
來源 機器之心
至此已成藝術的 Sora,是從哪條技術路線發(fā)展出來的?
最近幾天,據(jù)說全世界的風投機構(gòu)開會都在大談 Sora。自去年初 ChatGPT 引發(fā)全科技領域軍備競賽之后,已經(jīng)沒有人愿意在新的 AI 生成視頻賽道上落后了。
在這個問題上,人們早有預判,但也始料未及:AI 生成視頻,是繼文本生成、圖像生成以后技術持續(xù)發(fā)展的方向,此前也有不少科技公司搶跑推出自己的視頻生成技術。
不過當 OpenAI 出手發(fā)布 Sora 之后,我們卻立即有了‘發(fā)現(xiàn)新世界(6.080, -0.04, -0.65%)’的感覺 —— 效果和之前的技術相比高出了幾個檔次。

Sora 生成的視頻,美國西部的淘金時代。感覺加上個解說和背景音樂就可以直接用在專題片里了。
在 Sora 及其技術報告推出后,我們看到了長達 60 秒,高清晰度且畫面可控、能多角度切換的高水平效果。在背后的技術上,研究人員訓練了一個基于 Diffusion Transformer(DiT)思路的新模型,其中的 Transformer 架構(gòu)利用對視頻和圖像潛在代碼的時空 patch 進行操作。
正如華為諾亞方舟實驗室首席科學家劉群博士所言,Sora 展現(xiàn)了生成式模型的潛力(特別是多模態(tài)生成方面)顯然還很大。加入預測模塊是正確的方向。至于未來發(fā)展,還有很多需要我們探索,現(xiàn)在還沒有像 Transformer 之于 NLP 領域那樣的統(tǒng)一方法。
想要探求未來的路怎么走,我們或許可以先思考一下之前的路是怎么走過的。那么,Sora 是如何被 OpenAI 發(fā)掘出來的?
從 OpenAI 的技術報告末尾可知,相比去年 GPT-4 長篇幅的作者名單,Sora 的作者團隊更簡潔一些,需要點明的僅有 13 位成員:
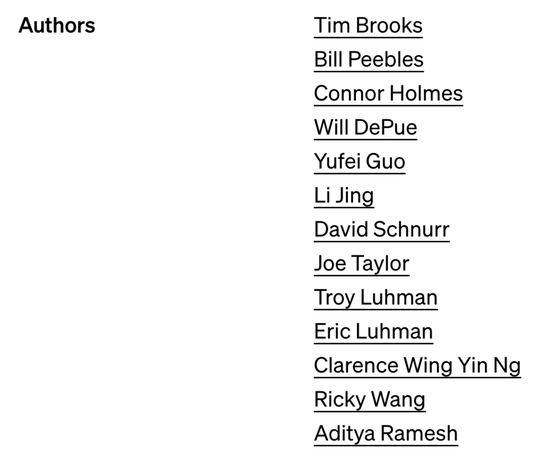
這些參與者中,已知的核心成員包括研發(fā)負責人 Tim Brooks、William Peebles、系統(tǒng)負責人 Connor Holmes 等。這些成員的信息也成為了眾人關注的焦點。
比如,Sora 的共同領導者 Tim Brooks,博士畢業(yè)于 UC Berkeley 的‘伯克利人工智能研究所’BAIR,導師為 Alyosha Efros。

在博士就讀期間,他曾提出了 InstructPix2Pix,他還曾在谷歌從事為 Pixel 手機攝像頭提供 AI 算法的工作,并在英偉達研究過視頻生成模型。
另一位共同領導者 William (Bill) Peebles 也來自于 UC Berkeley,他在 2023 年剛剛獲得博士學位,同樣也是 Alyosha Efros 的學生。在本科時,Peebles 就讀于麻省理工,師從 Antonio Torralba。

值得注意的是,Peebles 等人的一篇論文被認為是這次 Sora 背后的重要技術基礎之一。
論文《Scalable diffusion models with transformers》,一看名字就和 Sora 的理念很有關聯(lián),該論文入選了計算機視覺頂會 ICCV 2023。

論文鏈接:https://arxiv.org/abs/2212.09748
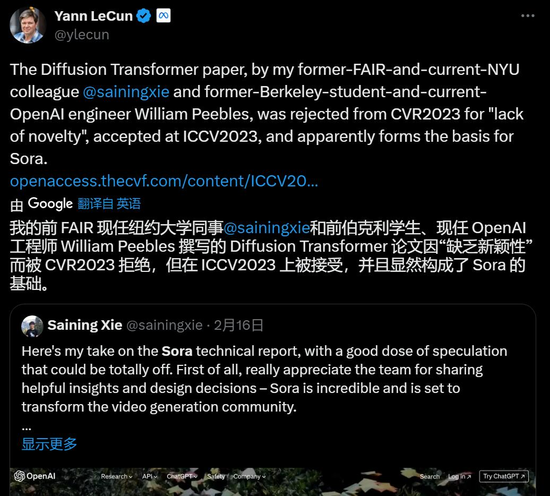
不過,這項研究在發(fā)表的過程還遇到了一些坎坷。上周五 Sora 發(fā)布時,圖靈獎獲得者、Meta 首席科學家 Yann LeCun 第一時間發(fā)推表示:該研究是我的同事謝賽寧和前學生 William Peebles 的貢獻,不過因為‘缺乏創(chuàng)新’,先被 CVPR 2023 拒絕,后來被 ICCV 2023 接收。
具體來說,這篇論文提出了一種基于 transformer 架構(gòu)的新型擴散模型即 DiT。在該研究中,研究者訓練了潛在擴散模型,用對潛在 patch 進行操作的 Transformer 替換常用的 U.NET 主干網(wǎng)絡。他們通過以 Gflops 衡量的前向傳遞復雜度來分析擴散 Transformer (DiT) 的可擴展性。
研究者發(fā)現(xiàn),通過增加 Transformer 深度 / 寬度或增加輸入 token 數(shù)量,具有較高 Gflops 的 DiT 始終具有較低的 FID。除了良好的可擴展性之外,DiT-XL/2 模型在 class-conditional ImageNet 512×512 和 256×256 基準上的性能優(yōu)于所有先前的擴散模型,在后者上實現(xiàn)了 2.27 的 FID SOTA 數(shù)據(jù)。
目前這篇論文的引用量僅有 191。同時可以看到,William (Bill) Peebles 所有研究中引用量最高的是一篇名為《GAN 無法生成什么》的論文:
當然,論文的作者之一,前 FAIR 研究科學家、現(xiàn)紐約大學助理教授謝賽寧否認了自己與 Sora 的直接關系。畢竟 Meta 與 OpenAI 互為競爭對手。
Sora 成功的背后,還有哪些重要技術?
除此之外,Sora 的成功,還有一系列近期業(yè)界、學界的計算機視覺、自然語言處理的技術進展作為支撐。
簡單瀏覽一遍參考文獻清單,我們發(fā)現(xiàn),這些研究出自谷歌、Meta、微軟、斯坦福、MIT、UC 伯克利、Runway 等多個機構(gòu),其中不乏華人學者的成果。
歸根結(jié)底,Sora 今天的成就源自于整個 AI 社區(qū)多年來的求索。

從 32 篇參考文獻中,我們選擇了幾篇展開介紹:
Ha, David, and Jürgen Schmidhuber. “World models.” arXiv preprint arXiv:1803.10122 (2018).

-
論文標題:World Models
-
作者:David Ha、Jurgen Schmidhuber
-
機構(gòu):谷歌大腦、NNAISENSE(Schmidhuber 創(chuàng)立的公司)、Swiss AI Lab
-
論文鏈接:https://arxiv.org/pdf/1803.10122.pdf
這是一篇六年前的論文,探索的主題是為強化學習環(huán)境建立生成神經(jīng)網(wǎng)絡模型。世界模型可以在無監(jiān)督的情況下快速訓練,以學習環(huán)境的壓縮空間和時間表示。通過使用從世界模型中提取的特征作為代理的輸入,研究者發(fā)現(xiàn)能夠訓練出非常緊湊和簡單的策略,從而解決所需的任務,甚至可以完全在由世界模型生成的幻夢中訓練代理,并將該策略移植回實際環(huán)境中。
機器之心報道:《模擬世界的模型:谷歌大腦與 Jürgen Schmidhuber 提出‘人工智能夢境’》
Yan, Wilson, et al. “Videogpt: Video generation using vq-vae and transformers.” arXiv preprint arXiv:2104.10157 (2021).

-
論文標題:VideoGPT: Video Generation using VQ-VAE and Transformers
-
作者:Wilson Yan、Yunzhi Zhang、Pieter Abbeel、Aravind Srinivas
-
機構(gòu):UC 伯克利
-
論文鏈接:https://arxiv.org/pdf/2104.10157.pdf
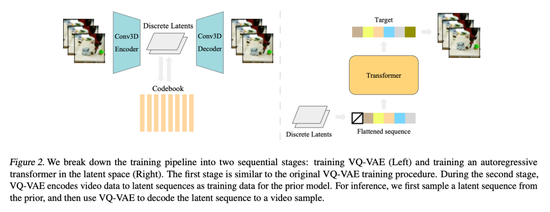
這篇論文提出的 VideoGPT 可用于擴展基于似然的生成對自然視頻進行建模。Video-GPT 將通常用于圖像生成的 VQ-VAE 和 Transformer 模型以最小的修改改編到視頻生成領域,研究者利用 VQVAE 通過采用 3D 卷積和軸向自注意力學習降采樣的原始視頻離散潛在表示,然后使用簡單的類似 GPT 的架構(gòu)進行自回歸,使用時空建模離散潛在位置編碼。VideoGPT 結(jié)構(gòu)下圖:
Wu, Chenfei, et al. “Nüwa: Visual synthesis pre-training for neural visual world creation.” European conference on computer vision. Cham: Springer Nature Switzerland, 2022.

-
論文標題:NÜWA: Visual Synthesis Pre-training for Neural visUal World creAtion
-
作者:Chenfei Wu、Jian Liang、Lei Ji、Fan Yang、Yuejian Fang、Daxin Jiang、Nan Duan
-
機構(gòu):微軟亞洲研究院、北京大學
-
論文鏈接:https://arxiv.org/pdf/2111.12417.pdf
相比于此前只能分別處理圖像和視頻、專注于生成其中一種的多模態(tài)模型,NÜWA 是一個統(tǒng)一的多模態(tài)預訓練模型,在 8 種包含圖像和視頻處理的下游視覺任務上具有出色的合成效果。
為了同時覆蓋語言、圖像和視頻的不同場景,NÜWA 采用了 3D Transformer 編碼器 - 解碼器框架,它不僅可以處理作為三維數(shù)據(jù)的視頻,還可以分別用于處理一維和二維數(shù)據(jù)的文本和圖像。
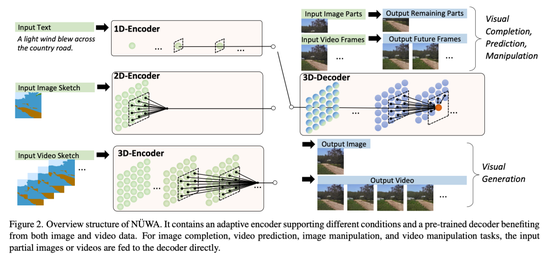
該框架還包含一種 3D Nearby Attention (3DNA) 機制,以考慮空間和時間上的局部特征。3DNA 不僅降低了計算復雜度,還提高了生成結(jié)果的視覺質(zhì)量。與幾個強大的基線相比,NÜWA 在文本到圖像生成、文本到視頻生成、視頻預測等方面都得到了 SOTA 結(jié)果,還顯示出驚人的零樣本學習能力。
機器之心報道:《AI 版‘女媧’來了!文字生成圖像、視頻,8 類任務一個模型搞定》
He, Kaiming, et al. “Masked autoencoders are scalable vision learners.” Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022.

-
論文標題:Masked autoencoders are scalable vision learners
-
作者:Kaiming He、Xinlei Chen、Saining Xie、Yanghao Li、Piotr Dollar、Ross Girshick
-
機構(gòu):Meta
-
論文鏈接:https://arxiv.org/abs/2111.06377
這篇論文展示了一種被稱為掩蔽自編碼器(masked autoencoders,MAE)的新方法,可以用作計算機視覺的可擴展自監(jiān)督學習器。MAE 的方法很簡單:掩蔽輸入圖像的隨機區(qū)塊并重建丟失的像素。它基于兩個核心理念:研究人員開發(fā)了一個非對稱編碼器 - 解碼器架構(gòu),其中一個編碼器只對可見的 patch 子集進行操作(沒有掩蔽 token),另一個簡單解碼器可以從潛在表征和掩蔽 token 重建原始圖像。研究人員進一步發(fā)現(xiàn),掩蔽大部分輸入圖像(例如 75%)會產(chǎn)生重要且有意義的自監(jiān)督任務。結(jié)合這兩種設計,就能高效地訓練大型模型:提升訓練速度至 3 倍或更多,并提高準確性。
用 MAE 做 pre-training 只需 ImageNet-1k 就能達到超過 87% 的 top 1 準確度,超過了所有在 ImageNet-21k pre-training 的 ViT 變體模型。從方法上,MAE 選擇直接重建原圖的元素,而且證明了其可行性,改變了人們的認知,又幾乎可以覆蓋 CV 里所有的識別類任務,開啟了一個新的方向。
具有良好擴展性的簡單算法是深度學習的核心。在 NLP 中,簡單的自監(jiān)督學習方法(如 BERT)可以從指數(shù)級增大的模型中獲益。在計算機視覺中,盡管自監(jiān)督學習取得了進展,但實際的預訓練范式仍是監(jiān)督學習。在 MAE 研究中,研究人員在 ImageNet 和遷移學習中觀察到自編碼器 —— 一種類似于 NLP 技術的簡單自監(jiān)督方法 —— 提供了可擴展的前景。視覺中的自監(jiān)督學習可能會因此走上與 NLP 類似的軌跡。
機器之心報道:《大道至簡,何愷明新論文火了:Masked Autoencoders 讓計算機視覺通向大模型》
Rombach, Robin, et al. “High-resolution image synthesis with latent diffusion models.” Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022

-
論文標題:High-resolution image synthesis with latent diffusion models
-
作者:Robin Rombach、Andreas Blattmann、Dominik Lorenz、Patrick Esser、Bjorn Ommer
-
機構(gòu):慕尼黑大學、Runway
-
論文鏈接:https://arxiv.org/pdf/2112.10752.pdf
基于這篇論文的成果,Stable Diffusion 正式面世,開啟了在消費級 GPU 上運行文本轉(zhuǎn)圖像模型的時代。
該研究試圖利用擴散模型實現(xiàn)文字轉(zhuǎn)圖像。盡管擴散模型允許通過對相應的損失項進行欠采樣(undersampling)來忽略感知上不相關的細節(jié),但它們?nèi)匀恍枰谙袼乜臻g中進行昂貴的函數(shù)評估,這會導致對計算時間和能源資源的巨大需求。該研究通過將壓縮與生成學習階段顯式分離來規(guī)避這個問題,最終降低了訓練擴散模型對高分辨率圖像合成的計算需求。
機器之心報道:《消費級 GPU 可用,文本轉(zhuǎn)圖像開源新模型生成宇宙變遷大片》
Gupta, Agrim, et al. “Photorealistic video generation with diffusion models.” arXiv preprint arXiv:2312.06662 (2023).

-
論文標題:Photorealistic Video Generation with Diffusion Models
-
作者:李飛飛等
-
機構(gòu):斯坦福大學、谷歌研究院、佐治亞理工學院
-
論文鏈接:https://arxiv.org/pdf/2312.06662.pdf
在 Sora 之前,一項視頻生成研究收獲了大量贊譽:Window Attention Latent Transformer,即窗口注意力隱 Transformer,簡稱 W.A.L.T。該方法成功地將 Transformer 架構(gòu)整合到了隱視頻擴散模型中,斯坦福大學的李飛飛教授也是該論文的作者之一。
值得注意的是,盡管概念上很簡單,但這項研究首次在公共基準上通過實驗證明 Transformer 在隱視頻擴散中具有卓越的生成質(zhì)量和參數(shù)效率。
這也是 Sora 32 個公開參考文獻中,距離此次發(fā)布最近的一項成果。
機器之心報道:《將 Transformer 用于擴散模型,AI 生成視頻達到照片級真實感》
最后,Meta 研究科學家田淵棟昨天指出, Sora 不直接通過下一幀預測生成視頻的方法值得關注。更多的技術細節(jié),或許還等待 AI 社區(qū)的研究者及從業(yè)者共同探索、揭秘。

在這一方面 Meta 也有很多已公開的研究。不得不說 Sora 推出后,我們雖然沒有 OpenAI 的算力,但還有很多事可以做。





