
時隔三年半,劉若英終于又開演唱會了。
這次還帶來了新歌《縮影》,飽含情感的歌詞加上奶茶溫柔綿長的嗓音,聽得人心里繾綣。
她唱:“那些縮影寫照,能不能代表,我過得好,答案很微妙。”

回首成名后的一路顛簸,歌詞里一字一句皆是她對成長的詰問,輕易便挑起了無數歌迷們的情緒。
這些年的奶茶,遠離世俗繁華,洗盡鉛華,越發變得溫潤醇厚。
她靜靜地唱,我們默默地聽。
可再次聽見熟悉的聲音,依舊紅了眼睛。

她重新出現在大眾視線里,懷舊的網友們紛紛關心起她的這些年。
后來的劉若英,過得還好嗎?
提起劉若英,大眾印象來來去去無非這幾個:溫婉、文藝、低調、得體。
可劉若英并非表面上那般“溫馴”,相反,她總是叛逆得出其不意。
出身于臺北某個名門望族,父母鬧離婚,2歲的她便成了沒人要的“燙手山芋”。

看不下去的祖父母將她接回家中,開始用心培養她成為名門淑女。
說是淑女,又不盡然,畢竟她做過的出格事并不少。
她叛逆,為了音樂夢想遠赴美國加州州立大學深造,家里沒給一分錢。

骨子里還死倔,白天讀書,晚上去家具城賣床墊、端盤子、做家教。
每當她堅持不下去的時候,祖父的話語又在她耳邊響起:完不成學業,你死也要死在那!

她何嘗不知祖父母的用心良苦:生如浮萍,要有立足之本,他們陪不了她太久。
可所有人都在逼她成長,試煉的刀鋒,割得她生疼。
學成歸來后,她去了滾石唱片做助理,和金城武一起掃了三年廁所。

當時娛樂圈多的是豁得出去的人,憑她的性子想出頭,極難。
1995年,張艾嘉拿著《少女小漁》的劇本找到她,問她愿不愿意“一脫成名”?
成名在望,就差一點。

她拒絕了。
她確實不想放棄來之不易的機會,可總有些人,在誘惑面前始終能堅持底線。
最后還是張艾嘉被這個有骨氣的少女折服,敗下陣來,連夜為她修改劇本。
電影播出后,出色的表現讓她獲得第40屆亞太影展最佳女主角。
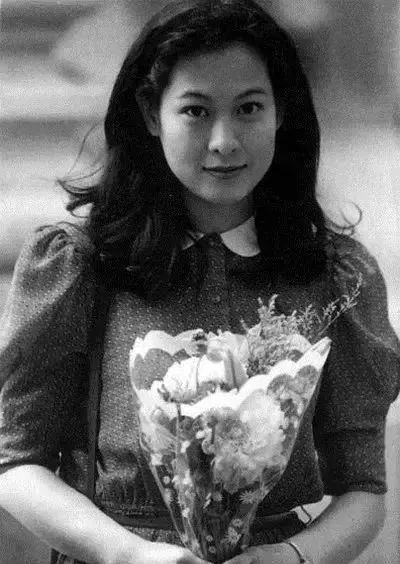
但她的音色卻更得眾人賞識,片中她演唱的單曲《為愛癡狂》一炮而紅,火得猝不及防。
皮膚白皙、不諳世事的眼神,這個淡雅隨性的鄰家女孩俘獲了一眾歌迷。

她又接連發表了幾張專輯,穩穩在樂壇占有一席之地。
《很愛很愛你》唱無怨無悔又灑脫的愛:“很愛很愛你,所以愿意,舍得讓你往更幸福的地方飛去。”
《成全》笑著道出愛情里放手后的釋然:“不為了勉強可笑的尊嚴,所有悲傷丟在分手那天。”
她的歌里,總有一種直擊人心的力量,穿透無數少男少女的心,一同笑過哭過、愛過也痛過……
歌手劉若英,終于在黑暗孤單的追夢之旅中,得以窺見天光。
作為歌手,劉若英的成績無疑是出色的。
但作為演員,劉若英卻是被嚴重低估的。
《粉紅女郎》里她扮丑,飾演恨嫁的方小萍,每天一邊做操一邊喊口號:“我要結婚我要結婚,不要放棄不要放棄!”
蘑菇頭、大板牙,和本身性格截然不同的妝造,現在看還是讓人忍不住笑出聲。
連導演都贊:為了演戲,當真是偶像包袱都能舍棄!

而時至今日,《粉紅女郎》仍被譽為女性題材里經典中的經典。
她可以古靈精怪地搞笑,也可以娓娓道來一段故事。
《人間四月天》里她飾演堅韌隱忍的張幼儀,淡如水的文藝氣質,不輸女主周迅。

后來在《天下無賊》里,一場無聲的哭戲再一次顛覆了大眾對她演技的認知。
影片里,她飾演做過不少壞事的賊婆王,卻因孩子保留著一絲善念。
被警察找到的那時,她坐在餐館,得知丈夫的死訊,眼淚止不住地往下掉。

這幾顆淚珠,砸進了所有人的心里,也一度被稱為是“教科書般的演技”。
不少人后知后覺去看劉若英的這些年,才發現她早把影后、視后拿了個遍。

換別人,早就被鋪天蓋地的營銷吹上天了。
唯有劉若英,始終低調且云淡風輕,紅得不疾不徐。
在娛樂圈這個名利場,她只愿做自己想做的事。
唱歌、演習、寫作、拍電影……而且每樣都做得很好。
2018年,她首部導演的電影《后來的我們》上映不到十天就拿下9億票房,獲得5項金雞獎的提名。

張嘉佳曾用一句話評價她:“喜歡劉若英,不是她某個階段,而是整場花開的過程。”
沒錯,劉若英的綻放不是一蹴而就的,而是緩緩盛開、清風自來。

你會發現這個沒有傾城之貌的女孩,在你心里悄悄一住就是好多年。
然后在某個不經意的瞬間,帶給你驚喜。
唱過無數首歌,演過幾百場戲,劉若英的歸宿卻始終是個謎。
有人說,她會像《一輩子的孤單》唱的那樣,孤單終老;
也有人猜測,在某段刻骨銘心的愛情里,她不撞到南墻絕不回頭。

唯獨沒想到的是,這個心里有執念的小女人官宣閃婚了。
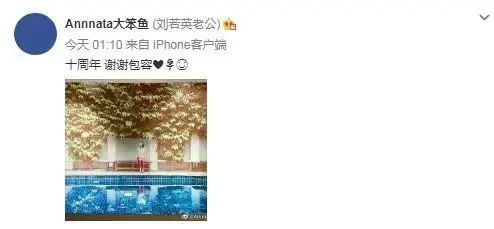
2011年,41歲的劉若英與富商鐘小江結婚,4年后,兒子也出生了。

往事煙消云散,這個“為愛癡狂”的少女“后來”也遇到了“很愛很愛你”的那個人。
婚后,夫妻倆更是把生活過成了詩。
劉若英還出了本書叫《我敢在你懷里孤獨》,述說自己與老公彼此吸引又各自獨立的愛情觀。
一起出門時,兩人去不同的電影院,看不同的電影;結束后,又能手牽手一起回家。
她說:“最好的夫妻關系,就是在枝繁葉茂的同時也能保有完整的自我。”
年過50,知天命。
可在劉若英身上,總有種無關年齡的從容與淡然。
她的篤定讓你覺得,任由世事紛紛擾擾,她都能過好這一生。

在家庭與自我里,她總能找到微妙的平衡。
比起臺前獻唱,她的工作更多轉到了幕后。
空閑下來,就陪孩子去各地旅行,沒有人比她更明白,陪伴對于一個孩子的重要性。

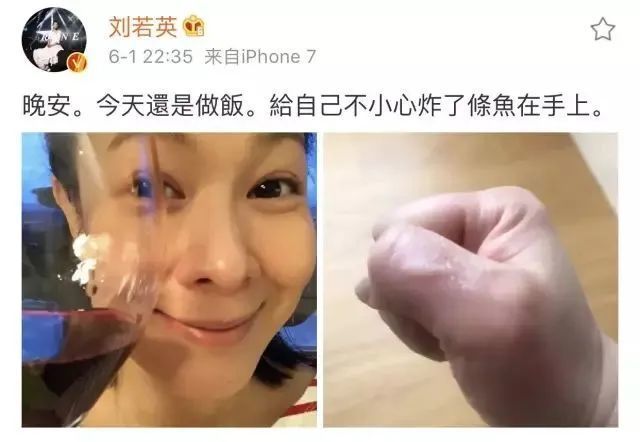
偶爾也會po自己的廚藝,告訴大家自己有在好好生活。
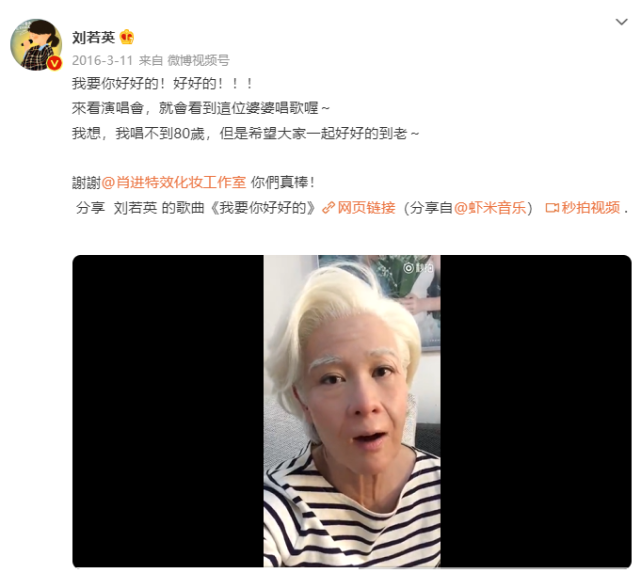
雖然有時也會感嘆自己眼角的皺紋和水腫的臉,但看得出來,她并不遺憾膠原蛋白的流失,反而還會打扮成80歲的樣子博大家一笑。
遠離喧囂后,真正開啟了幸福又平淡的生活。
漂泊了前半生,她是孤單的,也是自由的;
后來的她,終于找到了自己人生的航向,駛向遠方。

這樣的生活狀態,才是真正令人羨慕的。
曾經在《后來》里緬懷過去,如今聽著《縮影》感嘆我們都成為了更好的自己。
從藍色百褶裙的少女,一路成長為有故事的女人,53歲的劉若英魅力只增不減。

都說歲月從不敗美人,但要我說,如劉若英這般靈魂豐富的女子,才算得上扛住了歲月的打磨。
從苦澀歲月里蒸餾出的甘醇,終究釀成了回味悠長的甜。
再次看見這位老朋友出來營業,你只想珍惜這段來之不易的時光。
再沒有這樣一個人,懂你青春里的那些愛與痛。
或許一期一會后,她又會突然消失去過自己的生活。
但沒關系,揮手告別后,會有更嶄新的明天。

好久不見,奶茶。
歡迎回來,劉若英。





