人的喜好生成定制化內容和產品,對于阿里來說,這件事很重要。
或許,隨著多模態大模型技術的突破,我們將很快看到電商領域發生一場革命。





