
Meta 承諾其下一代定制人工智能芯片將更加強大,能夠更快地訓練其排名模型。
Meta 訓練和推理加速器 (MTIA) 旨在與 Meta 的排名和推薦模型完美配合。這些芯片可以幫助提高訓練效率,并使推理(即實際的推理任務)變得更容易。
該公司在一篇博客文章中表示,MTIA 是其長期計劃的重要組成部分,該計劃旨在圍繞如何在其服務中使用人工智能來構建基礎設施。它希望設計的芯片能夠與其當前的技術基礎設施和 GPU 的未來進步相配合。
Meta 在其帖子中表示:“實現我們對定制芯片的雄心意味著不僅要投資于計算芯片,還要投資于內存帶寬、網絡和容量以及其他下一代硬件系統。”
Meta于 2023 年 5 月發布了 MTIA v1,專注于向數據中心提供這些芯片。下一代 MTIA 芯片也可能瞄準數據中心。MTIA v1 預計要到 2025 年才會發布,但 Meta 表示這兩款 MTIA 芯片現已投入生產。
目前,MTIA 主要訓練排名和推薦算法,但 Meta 表示,最終目標是擴展芯片的功能,開始訓練生成式人工智能,如 Llama 語言模型。
Meta 表示,新的 MTIA 芯片“從根本上專注于提供計算、內存帶寬和內存容量的適當平衡。”該芯片將擁有 256MB 片上內存,頻率為 1.3GHz,而 v1 的片上內存為 128MB 和 800GHz。Meta 的早期測試結果顯示,在公司評估的四種型號中,新芯片的性能比第一代版本好三倍。
Meta 致力于 MTIA v2 已有一段時間了。該項目內部稱為 Artemis,此前有報道稱僅專注于推理。
隨著人工智能的使用,對計算能力的需求不斷增加,其他人工智能公司一直在考慮制造自己的芯片。谷歌于 2017 年發布了新的 TPU 芯片,而微軟則發布了 Maia 100 芯片。亞馬遜還有其 Trainium 2 芯片,其訓練基礎模型的速度比之前的版本快四倍。
購買強大芯片的競爭凸顯了需要定制芯片來運行人工智能模型。對芯片的需求增長如此之快,以至于目前在人工智能芯片市場占據主導地位的英偉達的估值達到了 2 萬億美元。
Meta下一代訓練和推理加速器
Meta 的下一代大規模基礎設施正在以人工智能為基礎進行構建,包括支持新的生成式人工智能 (GenAI) 產品和服務、推薦系統以及先進的人工智能研究。隨著支持人工智能模型的計算需求隨著模型的復雜性而增加,Meta預計這項投資將在未來幾年增長。
去年,Meta推出了元訓練和推理加速器 (MTIA:Meta Training and Inference Accelerator) v1,這是Meta在內部設計時考慮到 Meta 的人工智能工作負載的第一代人工智能推理加速器,特別是Meta的深度學習推薦模型,它正在改善各種體驗我們的產品。
在Meta看來,MTIA 是一項長期事業,旨在為 Meta 獨特的工作負載提供最高效的架構。隨著人工智能工作負載對我們的產品和服務變得越來越重要,這種效率將提高Meta為全球用戶提供最佳體驗的能力。MTIA v1 是提高公司基礎設施的計算效率并更好地支持公司的軟件開發人員構建 AI 模型以促進新的、更好的用戶體驗的重要一步。
現在,Meta正在分享有關下一代 MTIA 的詳細信息。

Meta表示,該推理加速器是公司更廣泛的全棧開發計劃的一部分,用于定制、特定領域的芯片,可解決獨特的工作負載和系統問題。這個新版本的 MTIA 使Meta之前的解決方案的計算和內存帶寬增加了一倍以上,同時保持了與工作負載的緊密聯系。它旨在高效地服務于為用戶提供高質量推薦的排名和推薦模型。
據Meta介紹,該芯片的架構從根本上側重于為服務排名和推薦模型(serving ranking and recommendation models)提供計算、內存帶寬和內存容量的適當平衡。在推理中,即使批量大小(batch sizes)相對較低,Meta也認為需要能夠提供相對較高的利用率。通過專注于提供相對于典型 GPU 而言超大的 SRAM 容量,Meta認為可以在批量大小有限的情況下提供高利用率,并能在遇到大量潛在并發工作時提供足夠的計算。

該加速器由 8x8 處理元件 (PE:processing elements) 網格組成。這些 PE 顯著提高了密集計算性能(比 MTIA v1 提高了 3.5 倍)和稀疏計算性能(提高了 7 倍)。這部分歸功于與稀疏計算流水線相關的架構的改進。它還來自Meta為 PE 網格供電的方式:Meta將本地 PE 存儲的大小增加了兩倍,將片上 SRAM 增加了一倍,將其帶寬增加了 3.5 倍,并將 LPDDR5 的容量增加了一倍。
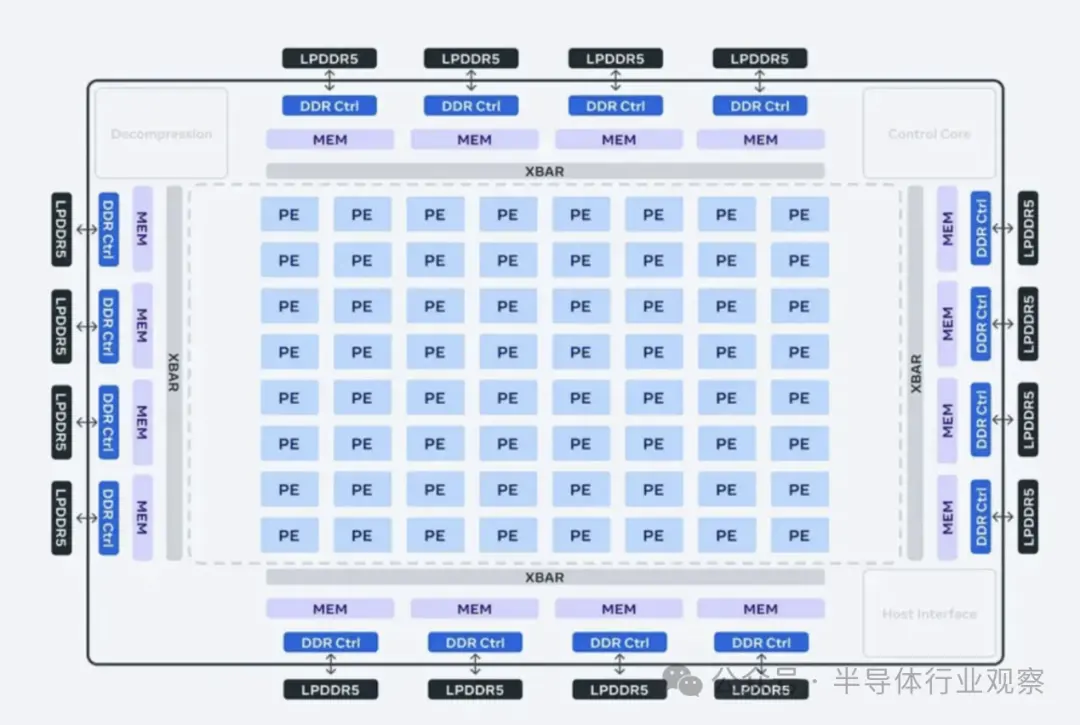

Meta新的 MTIA 設計還采用改進的片上網絡 (NoC) 架構,使帶寬加倍,并允許以低延遲在不同 PE 之間進行協調。PE 中的這些功能和其他新功能構成了關鍵技術,這對于Meta將 MTIA 擴展到更廣泛、更具挑戰性的工作負載的長期路線圖至關重要。


Meta強調,有效地服務公司的工作負載不僅僅是一個硅挑戰。共同設計硬件系統和軟件堆棧以及芯片對于整體推理解決方案的成功更是至關重要。

為了支持下一代芯片,Meta開發了一個大型機架式系統,最多可容納 72 個加速器。它由三個機箱組成,每個機箱包含 12 個板,每個板包含兩個加速器。Meta專門設計了該系統,以便可以將芯片的時鐘頻率設置為 1.35GHz(從 800 MHz 提高)并以 90 瓦的功率運行,而第一代設計的功耗為 25 瓦。Meta表示,這個設計能確保公司可以提供更密集的功能以及更高的計算、內存帶寬和內存容量。這種密度也能使Meta能夠更輕松地適應各種模型復雜性和尺寸。

除此之外,Meta還將加速器之間以及主機與加速器之間的結構升級到 PCIe Gen5,以提高系統的帶寬和可擴展性。如果選擇擴展到機架之外,還可以選擇添加 RDMA NIC。
Meta重申,從投資 MTIA 之初起,軟件就一直是公司重點關注的領域之一。作為 PyTorch 的最初開發者,Meta重視可編程性和開發人員效率。按照Meta所說, MTIA 堆棧旨在與 PyTorch 2.0 以及 TorchDynamo 和 TorchInductor 等功能完全集成。前端圖形級捕獲、分析、轉換和提取機制(例如 TorchDynamo、torch.export 等)與 MTIA 無關,并且正在被重用 MTIA 的較低級別編譯器從前端獲取輸出并生成高效且設備特定代碼。這個較低級別的編譯器本身由幾個組件組成,負責為模型和內核生成可執行代碼。
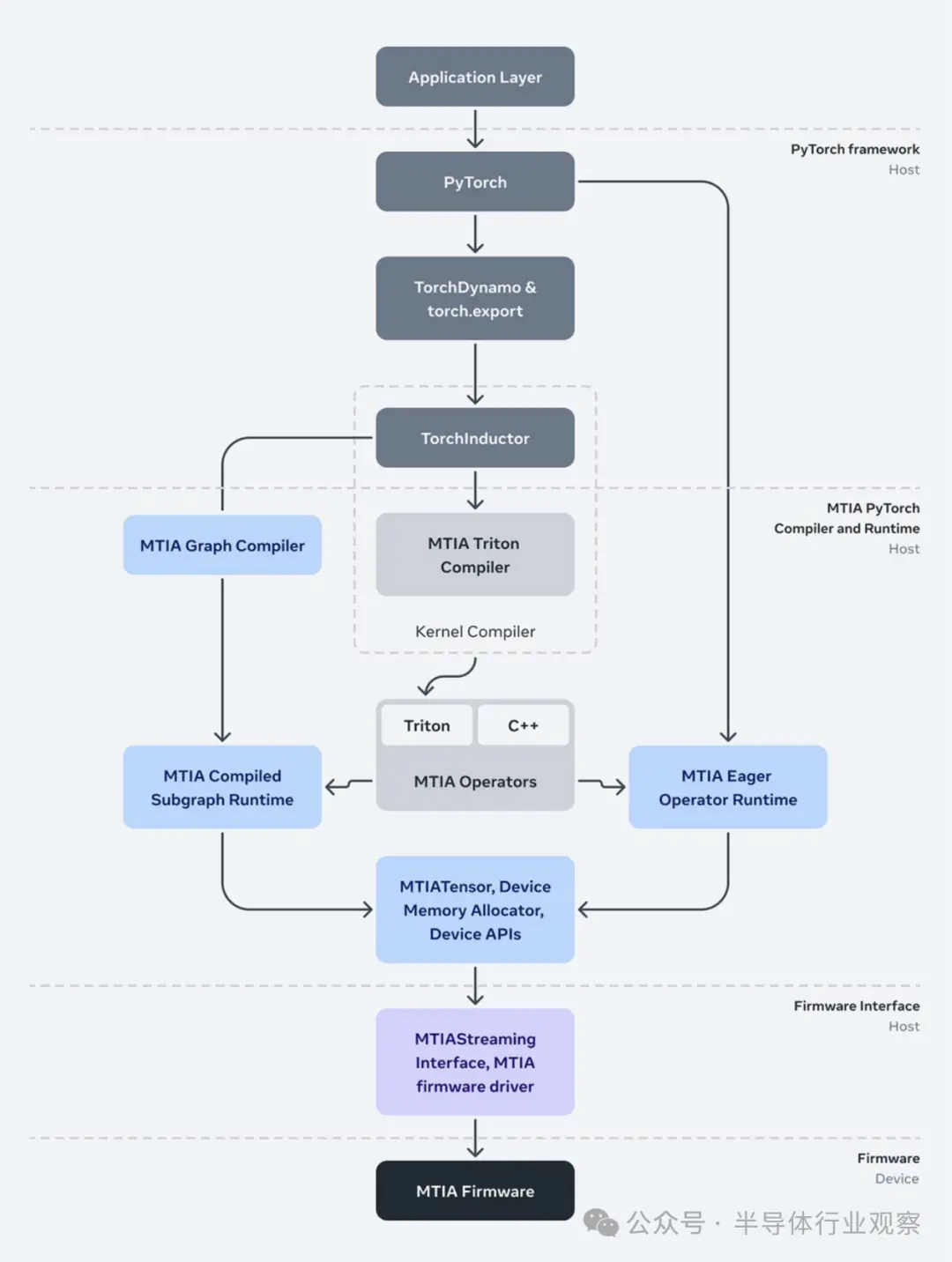
下面是負責與驅動程序/固件連接的運行時堆棧。MTIA Streaming 接口抽象提供了推理和(未來)訓練軟件管理設備內存以及在設備上運行運算符和執行編譯圖所需的基本和必要操作。最后,運行時與位于用戶空間的驅動程序進行交互——Meta解析說,做出這一決定是為了使公司能夠在生產堆棧中更快地迭代驅動程序和固件。
在許多方面,這種新芯片系統運行的軟件堆棧與 MTIA v1 類似,這使得團隊的部署速度更快,因為Meta已經完成了在該架構上運行應用程序所需的大部分必要的集成和開發工作。
新的 MTIA 旨在與為 MTIA v1 開發的代碼兼容。由于Meta已經將完整的軟件堆棧集成到芯片中,因此開發者在幾天內就可以使用這款新芯片啟動并運行我們的流量。這使Meta能夠快速落地下一代 MTIA 芯片,在不到 9 個月的時間內從第一個芯片到在 16 個地區運行的生產模型。
此外,Meta還通過創建 Triton-MTIA 編譯器后端來為 MTIA 硬件生成高性能代碼,進一步優化了軟件堆棧。Triton是一種開源語言和編譯器,用于編寫高效的機器學習計算內核。它提高了開發人員編寫 GPU 代碼的效率,Meta發現, Triton 語言與硬件無關,足以適用于 MTIA 等非 GPU 硬件架構。
Triton-MTIA 后端執行優化以最大限度地提高硬件利用率并支持高性能內核。它還公開了利用 Triton 和 MTIA 自動調整基礎設施來探索內核配置和優化空間的關鍵方法。
按照Meta所說,他們實現了對 Triton 語言功能的支持并集成到 PyTorch 2 中,為 PyTorch 操作員提供了廣泛的覆蓋范圍。例如,借助 orchInductor,開發人員可以在提前 (AOT) 和即時 (JIT) 工作流程中利用 Triton-MTIA。
根據Meta的觀察,Triton-MTIA 顯著提高了開發人員的效率,這使Meta能夠擴大計算內核的創作范圍并顯著擴展對 PyTorch 運算符的支持。
Meta總結說,迄今為止的結果表明,這款 MTIA 芯片可以處理作為 Meta 產品組件的低復雜性 (LC) 和高復雜性 (HC) 排名和推薦模型。在這些模型中,模型大小和每個輸入樣本的計算量可能存在約 10 倍到 100 倍的差異。因為Meta控制整個堆棧,所以與商用 GPU 相比,Meta可以實現更高的效率。實現這些收益需要持續的努力,隨著Meta在系統中構建和部署 MTIA 芯片,他們承諾將繼續提高每瓦性能。
Meta分享說,早期結果表明,在公司評估的四個關鍵模型中,這種下一代芯片的性能比第一代芯片提高了 3 倍。在平臺層面,與第一代 MTIA 系統相比,憑借 2 倍的設備數量和強大的 2 路 CPU,Meta能夠實現 6 倍的模型服務吞吐量和 1.5 倍的每瓦性能提升。為了實現這一目標,Meta在優化內核、編譯器、運行時和主機服務堆棧方面取得了重大進展。隨著開發者生態系統的成熟,優化模型的時間正在縮短,但未來提高效率的空間更大。
MTIA 已部署在數據中心,目前正在為生產中的模型提供服務。Meta已經看到了該計劃的積極成果,因為它使我們能夠為更密集的人工智能工作負載投入和投資更多的計算能力。事實證明,它在針對元特定工作負載提供性能和效率的最佳組合方面與商用 GPU 具有高度互補性。

Meta最后說,MTIA 將成為公司長期路線圖的重要組成部分,旨在為 Meta 獨特的人工智能工作負載構建和擴展最強大、最高效的基礎設施。
Meta也正在設計定制芯片,以便與公司現有的基礎設施以及未來可能利用的新的、更先進的硬件(包括下一代 GPU)配合工作。實現我們對定制芯片的雄心意味著不僅要投資于計算芯片,還要投資于內存帶寬、網絡和容量以及其他下一代硬件系統。
“我們目前正在進行多個計劃,旨在擴大 MTIA 的范圍,包括對 GenAI 工作負載的支持。”Meta說。
【來源:半導體行業觀察】





