
想必大家都聽說過刪庫跑路吧,我之前一直把它當一個段子來看。
可萬萬沒想到,就在昨天,我們公司的某位員工,竟然寫了一個比刪庫更可怕的 Bug!
給大家分享一下(不是公開處刑),希望朋友們引以為戒。
一、Bug 起因
事情是這樣的,昨天中午 11 點左右,突然用戶群里的小伙伴反饋:自己直接成為了 魚聰明 AI 網站 的管理員!
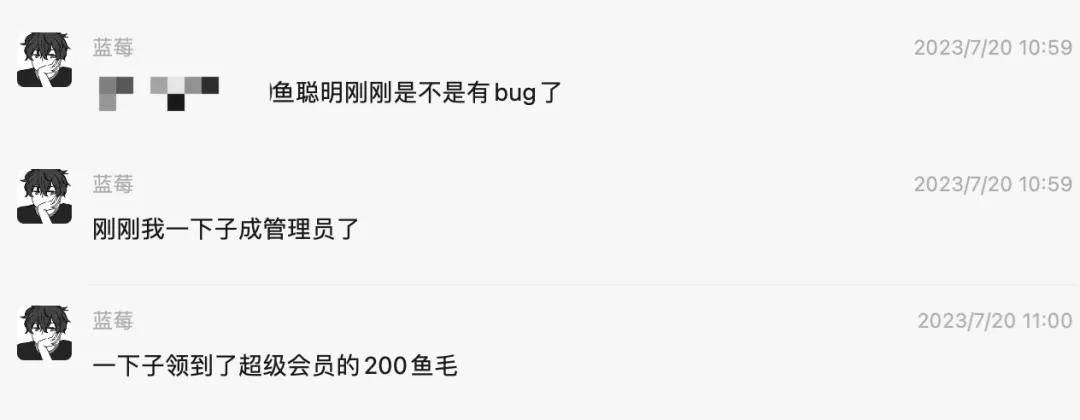
接下來,陸續有更多同學反饋:大家都成管理員了!

看到這里,我立刻就去查了下數據庫,結果看到的是:
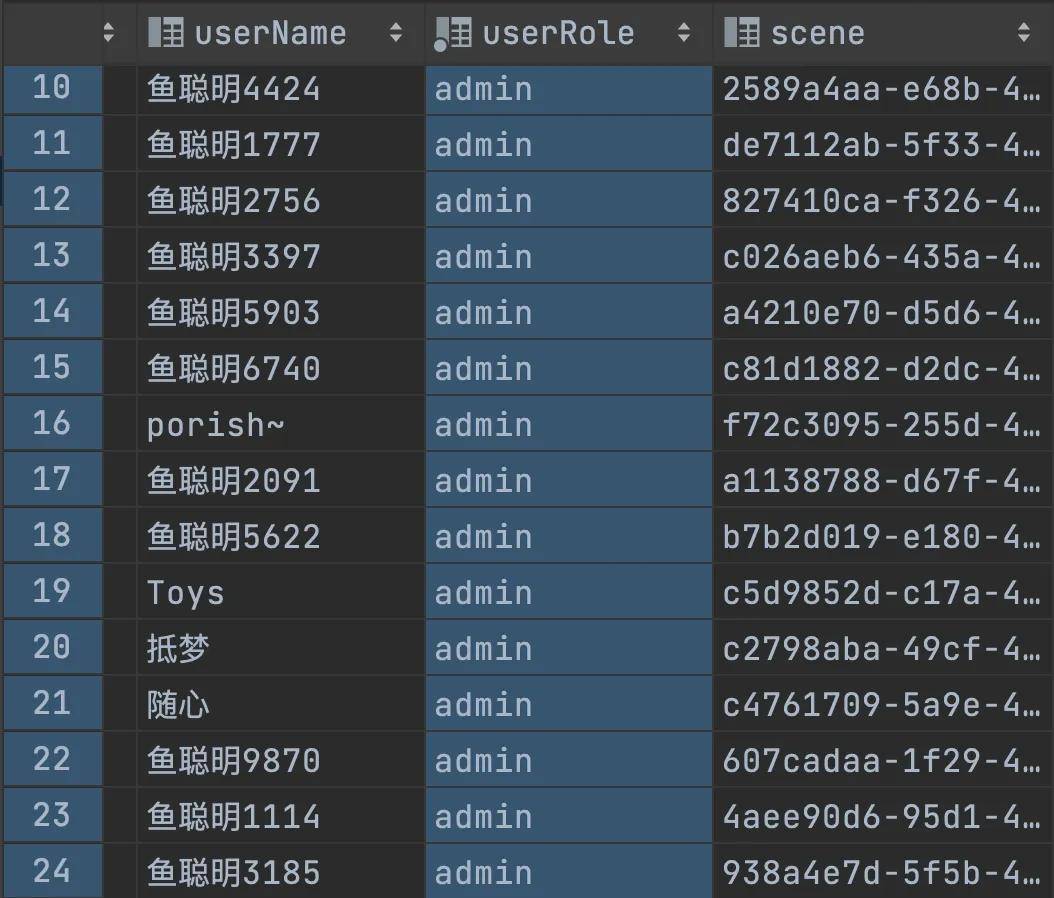
好家伙,早起腦供血不足的我立刻高血壓上來了,怎么所有的用戶都變成管理員了?!
我趕緊問下我所有的員工,這特么是誰干的!!!
然后員工小 A 大叫:“我 X,是我今天執行單元測試更新數據的時候,少加了個 where 條件!”
本來的預期:update user set userRole = 'admin' where id = 1
實際上執行:update user set userRole = 'admin'
于是導致整個庫里的所有用戶都變成了管理員,大家可以愉快地薅魚毛了。
二、緊急處理
后來據這位寫 Bug 的同學的回憶,由于她之前沒有遇到過類似的情況,第一時間腦袋是一片空白、頭嗡嗡的,完全不知道接下來要怎么做。
不過我是很冷靜的,因為之前在公司處理過類似的情況,畢竟曾經凌晨 4 - 5 點的時候都被叫起來過。。。
所以立刻就給他發了一段處理方式:

解釋一下,就跟我們在路上看到一起交通事故一樣,第一時間要么是保護現場,放一個小牌牌不讓大家進到事故發生地;要么就是防止擴大影響,人工疏導不讓更多人圍觀、阻塞交通。
一般這兩件事情是同時執行的,由于我知道怎么能夠判定哪些用戶本來是 VIP(比如通過 VIP 信息)、而且程序又有詳細的日志,所以第一時間是讓員工先把 user 表的所有角色設置為普通用戶權限,防止有人繼續利用管理員權限去做一些不好的事情。
接下來就是立刻停止了線上的前后端服務,一方面是為了后面好恢復數據,另外也是防止一些同學發現自己突然從會員變成了普通用戶,增加大量的人工咨詢成本。
所以當時很多同學訪問魚聰明時,看到了這樣的截圖:

穩定現場后,接下來就是想辦法恢復數據到正常的狀態,好在我給數據庫設置了分鐘級別的備份,可以直接把數據恢復到事故發生前的最近正常的時間點。
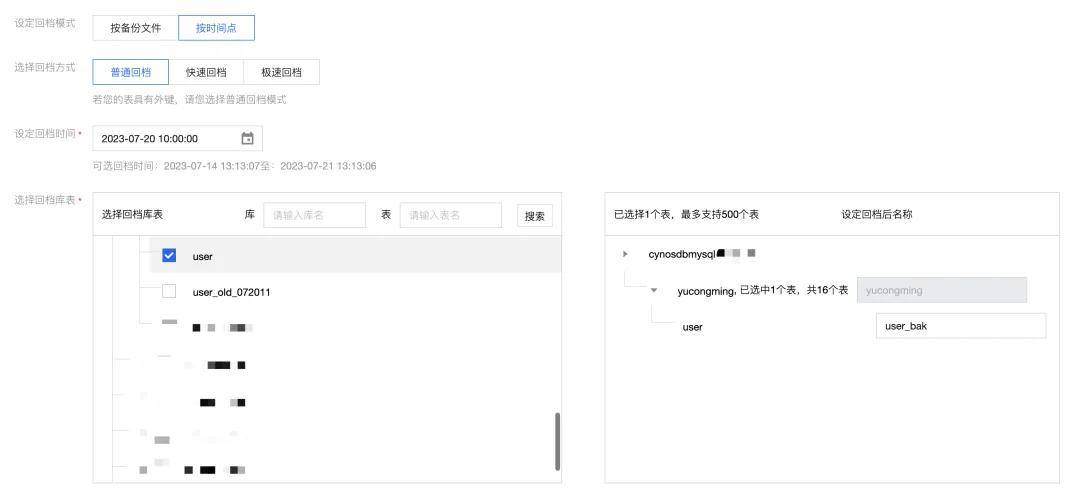
有了備份后的老數據,還要考慮恢復這個時間點后新增的用戶數據。
有很多種恢復策略,我優先選擇了邏輯最簡單的策略:直接更新用戶 updateTime > '2023-07-20 10:00:00' 的數據,根據 id 點對點覆蓋除了 userRole 之外的數據列;如果沒有對應的 id,新增一條數據。也就是使用類似 saveOrUpdate 的方法。
理想很豐滿,現實很殘酷。萬萬沒想到,由于 updateTime 是一個發生數據修改時自動更新的字段,導致所有的數據 updateTime 全是最新的,相當于要把數據庫全量的數據都去比較一遍。
于是我的員工呢,寫了類似下面這樣的程序:
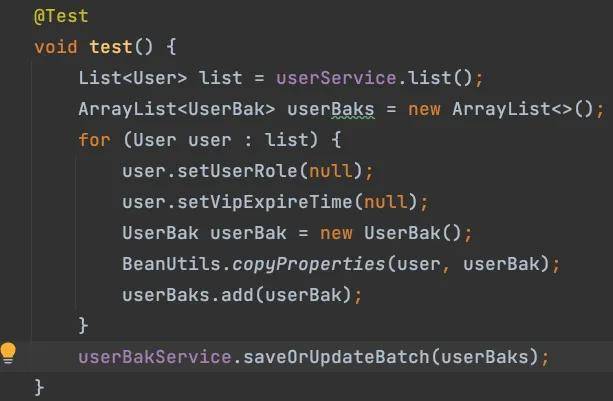
然后就開始執行了,結果執行了很久很久,數據都沒更新完。
看來單線程還是太慢了,于是我用并發編程的方式改進了同步的過程。先把所有用戶分組,然后多線程同時執行 saveOrUpdateBatch 方法。
示例代碼如下:
void restoreUserTable() {
List<User> userList = userService.list();
List<UserBak> userBakList = userList.stream().map(user -> {
user.setUserRole(null);
UserBak userBak = new UserBak();
BeanUtils.copyProperties(user, userBak);
return userBak;
}).collect(Collectors.toList());
int batchSize = 1000;
// 使用 lambda 表達式將 userList 每1000個元素分為一組
List<List<UserBak>> groupedBakUsers = IntStream.range(0, userList.size())
.boxed()
.collect(Collectors.groupingBy(index -> index / batchSize)) // 將索引按組分組
.values()
.stream()
.map(indices -> indices.stream()
.map(userBakList::get) // 根據索引獲取 User 對象
.collect(Collectors.toList())) // 每組1000個元素的列表
.collect(Collectors.toList()); // 所有分組的列表
List<CompletableFuture<Void>> completableFutureList = new ArrayList<>();
int i = 1;
for (List<UserBak> groupedBakUser : groupedBakUsers) {
int finalI = i;
CompletableFuture<Void> completableFuture = CompletableFuture.runAsync(() -> {
boolean b = userBakService.saveOrUpdateBatch(groupedBakUser, batchSize);
});
i++;
completableFutureList.add(completableFuture);
}
CompletableFuture.allOf(completableFutureList.toArray(new CompletableFuture[]{})).join();
}
使用這種方式,很快數據就恢復完成了。
當然,還有更簡單的方式,比如聯表查詢、對比哪些數據行發生了變動,再去做修改。只不過當時情況緊急、再加上數據庫量級可控,我們選擇了相對理解成本最低的方式。
之后,我這邊又手動做了一次全量備份,并且思考了一下還有沒有遺漏的問題,才恢復上線。
三、事后復盤
整個事故時長接近 2 個小時,大致分為:
- 人工發現事故(30 分鐘后通過用戶反饋才得知)
- 定位問題(5 - 10 分鐘)
- 策略制定和同步(5 - 10 分鐘)
- 數據備份恢復(15 分鐘)
- 增量數據同步(40 分鐘)
- 上線前備份(10 分鐘),同時進行其他考慮
從某種意義上來說,這次的事故比直接刪庫更嚴重!因為刪庫了趕緊恢復就好,但這次不僅出現了 “數據污染”,還出現了 “越權” 的問題,我們網站內僅管理員可見的敏感信息會存在泄露風險。好在我們也沒什么敏感信息哈哈。
還有就是用戶可能會利用漏洞來薅魚毛(管理員可以大量獲取),但經過我們的統計,這段時間利用漏洞薅魚毛的人數寥寥無幾,大家都是非常善良的,這才放下心來。
雖然這次的事故帶來的損失不是特別大,但也發現了我們系統存在的問題。
我也跟這位員工說:出了事情不可怕,可怕的是不知道改正,出現同樣的事情。
那么應該如何防止出現類似的事故呢?
1、控制操作權限
為了防止用戶執行 update、delete 操作時不小心漏掉了 where 條件、直接更新全量數據,企業中一般是會禁止不帶 where 條件的修改操作的。
出現這次的事故后,我也立刻給 MySQL 開啟了 sql_safe_updates 配置:
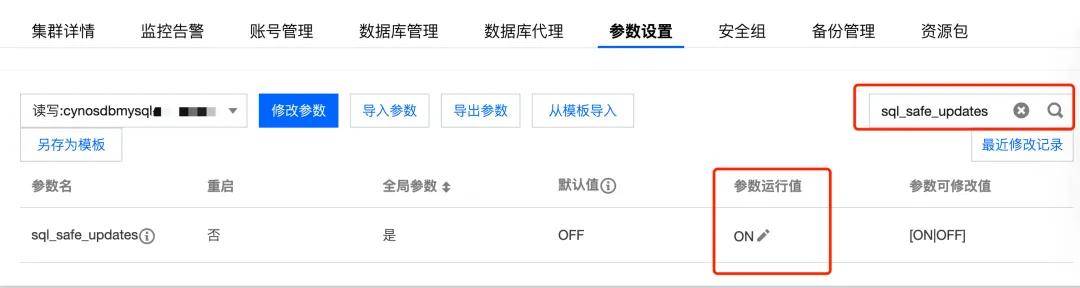
缺少 where 條件的更新會直接觸發下列報錯:

之前為什么沒加?主要是因為以前都是自己一個人開發系統,而且會有需要全量更新的場景,圖省事兒。
2、生產環境隔離
正常情況下,不應該允許直接在本地連接和操作線上數據庫的數據。而是需要先編寫代碼、提交代碼審核、發布上線后,再執行修改操作。
像這次的事故,如果員工不是本地直接更新數據庫,而是提交代碼給我看一下,我大概率就會發現他少寫了更新條件,就能防止了。
其實之前在騰訊的時候,我都會嚴格注意這些事項的。但之所以現在自己公司的項目是允許員工在本地連接線上的,想必大家也能猜到原因 —— 業務規模小、人數少,直接在同一個庫開發會方便一些。
但如果項目的規模上來了,一定要做好多套環境的隔離,本地環境、測試環境、預發布環境、線上環境都要嚴格區分了。
3、SQL 審批
之前在騰訊的時候,想要修改關鍵庫的數據,不能直接執行 SQL 語句,而是要先把 SQL 語句提交到審核平臺,等你的領導和數據庫運維確認沒問題后,才能執行。這樣每條 SQL 都是至少有 2 個人看過的,能夠大大增加安全性。
曾經我覺得這種機制很麻煩,但經歷過一些血淚教訓后,才意識到這個環節真的是泰褲辣!
4、數據庫審計
數據庫審計是指記錄和監控數據庫的訪問及 SQL 語句執行情況,從而精細化風險控制,提高數據安全性。
可以自己在數據庫配置(比如開啟日志、使用審計插件等),也可以使用第三方云服務自帶的審計規則配置。
5、提升風險意識
最不需要技術,卻也是最重要的一點,那就是要讓團隊的所有同學意識到這件事情帶來的風險、問題的嚴重性。
因為你永遠叫不醒一個裝睡的人,同理,再多的防護也限制不了本身就想搞事的人。
所以這件事情是我和這位員工共同的責任,作為懲罰,我們決定請其他同事喝奶茶。就這么愉快地決定了~
不過也有做的好的地方,比如做了完整又靈活的數據備份,這是線上項目必備的操作。
以上就是本期分享,希望大家不僅是看個樂,也能有一些收獲和啟發,不過希望大家都不要遇到這類鬧心的事情。
作者丨程序員魚皮
來源丨公眾號:程序員魚皮(ID:coder_yupi)





