擊這里在線咨詢客服")
【ITBEAR科技資訊】1月26日消息,阿里云今日宣布在多模態(tài)大模型研究領(lǐng)域取得顯著進(jìn)展。據(jù)透露,通義千問(wèn)的視覺理解模型Qwen-VL已經(jīng)進(jìn)行了重要升級(jí),繼之前的Plus版本后,再次推出了更為強(qiáng)大的Max版本。這一升級(jí)版模型在視覺推理和中文理解方面展現(xiàn)出了更為出色的能力,可以識(shí)別圖片中的人物、回答問(wèn)題、進(jìn)行創(chuàng)作以及編寫代碼。在多個(gè)權(quán)威測(cè)評(píng)中,Qwen-VL-Plus和Qwen-VL-Max均取得了優(yōu)異成績(jī),整體性能與GPT-4V和Gemini Ultra不相上下。
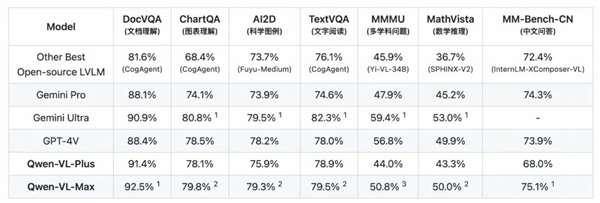
在各項(xiàng)評(píng)估中,Qwen-VL的兩個(gè)升級(jí)版模型表現(xiàn)搶眼。它們?cè)贛MMU、MathVista等測(cè)評(píng)中遠(yuǎn)超業(yè)內(nèi)其他開源模型,尤其在文檔分析(DocVQA)和中文圖像相關(guān)任務(wù)(MM-Bench-CN)上,更是超越了GPT-4V,達(dá)到了業(yè)界領(lǐng)先水平。這些模型不僅能夠準(zhǔn)確描述和識(shí)別圖片中的信息,還能根據(jù)圖片內(nèi)容進(jìn)行推理和創(chuàng)作,甚至具備了對(duì)畫面指定區(qū)域進(jìn)行問(wèn)答的視覺定位能力。
在視覺推理方面,Qwen-VL-Plus和Qwen-VL-Max展現(xiàn)出了強(qiáng)大的能力。它們能夠理解流程圖等復(fù)雜形式的圖片,分析復(fù)雜圖標(biāo),并且能夠看圖做題、看圖作文、看圖寫代碼。在圖像文本處理方面,升級(jí)版Qwen-VL的中英文文本識(shí)別能力也得到了顯著提升,支持處理百萬(wàn)像素以上的高清分辨率圖和極端寬高比的圖像,既能完整復(fù)現(xiàn)密集文本,也能從表格和文檔中提取所需信息。
Qwen-VL-Max看圖做題
據(jù)ITBEAR科技資訊了解,多模態(tài)是當(dāng)前大模型領(lǐng)域最具共識(shí)的發(fā)展方向。過(guò)去半年來(lái),OpenAI、谷歌等科技巨頭紛紛推出了自己的多模態(tài)模型。阿里云也在2023年8月發(fā)布了具備圖文理解能力的Qwen-VL模型,并將其開源。該模型在同期表現(xiàn)中遠(yuǎn)超同等規(guī)模的通用模型,展現(xiàn)了強(qiáng)大的實(shí)力。
Qwen-VL-Max復(fù)現(xiàn)密集文本
視覺作為多模態(tài)能力中最重要的模態(tài)之一,占據(jù)了人類感知和認(rèn)知世界信息的80%。通義千問(wèn)的視覺語(yǔ)言模型基于通義千問(wèn)LLM開發(fā),通過(guò)將視覺表示學(xué)習(xí)模型與LLM對(duì)齊,為AI賦予了理解視覺信息的能力。這一創(chuàng)新在大語(yǔ)言模型的基礎(chǔ)上開辟了一扇視覺的“窗”,為AI帶來(lái)了更廣闊的應(yīng)用前景。
與LLM相比,多模態(tài)大模型在應(yīng)用方面擁有更大的想象力。研究者們正在探索將多模態(tài)大模型與自動(dòng)駕駛場(chǎng)景相結(jié)合,為實(shí)現(xiàn)“完全自動(dòng)駕駛”尋找新的技術(shù)路徑。同時(shí),多模態(tài)模型還可以被部署到手機(jī)、機(jī)器人、智能音箱等端側(cè)設(shè)備中,讓智能設(shè)備能夠自動(dòng)理解物理世界的信息。此外,基于多模態(tài)模型開發(fā)的應(yīng)用還可以輔助視力障礙群體的日常生活,為他們提供更多的便利。
目前,Qwen-VL-Plus和Qwen-VL-Max已經(jīng)限時(shí)免費(fèi)開放給用戶使用。用戶可以在通義千問(wèn)的官網(wǎng)和APP上直接體驗(yàn)Max版本模型的能力,也可以通過(guò)阿里云的靈積平臺(tái)(DashScope)調(diào)用模型的API進(jìn)行使用。





