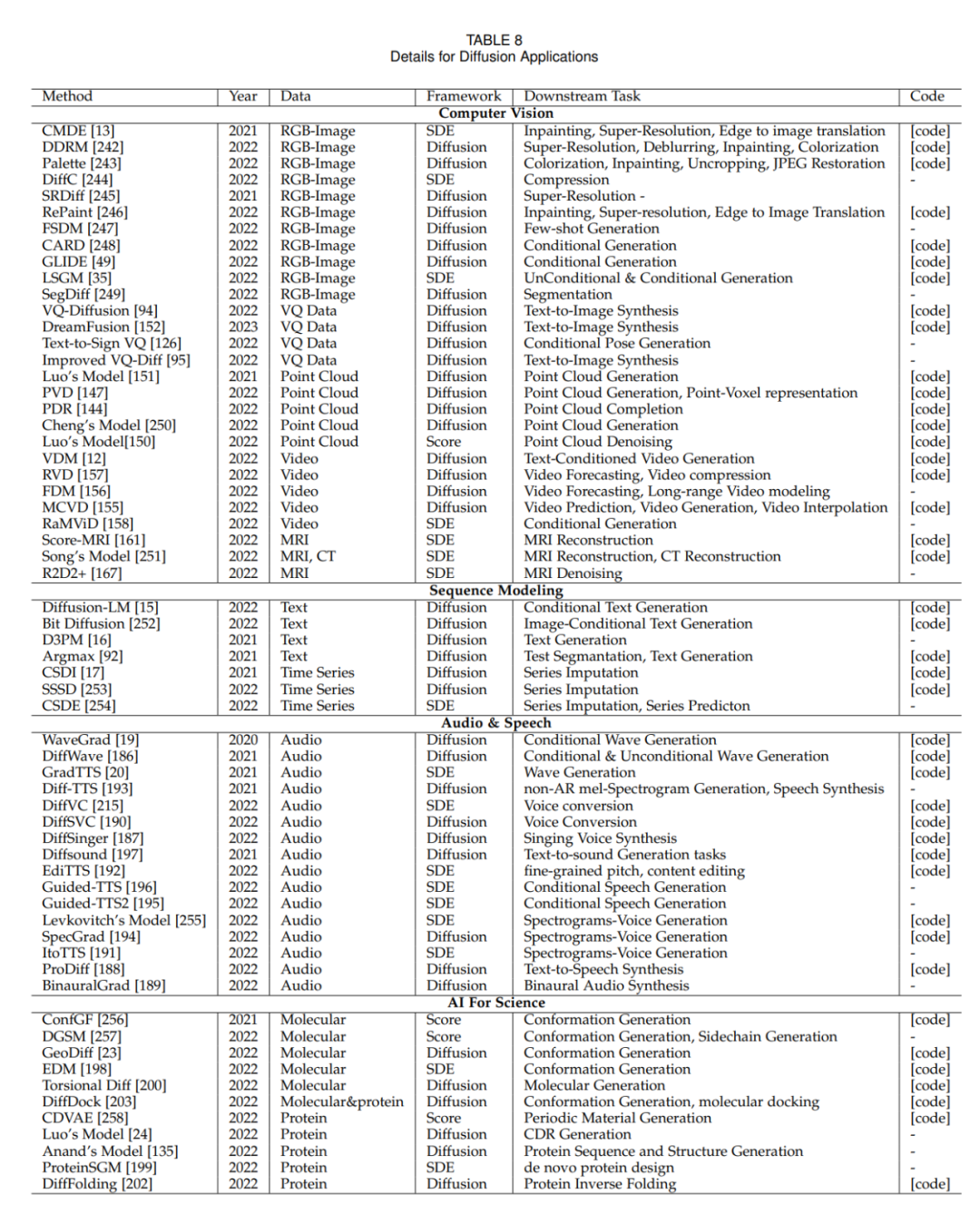
為了使機(jī)器具有人類的想象力,深度生成模型取得了重大進(jìn)展。這些模型能創(chuàng)造逼真的樣本,尤其是擴(kuò)散模型,在多個領(lǐng)域表現(xiàn)出色。擴(kuò)散模型解決了其他模型的限制,如 VAEs 的后驗分布對齊問題、GANs 的不穩(wěn)定性、EBMs 的計算量大和 NFs 的網(wǎng)絡(luò)約束問題。因此,擴(kuò)散模型在計算機(jī)視覺、自然語言處理等方面?zhèn)涫荜P(guān)注。
擴(kuò)散模型由兩個過程組成:前向過程和反向過程。前向過程把數(shù)據(jù)轉(zhuǎn)化為簡單的先驗分布,而反向過程則逆轉(zhuǎn)這一變化,用訓(xùn)練好的神經(jīng)網(wǎng)絡(luò)模擬微分方程來生成數(shù)據(jù)。與其他模型相比,擴(kuò)散模型提供了更穩(wěn)定的訓(xùn)練目標(biāo)和更好的生成效果。
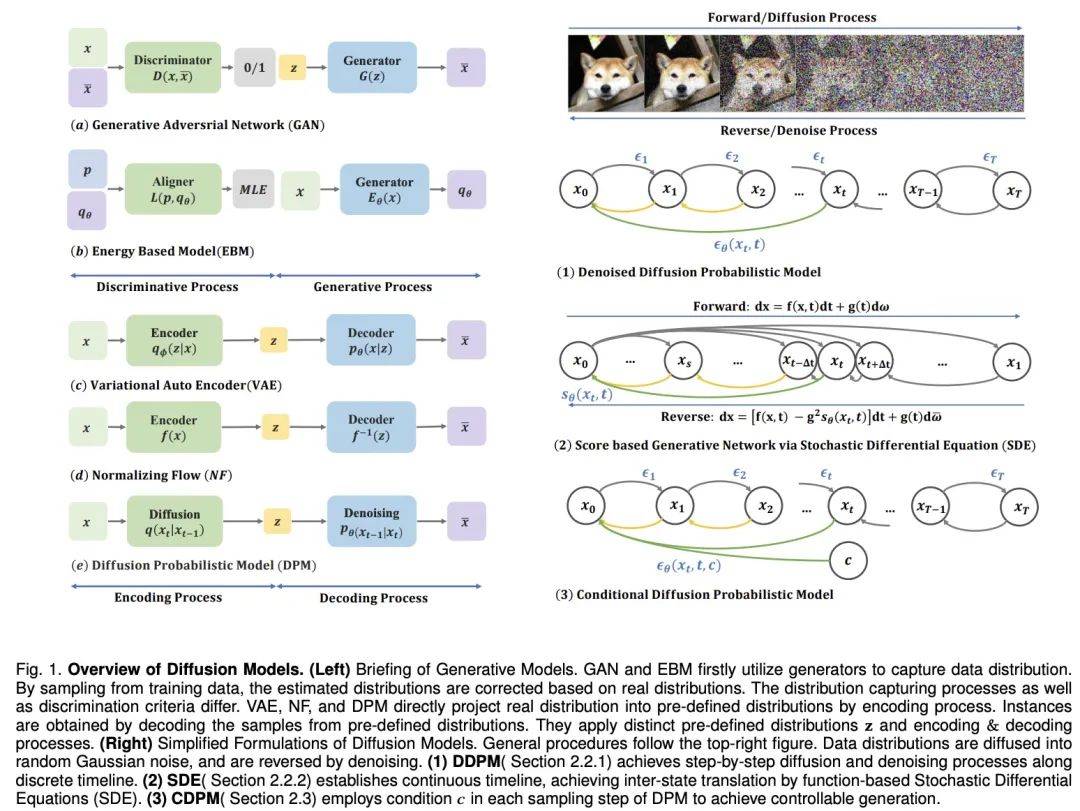
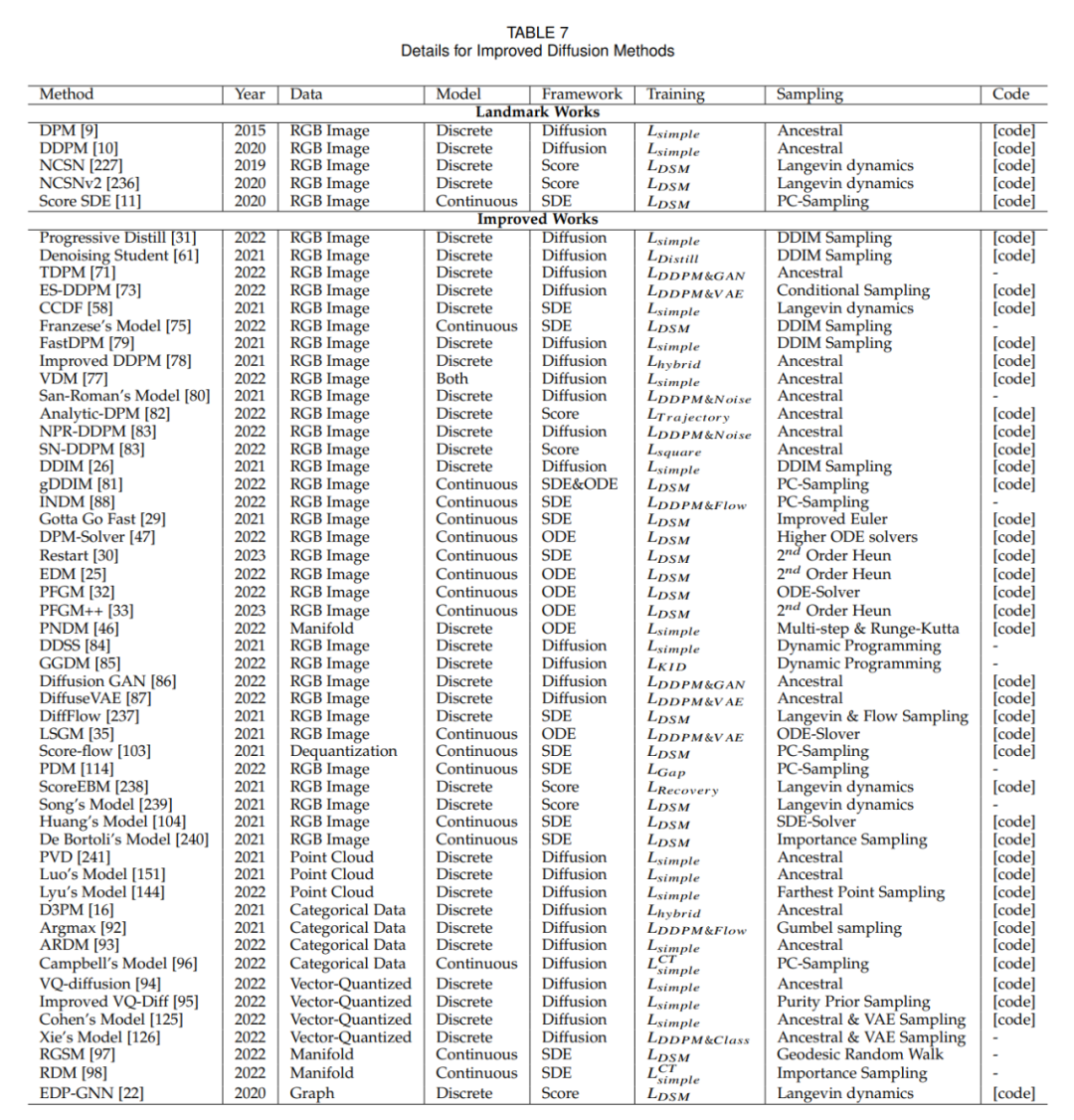
不過,擴(kuò)散模型的采樣過程伴隨反復(fù)推理求值。這一過程面臨著不穩(wěn)定性、高維計算需求和復(fù)雜的似然性優(yōu)化等挑戰(zhàn)。研究者為此提出了多種方案,如改進(jìn) ODE/SDE 解算器和采取模型蒸餾策略來加速采樣,以及新的前向過程來提高穩(wěn)定性和降低維度。
近期,港中文聯(lián)合西湖大學(xué)、MIT、之江實驗室,在 IEEE TKDE 上發(fā)表的題為《A Survey on Generative Diffusion Models》的綜述論文從四個方面討論了擴(kuò)散模型的最新進(jìn)展:采樣加速、過程設(shè)計、似然優(yōu)化和分布橋接。該綜述還深入探討了擴(kuò)散模型在不同應(yīng)用領(lǐng)域的成功,如圖像合成、視頻生成、3D 建模、醫(yī)學(xué)分析和文本生成等。通過這些應(yīng)用案例,展示了擴(kuò)散模型在真實世界中的實用性和潛力。

- 論文地址:https://arxiv.org/pdf/2209.02646.pdf
- 項目地址:https://Github.com/chq1155/A-Survey-on-Generative-Diffusion-Model?tab=readme-ov-file
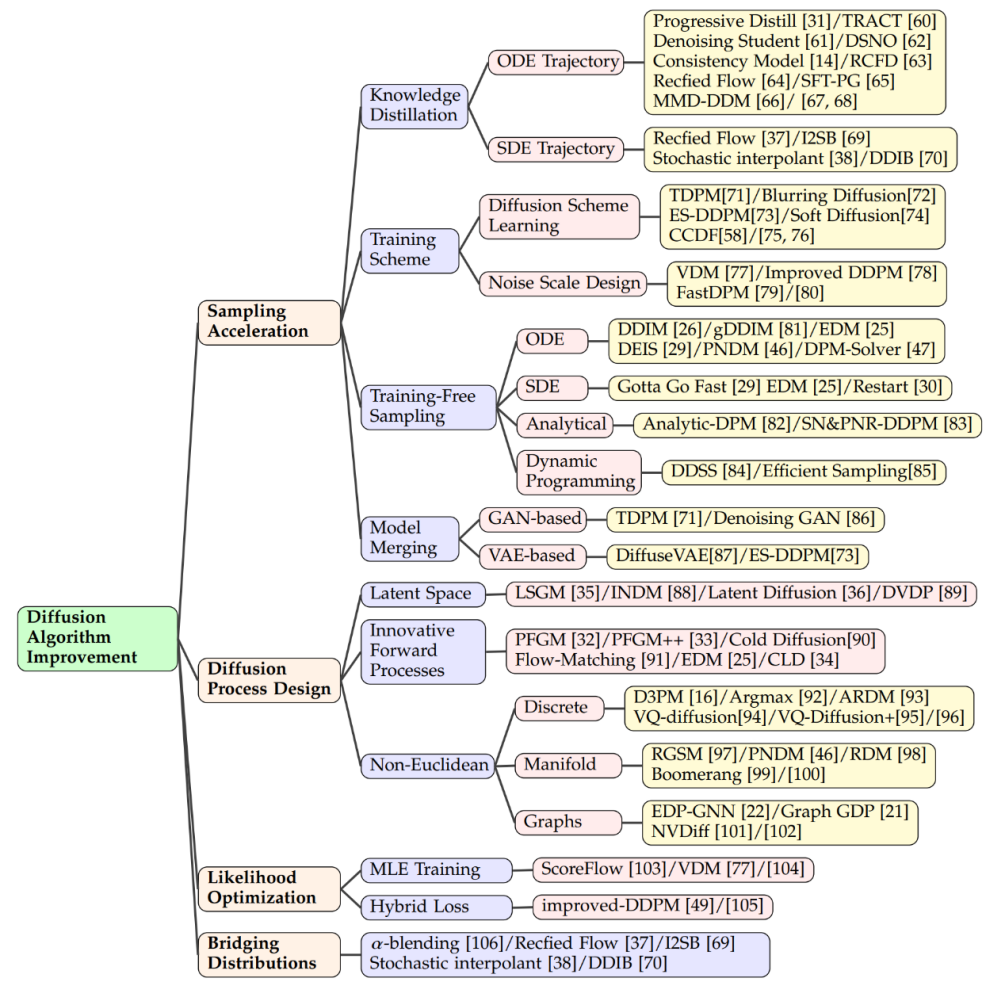
算法改進(jìn)
采樣加速
- 知識蒸餾
在擴(kuò)散模型領(lǐng)域,提高采樣速度的關(guān)鍵技術(shù)之一是知識蒸餾。這個過程涉及從一個大型、復(fù)雜的模型中提取出知識,并將其轉(zhuǎn)移到一個更小、更高效的模型中。例如,通過使用知識蒸餾,我們可以簡化模型的采樣軌跡,使得在每個步驟中都以更高的效率逼近目標(biāo)分布。Salimans 等人采用了一種基于常微分方程(ODE)的方法來優(yōu)化這些軌跡,而其他研究者則發(fā)展了直接從噪聲樣本估計干凈數(shù)據(jù)的技術(shù),從而在時間點 T 上加速了這一過程。
- 訓(xùn)練方式
改進(jìn)訓(xùn)練方式也是提升采樣效率的一種方法。一些研究專注于學(xué)習(xí)新的擴(kuò)散方案,其中數(shù)據(jù)不再是簡單地加入高斯噪聲,而是通過更復(fù)雜的方法映射到潛在空間。這些方法中,有些關(guān)注于優(yōu)化逆向解碼過程,比如調(diào)整編碼的深度,而其他則探索了新的噪聲規(guī)模設(shè)計,使噪聲的加入不再是靜態(tài)的,而是變成了一個可以在訓(xùn)練過程中學(xué)習(xí)的參數(shù)。
- 免訓(xùn)練采樣
除了訓(xùn)練新的模型以提高效率,還有一些技術(shù)致力于加速已經(jīng)預(yù)訓(xùn)練好的擴(kuò)散模型的采樣過程。ODE 加速是其中的一種技術(shù),它利用 ODE 來描述擴(kuò)散過程,從而使得采樣可以更快地進(jìn)行。例如,DDIM 是一種利用 ODE 進(jìn)行采樣的方法,后續(xù)的研究則引入了更高效的 ODE 求解器,如 PNDM 和 EDM,以進(jìn)一步提升采樣速度。
- 結(jié)合其他生成模型
此外,還有研究者提出了解析方法來加速采樣,這些方法試圖找到一個無需迭代就能從噪聲數(shù)據(jù)中直接恢復(fù)干凈數(shù)據(jù)的解析解。這些方法包括 Analytic-DPM 及其改進(jìn)版本 Analytic-DPM++,它們提供了一種快速且精確的采樣策略。
擴(kuò)散過程設(shè)計
- 潛在空間
潛在空間擴(kuò)散模型如 LSGM 和 INDM 結(jié)合了 VAE 或歸一化流模型,通過共用的加權(quán)去噪分?jǐn)?shù)匹配損失來優(yōu)化編解碼器和擴(kuò)散模型,使得 ELBO 或?qū)?shù)似然的優(yōu)化旨在構(gòu)建易于學(xué)習(xí)和生成樣本的潛在空間。例如,Stable Diffusion 首先使用 VAE 學(xué)習(xí)潛在空間,然后訓(xùn)練擴(kuò)散模型以接受文本輸入。DVDP 則在圖像擾動過程中動態(tài)調(diào)整像素空間的正交組件。
- 創(chuàng)新的前向過程
為了提高生成模型的效率和強(qiáng)度,研究人員探索了新的前向過程設(shè)計。泊松場生成模型將數(shù)據(jù)視為電荷,沿電場線將簡單分布引向數(shù)據(jù)分布,與傳統(tǒng)擴(kuò)散模型相比,它提供了更強(qiáng)大的反向采樣。PFGM++ 進(jìn)一步將這一概念納入高維度變量。Dockhorn 等人的臨界阻尼朗之萬擴(kuò)散模型利用哈密頓動力學(xué)中的速度變量簡化了條件速度分布的分?jǐn)?shù)函數(shù)學(xué)習(xí)。
- 非歐幾里得空間
在離散空間數(shù)據(jù)(如文本、分類數(shù)據(jù))的擴(kuò)散模型中,D3PM 定義了離散空間的前向過程。基于這種方法,已有研究擴(kuò)展到語言文本生成、圖分割和無損壓縮等。在多模態(tài)挑戰(zhàn)中,矢量量化數(shù)據(jù)轉(zhuǎn)換為代碼,顯示出卓越的結(jié)果。在黎曼流形中的流形數(shù)據(jù),如機(jī)器人技術(shù)和蛋白質(zhì)建模,要求擴(kuò)散采樣納入黎曼流形。圖神經(jīng)網(wǎng)絡(luò)和擴(kuò)散理論的結(jié)合,如 EDP-GNN 和 GraphGDP,處理圖數(shù)據(jù)來捕捉排列不變性。
似然優(yōu)化
盡管擴(kuò)散模型優(yōu)化了 ELBO,但似然優(yōu)化仍是一個挑戰(zhàn),特別是對于連續(xù)時間擴(kuò)散模型。ScoreFlow 和變分?jǐn)U散模型(VDM)等方法建立了 MLE 訓(xùn)練與 DSM 目標(biāo)的聯(lián)系,Girsanov 定理在此中起到了關(guān)鍵作用。改進(jìn)的去噪擴(kuò)散概率模型(DDPM)提出了一種結(jié)合變分下界和 DSM 的混合學(xué)習(xí)目標(biāo),以及一種簡單的重新參數(shù)化技術(shù)。
分布連接
擴(kuò)散模型在將高斯分布轉(zhuǎn)換為復(fù)雜分布時表現(xiàn)出色,但在連接任意分布時存在挑戰(zhàn)。α- 混合方法通過迭代混合和解混來創(chuàng)建確定性橋梁。矯正流加入額外步驟來矯正橋梁路徑。另一種方法是通過 ODE 實現(xiàn)兩個分布之間的連接,而薛定諤橋或高斯分布作為中間連接點的方法也在研究之中。
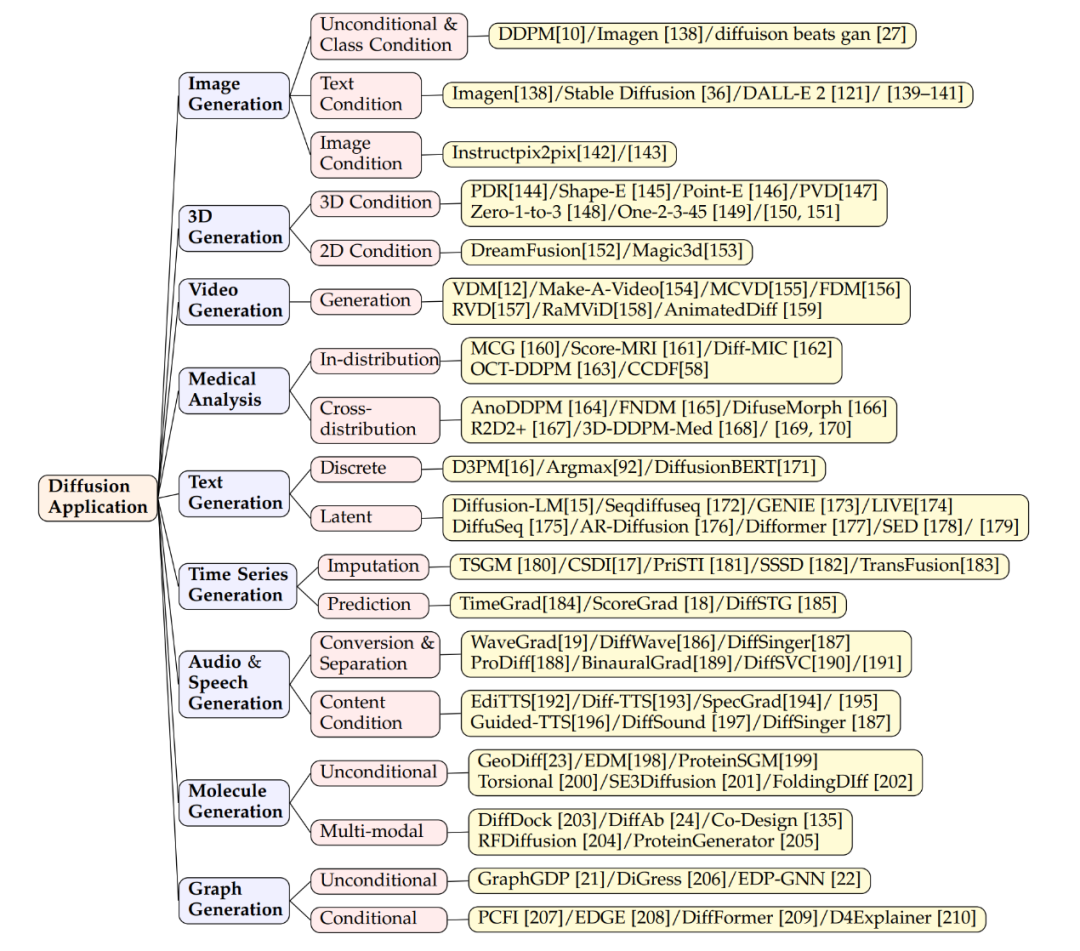
應(yīng)用領(lǐng)域
圖片生成
擴(kuò)散模型在圖像生成中非常成功,不僅能生成普通圖像,還能完成復(fù)雜任務(wù),比如把文本轉(zhuǎn)換成圖像。模型如 Imagen、Stable Diffusion 和 DALL-E 2 在這方面展示了高超技術(shù)。它們使用擴(kuò)散模型結(jié)構(gòu),結(jié)合跨注意力層的技術(shù),把文本信息整合進(jìn)生成圖像。除了生成新圖像,這些模型還能編輯圖像而不需再訓(xùn)練。編輯是通過調(diào)整跨注意力層(鍵、值、注意力矩陣)實現(xiàn)的。比如,通過調(diào)整特征圖改變圖像元素或引入新文本嵌入加入新概念。有研究確保模型生成時能關(guān)注文本的所有關(guān)鍵詞,以確保圖像準(zhǔn)確反映描述。擴(kuò)散模型還能處理基于圖像的條件輸入,比如源圖像、深度圖或人體骨架等,通過編碼并整合這些特征來引導(dǎo)圖像生成。一些研究把源圖像編碼特征加入模型開始層,實現(xiàn)圖像到圖像編輯,也適用于深度圖、邊緣檢測或骨架作為條件的場景。
3D 生成
在 3D 生成方面,通過擴(kuò)散模型的方法主要有兩種。第一種是直接在 3D 數(shù)據(jù)上訓(xùn)練模型,這些模型已被有效應(yīng)用在多種 3D 表示形式,如 NeRF、點云或體素等。例如,研究者們已經(jīng)展示了如何直接生成 3D 對象的點云。為了提高采樣的效率,一些研究引入了混合點 - 體素表示,或者將圖像合成作為點云生成的額外條件。另一方面,有研究使用擴(kuò)散模型來處理 3D 對象的 NeRF 表示,并通過訓(xùn)練視角條件擴(kuò)散模型來合成新穎視圖,優(yōu)化 NeRF 表示。第二種方法強(qiáng)調(diào)使用 2D 擴(kuò)散模型的先驗知識來生成 3D 內(nèi)容。比如,Dreamfusion 項目使用得分蒸餾采樣目標(biāo),從預(yù)訓(xùn)練的文本到圖像模型中提取出 NeRF,并通過梯度下降優(yōu)化過程來實現(xiàn)低損失的渲染圖像。這一過程也被進(jìn)一步擴(kuò)展,以加快生成速度。
視頻生成
視頻擴(kuò)散模型是對 2D 圖像擴(kuò)散模型的擴(kuò)展,它們通過添加時間維度來生成視頻序列。這種方法的基本思想是在現(xiàn)有的 2D 結(jié)構(gòu)中添加時間層,以此來模擬視頻幀之間的連續(xù)性和依賴關(guān)系。相關(guān)的工作展示了如何利用視頻擴(kuò)散模型來生成動態(tài)內(nèi)容,例如 Make-A-Video、AnimatedDiff 等模型。更具體地,RaMViD 模型使用 3D 卷積神經(jīng)網(wǎng)絡(luò)擴(kuò)展圖像擴(kuò)散模型到視頻,并開發(fā)了一系列視頻特定的條件技術(shù)。
醫(yī)學(xué)分析
擴(kuò)散模型幫助解決了醫(yī)學(xué)分析中獲取高質(zhì)量數(shù)據(jù)集的挑戰(zhàn),尤其在醫(yī)學(xué)成像方面表現(xiàn)出色。這些模型憑借其強(qiáng)大的圖像捕捉能力,在提升圖像的分辨率、進(jìn)行分類和噪聲處理方面取得了成功。例如,Score-MRI 和 Diff-MIC 使用先進(jìn)的技術(shù)加速 MRI 圖像的重建和實現(xiàn)更精確的分類。MCG 在 CT 圖像超分辨率中采用流形校正,提高了重建速度和準(zhǔn)確性。在生成稀有圖像方面,通過特定技術(shù),模型能在不同類型的圖像間進(jìn)行轉(zhuǎn)換。例如,F(xiàn)NDM 和 DiffuseMorph 分別用于腦部異常檢測和 MR 圖像配準(zhǔn)。一些新方法通過少量高質(zhì)量樣本合成訓(xùn)練數(shù)據(jù)集,如一個使用 31,740 個樣本的模型合成了一個包含 100,000 個實例的數(shù)據(jù)集,取得了非常低的 FID 得分。
文本生成
文本生成技術(shù)是連接人類和 AI 的重要橋梁,能制造流暢自然的語言。自回歸語言模型雖然生成連貫性強(qiáng)的文本但速度慢,而擴(kuò)散模型能夠快速生成文本但連貫性相對較弱。兩種主流的方法是離散生成和潛在生成。離散生成依賴于先進(jìn)技術(shù)和預(yù)訓(xùn)練模型;例如,D3PM 和 Argmax 視詞匯為分類向量,而 DiffusionBERT 將擴(kuò)散模型與語言模型結(jié)合提升文本生成。潛在生成則在令牌的潛在空間中生成文本,例如,LM-Diffusion 和 GENIE 等模型在各種任務(wù)中表現(xiàn)出色,顯示了擴(kuò)散模型在文本生成中的潛力。擴(kuò)散模型預(yù)計將在自然語言處理中提升性能,與大型語言模型結(jié)合,并支持跨模態(tài)生成。
時間序列生成
時間序列數(shù)據(jù)的建模是在金融、氣候科學(xué)、醫(yī)療等領(lǐng)域中進(jìn)行預(yù)測和分析的關(guān)鍵技術(shù)。擴(kuò)散模型由于其能夠生成高質(zhì)量的數(shù)據(jù)樣本,已經(jīng)被用于時間序列數(shù)據(jù)的生成。在這個領(lǐng)域,擴(kuò)散模型通常被設(shè)計為考慮時間序列數(shù)據(jù)的時序依賴性和周期性。例如,CSDI(Conditional Sequence Diffusion Interpolation)是一種模型,它利用了雙向卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)來生成或插補(bǔ)時間序列數(shù)據(jù)點。它在醫(yī)療數(shù)據(jù)生成和環(huán)境數(shù)據(jù)生成方面表現(xiàn)出色。其他模型如 DiffSTG 和 TimeGrad 通過結(jié)合時空卷積網(wǎng)絡(luò),能夠更好地捕捉時間序列的動態(tài)特性,并生成更加真實的時間序列樣本。這些模型通過自我條件指導(dǎo)的方式,逐漸從高斯噪聲中恢復(fù)出有意義的時間序列數(shù)據(jù)。
音頻生成
音頻生成涉及到從語音合成到音樂生成等多個應(yīng)用場景。由于音頻數(shù)據(jù)通常包含復(fù)雜的時間結(jié)構(gòu)和豐富的頻譜信息,擴(kuò)散模型在此領(lǐng)域同樣表現(xiàn)出潛能。例如,WaveGrad 和 DiffSinger 是兩種擴(kuò)散模型,它們利用條件生成過程來產(chǎn)生高質(zhì)量的音頻波形。WaveGrad 使用 Mel 頻譜作為條件輸入,而 DiffSinger 則在這個基礎(chǔ)上添加了額外的音樂信息,如音高和節(jié)奏,從而提供更精細(xì)的風(fēng)格控制。文本到語音(TTS)的應(yīng)用中,Guided-TTS 和 Diff-TTS 將文本編碼器和聲學(xué)分類器的概念結(jié)合起來,生成既符合文本內(nèi)容又遵循特定聲音風(fēng)格的語音。Guide-TTS2 進(jìn)一步展現(xiàn)了如何在沒有明確分類器的情況下生成語音,通過模型自身學(xué)習(xí)到的特征引導(dǎo)聲音生成。
分子設(shè)計
在藥物設(shè)計、材料科學(xué)和化學(xué)生物學(xué)等領(lǐng)域,分子設(shè)計是發(fā)現(xiàn)和合成新化合物的重要環(huán)節(jié)。擴(kuò)散模型在這里作為一種強(qiáng)大的工具,能夠高效探索化學(xué)空間,生成具有特定性質(zhì)的分子。在無條件的分子生成中,擴(kuò)散模型不依賴于任何先驗知識,自發(fā)地生成分子結(jié)構(gòu)。而在跨模態(tài)生成中,模型可能會結(jié)合特定的功能條件,例如藥效或目標(biāo)蛋白的結(jié)合傾向,來生成具有所需性質(zhì)的分子。基于序列的方法可能會考慮蛋白質(zhì)序列來引導(dǎo)分子的生成,而基于結(jié)構(gòu)的方法則可能使用蛋白質(zhì)的三維結(jié)構(gòu)信息。這樣的結(jié)構(gòu)信息可以在分子對接或者抗體設(shè)計中被用作先驗知識,從而提高生成分子的質(zhì)量。
圖生成
使用擴(kuò)散模型生成圖,旨在更好地理解和模擬現(xiàn)實世界的網(wǎng)絡(luò)結(jié)構(gòu)和傳播過程。這種方法幫助研究人員挖掘復(fù)雜系統(tǒng)中的模式和相互作用,預(yù)測可能的結(jié)果。應(yīng)用包括社交網(wǎng)絡(luò)、生物網(wǎng)絡(luò)分析以及圖數(shù)據(jù)集的創(chuàng)建。傳統(tǒng)方法依賴于生成鄰接矩陣或節(jié)點特征,但這些方法可擴(kuò)展性差,實用性有限。因此,現(xiàn)代圖生成技術(shù)更傾向于根據(jù)特定條件生成圖。例如,PCFI 模型使用圖的一部分特征和最短路徑預(yù)測來引導(dǎo)生成過程;EDGE 和 DiffFormer 分別用節(jié)點度和能量約束來優(yōu)化生成;D4Explainer 則通過結(jié)合分布和反事實損失來探索圖的不同可能性。這些方法提高了圖生成的精確度和實用性。
結(jié)論與展望
數(shù)據(jù)限制下的挑戰(zhàn)
除了推理速度低外,擴(kuò)散模型在從低質(zhì)量數(shù)據(jù)中辨識模式和規(guī)律時也常常遇到困難,導(dǎo)致它們無法泛化到新的場景或數(shù)據(jù)集。此外,處理大規(guī)模數(shù)據(jù)集時也會出現(xiàn)計算上的挑戰(zhàn),如延長的訓(xùn)練時間、過度的內(nèi)存使用,或者無法收斂到期望的狀態(tài),從而限制了模型的規(guī)模和復(fù)雜性。更重要的是,有偏差或不均勻的數(shù)據(jù)采樣會限制模型生成適應(yīng)不同領(lǐng)域或人群的輸出的能力。
可控的基于分布的生成
提高模型理解和生成特定分布內(nèi)樣本的能力對于在有限數(shù)據(jù)情況下實現(xiàn)更好的泛化至關(guān)重要。通過專注于識別數(shù)據(jù)中的模式和相關(guān)性,模型可以生成與訓(xùn)練數(shù)據(jù)高度匹配并滿足特定要求的樣本。這需要有效的數(shù)據(jù)采樣、利用技術(shù)以及優(yōu)化模型參數(shù)和結(jié)構(gòu)。最終,這種增強(qiáng)的理解能力允許更加控制和精確的生成,從而改善泛化性能。
利用大型語言模型的高級多模態(tài)生成
擴(kuò)散模型的未來發(fā)展方向涉及通過整合大型語言模型(LLMs)來推進(jìn)多模態(tài)生成。這種整合使模型能夠生成包含文本、圖像和其他模態(tài)組合的輸出。通過納入 LLMs,模型對不同模態(tài)間相互作用的理解得到增強(qiáng),生成的輸出更加多樣化和真實。此外,LLMs 顯著提高了基于提示的生成效率,通過有效利用文本與其他模態(tài)之間的聯(lián)系。另外,LLMs 作為催化劑,提高了擴(kuò)散模型的生成能力,擴(kuò)大了它可以生成模態(tài)的領(lǐng)域范圍。
與機(jī)器學(xué)習(xí)領(lǐng)域的整合
將擴(kuò)散模型與傳統(tǒng)的機(jī)器學(xué)習(xí)理論結(jié)合,為提高各種任務(wù)的性能提供了新的機(jī)會。半監(jiān)督學(xué)習(xí)在解決擴(kuò)散模型的固有挑戰(zhàn),例如泛化問題,以及在數(shù)據(jù)有限的情況下實現(xiàn)有效的條件生成方面特別有價值。通過利用未標(biāo)記數(shù)據(jù),它加強(qiáng)了擴(kuò)散模型的泛化能力,并在特定條件下生成樣本時實現(xiàn)了理想的性能。
此外,強(qiáng)化學(xué)習(xí)通過使用精調(diào)算法,在模型的采樣過程中提供針對性的指導(dǎo),起著至關(guān)重要的作用。這種指導(dǎo)確保了專注的探索并促進(jìn)了受控生成。另外,通過整合額外的反饋,豐富了強(qiáng)化學(xué)習(xí),從而改善了模型的可控條件生成能力。
算法改進(jìn)方法(附錄)
領(lǐng)域應(yīng)用方法(附錄)