

【新智元導讀】Sora突破之后的突破又來了!語音初創公司ElevenLabs放大招,直接用AI給Sora經典視頻完成了配音。網友驚呼離AI完全生成電影又近了一步。
雖然一些人不想承認,但AI視頻模型Sora的開年王炸,確實給影視行業帶來了顛覆性的影響!

OpenAI Sora各種逼真視頻的生成足以讓人驚掉下巴,有網友卻表示,現在的Sora視頻更像是‘無聲電影’。

如果再給它們配上音效,現實可就真的就不存在了......
就在今天,AI語音克隆初創公司ElevenLabs給經典的Sora演示視頻,完成了絕美的配音。
聽過之后,讓人簡直顱內高潮。
從建筑物到鯊魚無縫切換視頻中,可以聽到小鳥嘰喳,狗在狂吠,不同動物叫聲糅雜在一起,非常空靈。
汽車卯足勁向前行駛的聲音,偶爾還能聽到石子與輪胎的摩擦音。
還有這歡樂喜慶的中國舞龍表演,敲鑼打鼓人聲鼎沸,好不熱鬧。
地鐵在軌道中咔噠咔噠行駛,還伴有空氣被壓縮發出隆~隆~的聲音,讓人有種耳塞的趕腳。
機器人(10.570, 0.03, 0.28%)的專屬配音,直接將賽博風拉滿,聽過后就知道是那種‘熟悉的味道’。
東京街頭上,靚麗的女人提著手提包在路邊行走,高跟鞋噠噠噠與步伐完全吻合。還有那汽車鳴笛,路人說話的聲音體現的淋漓盡致。
驚濤駭浪撞擊著巖石,海鷗在高空中飛翔,叫聲高亢嘹亮。
老奶奶開心地吹滅蠟燭,笑容洋溢在每個人的臉上,片刻美好,只希望時間能夠按下暫停鍵。
三只可愛的金毛在雪地中嬉戲打鬧,興奮地汪汪大叫。
更令人震撼的是,下面這個視頻直接配出了‘紀錄片’的高級感。
在片尾,ElevenLabs表示,以上所有的配音全部由AI生成,沒有一點編輯痕跡。

網友驚呼,‘這簡直離完全由AI生成電影又近了一步’!

堪稱突破后的突破!

需要補充的是,ElevenLabs的配音不是看視頻直接生成的,還是需要prompt之后才能完成。
不過,這種夢幻聯動確實讓人眼前一亮,或許OpenAI的下一步就是進一步擴展多模態能力,將視頻、音頻同時呈現。
到時候,被革命的不僅僅是影視行業,甚至是配音、游戲領域,也要發生翻天覆地的變化!

向量空間中建模,讓LLM理解隱式物理規則
那么,視頻到音頻的精準映射,該如何突破呢?
對此,英偉達高級科學家Jim Fan做了一個比較全面的分析:
為了精確配合視頻內容,配音不僅需要文本信息,視頻像素也至關重要。
若想精確地實現‘視頻-音頻’的無縫匹配,還需要LLM在其潛在空間內理解一些‘隱式的物理原理’。
那么,一個端到端的Transformer需要掌握以下能力,才能正確模擬聲波:
- 確定每個物體的種類、材質和空間位置。
- 識別物體間的復雜互動,比如棍子是敲在木頭、金屬還是鼓面?敲擊的速度如何?
- 辨識場景環境,是餐廳、空間站、黃石國家公園還是日本神社?
- 從模型的內存中提取物體及其環境的典型聲音模式。
- 應用‘軟性’的、已學習的物理規則,組合并調整聲音模式的參數,或者即時創造全新的聲音,類似于游戲引擎中的‘程序化音頻’。
- 對于復雜場景,模型需要根據物體的空間位置,將多條聲音軌道疊加起來。
所有這些能力都不是通過顯式模塊實現的!它們是通過大量時間對齊的視頻和音頻配對,通過梯度下降法學習得來的。
模型的注意力層將利用其權重來實現這些功能,以達到擴散的目標。

目前,我們還沒有創造出如此高質量的‘AI音頻引擎’。
Jim Fan挖出了5年前來自MIT團隊的一項關于‘The Sound of Pixels’的研究,或許從這里可以找到一些靈感。

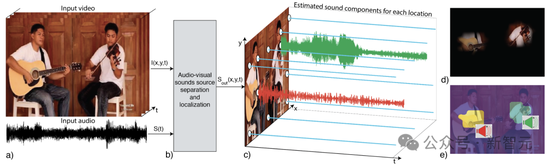
這個項目中,研究人員提出了像素級聲源定位系統PixelPlayer。
通過結合聲音和圖像信息,AI能夠以無監督的方式從圖像或聲音中識別目標、定位圖像中的目標,甚至分離目標視頻中的聲源。
當你給定一個輸入視頻,PixelPlayer可以聯合地將配音分離為目標組件,以及在圖像幀上定位目標組件。
值得一提的是,它允許在視頻的‘每個像素’上定位聲源。

具體來說,研究人員利用了圖像和聲音的自然同時性,來學習圖像聲源定位模型。
PixelPlayer學習了近60個小時的音樂演奏,包括獨奏和二重奏。它以聲音信號作為輸入,并預測和視頻中空間定位對應的聲源信號。
在具體訓練過程中,作者還利用了自然聲音的可加性來生成視頻,其中構成聲源是已知的。與此同時,還通過混合聲源來訓練模型生成聲源。
這僅是視覺-音頻聯合學習(Audio-Visual Learning)研究中的一瞥,過去在這一方向領域的研究也是數不勝數。
比如,在ECCV 2018被接收的Oral論文‘Learning to Separate Object Sounds by Watching Unlabeled Video’,同樣使用了視覺信息指導聲源分離。

比起MIT的那項研究,這篇論文除了在音樂,還在自然聲上進行了實驗。
以往的研究,都將為未來視頻-音頻完成精準映射進一步鋪路。
正如這幾天被人們炒的火熱的Sora模型,背后架構采用的是Diffusion Transformer一樣,正是基于前輩們的成果。
話又說回來,網友發出疑問,‘那得需要多少年,LLM才能完全遵守物理達則中的所有可能參照系’?

別慌!
有沒有可能OpenAI早已接近,甚至是實現AGI,只不過不想讓我們知道?


估值11億刀,前谷歌大佬創AI語音初創公司
前文提到的ElevenLabs,是由前谷歌機器學習工程師Piotr D?bkowski和前Palantir部署策略師Mateusz Staniszewski,在2022年共同創立的一家利用AI實現語音合成與文本轉語音的公司。
這兩位創始人都來自波蘭,他們在看到美國電影不盡人意的配音后,萌生了創建ElevenLabs的想法。
盡管ElevenLabs沒有固定辦公地點并且僅有15名員工,但它卻在2023年6月以約1億美元估值成功籌集到了1900萬美元的 A 輪融資。
到了2024年1月22日,ElevenLabs又在B輪融資中籌集了額外的8000萬美元,使估值達到了11億美元。同時,公司還宣布推出了一系列新產品,包括聲音市場、AI 配音工作室和移動應用等。
自去年1月發布beta版平臺以來,ElevenLabs便受到了創作者們的熱捧。
2023年3月,喜劇演員Drew Carey通過ElevenLabs的聲音克隆工具,在他的廣播節目《Friday Night Freakout》中復刻了自己的聲音。
2023年3月,流媒體自動化服務Super-Hi-Fi攜手ElevenLabs,利用后者的軟件和ChatGPT生成的提示詞,為其虛擬DJ配音,推出了全自動的‘AI Radio’廣播服務。
6月13日,Storytel宣布與ElevenLabs達成獨家合作,后者將專門為Storytel的核心市場量身定制聲音,制作AI敘述的有聲讀物。
在游戲領域,ElevenLabs正與瑞典的Paradox Interactive和英國的Magicave等開發商進行合作。
ElevenLabs的技術還被用于多語言視頻配音,幫助內容創作者準確復制幾乎任何語言的任何口音。此外,明星粉絲也通過ElevenLabs使用他們偶像的聲音創作鼓舞人心的信息。
OpenAI下一次顛覆,又是萬億美元產業?
還記得ChatGPT誕生之后,OpenAI隨后為其‘聯網’,并發布了全新的插件功能。
那些初創公司們緊跟著,上線了一大波插件應用。
沒想到,從3月發布截止到11月,僅僅半年多的時間,一些初創公司卻遭到‘屠殺’。
在首屆開發者大會上,Sam Altman首次公布定制GPTs,以及即將上線的GPT Store。
可以說,基于OpenAI接口構建創業公司,產品忽然就失去了意義。許多初創公司的產品,已經沒有了護城河。
當時有網友便發問,OpenAI入局智能體后,全球十家頭部Agent初創公司接下來該做什么?
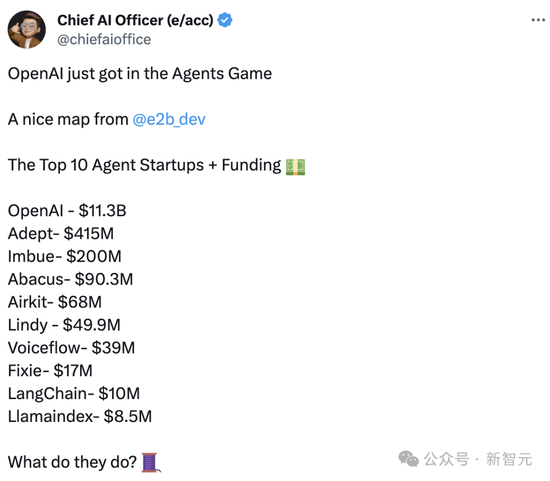
而現在,首個AI視頻模型Sora的橫空出世,已經讓許多影視行業的人,倍感恐慌。
有網友表示,‘Sora雖然有一些不完美之處(可以檢測出來),例如從物理效果可以看出它是人工合成的。但是,它將會革命性地改變許多行業。
想象一下可以生成動態的、個性化的廣告視頻進行精準定位,這將是一個萬億美元的產業’!

對于Sora的應用前景,有望在未來成為視頻制作領域的重要工具。
等OpenAI發布能夠視頻-音頻大模型之后,對于如上專門配音的初創公司ElevenLabs來說,都將是一場‘災難’。
‘我認為大多數人都不能理解,這對不久的將來的生活意味著什么’。

未來,無論是電影、電視劇、廣告,甚至游戲等領域,高質量視頻創作,都將被AI入侵。
在那一天還沒到來之前,想想我們還能做些什么?





