
作者 | 朱潔
策劃 | 李冬梅
過去一年,行業信心跌至冰點
2022 年中,紅衫的一篇《適應與忍耐》的報告,對公司經營提出了預警,讓各個公司保持現金流,重整團隊,想辦法增加盈利。這篇報告的推出的時間點應該是各個整個行業的拐點,大家不再期待 V 型復蘇拐點,信心開始逐步跌落,2023 年初跌倒谷底和冰點。2023 年整個一年都是在艱難的慢慢恢復,各行各業普遍艱難,公司裁員加劇,就業率創新低。數據庫行業 2021 年的資本盛宴開始,眾多創業者剛想闖進來分一杯羹,22 年底 23 年初就結束了,應該說讓從業者深刻體會到了什么是大起大落。站在 2024 年起點往回看,還是非常感慨和唏噓。作為大起大落的親歷者,今天這篇我們一起來總結數據庫行業在 2023 年的一些情況,我會盡量涉及到產品技術,廠商發展,市場環境等多個方面,受限于時間和水平不足,肯定有不少錯漏之處,也歡迎大家一起探討。接下來就正式進入正題:
趨勢一:HTAP 成為主流數據庫的一項基礎能力
數據庫技術起源于美國,中國在這個行業里面不管是市場容量,技術方面總體來說還是全面落后于美國的。所以產品技術這塊國內和國外還是有很大的區別,有些方面國內非常火熱,但是在國外缺完全不一樣,反過來也是一樣的。首先這個特別明顯的就是 HTAP 和 Serverless 兩項技術,HTAP 在國內比國外熱,Serverless 則更是成為海外產品的 default 選項。
HTAP 概念能在國內火爆,TiDB 功不可沒,甚至一度大家覺得這可能是一個細分賽道,不過經過幾年下來,行業還是逐漸形成了一個共識,HTAP 是數據庫的一項基礎能力,而不是一個細分賽道,或者反過來說 HTAP 不足于支撐一個單獨的數據庫細分門類。2023 年一個重要的趨勢就是各個主流數據庫都把 HTAP 支持作為一項基礎能力。典型的有:
23 年 10 月騰訊的 TDSQL-C 也列存索引,并把列存索引和并行查詢整體包裝成 HTAP 能力。
23 年 12 月百度發布 GAIaDB 4.0,重要升級就是推出列存索引和列存引擎,提升不同規模數據的查詢速度,其中列存引擎最大可支持 PB 級數據的復雜分析,并且與事務處理業務嚴格復雜隔離。

海外這個概念提的比較少,google AlloyDB 算是正式提過這個概念,AWS 重點宣傳的是 Zero-ETL,本質上也是 HTAP 的能力,但總的來說海外對這個概念并不是特別感興趣。
趨勢二:Serveless 成為頭部廠商的共識
Serverless 在美國經過 AWS 長達十余年不遺余力的宣傳,早就深入人心,國內因為不同的市場環境,企業普遍還是喜歡預付費為主,所以這種彈性動態的優勢就不明顯,因此導致 Serverless 在國內發展緩慢。
數據庫 Serverless 這塊阿里發力最早,21 年就開始布局,23 年把 Serverless 作為主推方向,基本 TP,AP,NoSQL 各個方向都支持了 Serverless,甚至傳統的 RDS 產品線,以及工具的 DTS 產品也開始支持 Serverless。
23 年 8 月份,騰訊的 TDSQL-C 也宣傳支持 Serverless,并把主打的差異化點是可以完全釋放存儲,數據變成歸檔。業內的 Serverless 無法完全做到不使用不付費,一般實例暫停后仍然會收取高昂的存儲費用,可釋放存儲將徹底解決這一問題。當實例暫停后,數據會進行歸檔存儲。用戶無需再為高額的分布式存儲進行付費,可在原實例暫停后的存儲費用上降低成本 80%。
年底的時候華為 GuassDB for MySQL 也全面商用,號稱相比固定規格,Serverless 實例平均可降低使用成本超 30%,特定情況甚至有 80%+ 的成本降低。
所以從 2023 年開始,Serverless 可以說成為頭部廠商的共識了,相信在接下來數據庫 Serverless 會有一個長足的發展。
趨勢三:國內在產品形態上部分開始領先海外
相比 HTAP,分布式產品在國內發展更充分,競爭對手很多,所以更值得說一說。分布式數據庫國內 OceanBase,TiDB,PolarDB-X 都是比較有特色和競爭力的產品,其中阿里的 PolarDB-X 很早就開始布局和支持存儲分離 + 分布式的技術,走一條存算分離,分布式一體化的技術路線。下圖是阿里宣傳的融合架構圖:
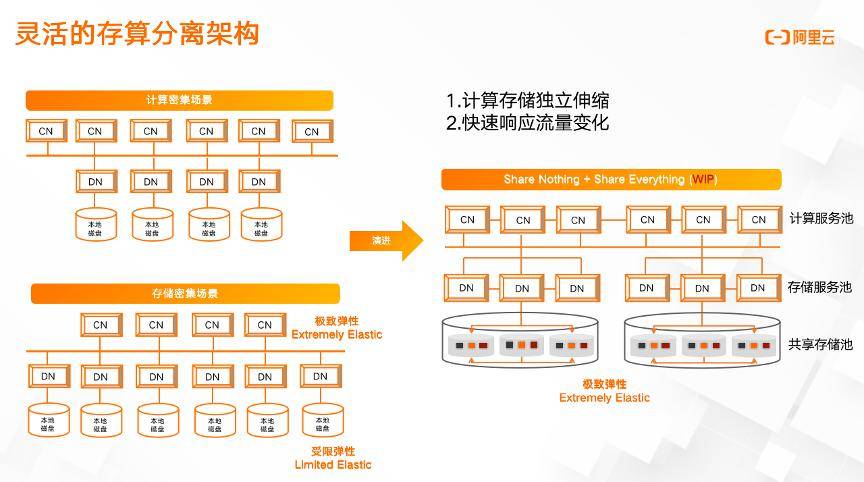
2023 年 AWS re:Invent 上宣布推出 Aurora Limitless Database,本質上是存算分離的 Aurora 的基礎上加了一層 proxy 做分布式。下圖就是 AWS 的架構:

看到 AWS 這個新的發布,國內數據庫圈子好一陣沸騰,覺得國內的數據庫一些方面也可以領先美國廠商了。其實這個趨勢并不是發生在 2023 年某一天,而是一個逐步積累的過程。早在 2020 年的時候,國內的阿里云 RDS 產品能力就比 AWS 要強,提供了三節點,雙節點,單節點,拖管,半拖管等多種形態,除了 AWS 形態,產品性能,規格豐富等都比 AWS 要強。
所以這個趨勢并不能說是 2023 年的新趨勢,這個趨勢一直在發生;但是還是非常值得放到 2023 年重大趨勢中拿出來說,這個還是非常明顯標志著:隨著國內的工程技術能力的逐步增強,會有越來越多的產品領先美國廠商。
趨勢四:AI4DB and DB4AI 成功翻紅
AI4DB,DB4AI 喊了很多年,談不上新概念,不過在 2023 年大模型的帶動下,數據庫和 AI 結合又有了新的想象力,大模型的巨大威力,讓廠商紛紛研究數據庫和大模型的結合。
首先是 23 年 8 月份,騰訊云向量數據庫(Tencent Cloud Vector DB)正式上線公測。作為一款全托管的自研企業級分布式數據庫服務,騰訊云向量數據庫專用于存儲、檢索、分析多維向量數據。該數據庫支持多種索引類型和相似度計算方法,單索引支持 10 億級向量規模,可支持百萬級 QPS 及毫秒級查詢延遲,不過半年后,直到筆者寫這篇文章的時候,騰訊的向量數據庫還是沒有商用。
百度也趕在年底發布了單獨的自研向量數據庫,百度向量數據庫 VectorDB 是一款純自研高性能、高性價比、生態豐富且即開即用的向量數據庫服務。支持多種索引類型和相似度算法,百億級向量規模,毫秒級查詢延遲。百度向量數據庫不僅能配合大模型打造專業知識庫,還可以應用于圖片搜索,音樂推薦,文本分類等領域。
23 年 12 月份,百度還發布 DBSC(數據庫智能駕駛艙),這個是利用 AI 的技術,為用戶提供安全審計、智能診斷與數據庫管理的數據庫自治服務。DBSC 利用 AI 大模型能力和專家經驗實現數據庫的智能化洞察、評估和優化。有效保證數據庫服務的安全、穩定及高效。這塊的探索應該說阿里最早,阿里的 DAS 產品在 20 年就看準了數據庫安全自治工具一體化成主流趨勢。百度的 DBSC 比較有特色的是提供問答診斷、工單處理、知識查找等能力的智能手,這個能力其實是非常考驗產品知識的積累的。
NoSQL 這塊阿里的 Lindorm 直接簡單粗暴的將大模型內置到系統里面,支持以圖搜圖功能,應該說是一種探索,不過總體覺得還是比較難做出特色和實用價值的。
美國的 AWS 利用 AI 增強 ETL 能力,Google 利用大模型實現代碼改寫能力,也是在這個方向發力,國內的也有創業公司跟進,不過目前離成熟還需要一些時間。
趨勢五:云廠商開始發揮軟硬件垂直整合優勢
應該說云廠商本質上先革 IDC 的名,再革各種基礎軟件的命,要相比客戶自建有明顯的優勢,推出自研,走垂直整合是必選道路。前一個非常成功的 2C 廠商是蘋果,2B AWS 也是復制這條道路。國內總體差距比較大,云廠商里面華為,阿里跟進的比較快,都推出了 ARM 系列芯片,國內目前最強的應該是華為的鯤鵬系列。
2023 年開始阿里的全線主力產品都進行了適配,阿里發布的 RDS 經濟版本就是 適配 ARM 系列,基于倚天 /ARM 芯片服務器上持續優化,提高性能,定價則是只有 X86 實力的 60%~70% 的價格,通過性價比吸引用戶嘗鮮和試用。應該說短期內 ARM 的能力還不夠,所以是經濟版本,長期看,ARM 應該要能能力迭代更快,長期發揮比 X86 更好的能力。如果走向這一天,云廠商的相比自建客戶的優勢將進一步拉大。
華為、阿里的動作標志著云廠商 2023 年也開始發揮垂直整合的優勢,不過總體來說國內的發展水平相對美國還是差距比較大。
趨勢六:RDS 還是常青大盤產品,NoSQL 創新相對較少
2023 年我們觀察到,NoSQL 是隨著互聯網場景誕生的,隨著十多年的發展,開始碰到一定的創新瓶頸了。反過來關系型數據庫都紛紛一定程度上吸收了 NoSQL 在性能,分布式,高可用的優勢,關系型數據庫反倒有不少進展。
阿里云棲大會,集中展示了阿里 RDS 的進展,包括解決通用云盤 IOPS 和容量解耦的問題,通過冷溫熱數據分層,讀寫性能提高 102%,存儲成本降低 90%。內核層面也有創新,通過 binlog 并行解析,縮短 crash/recovery 時間,改進 RTO 事件,支持表級別、行級別壓縮;冷溫熱數據分層,降低客戶使用成本等等。應該說從產品形態,計費,內核全方面進行了改進。
整個行業在 NoSQL 這塊相對而言就乏善可陳了。
另外 中立廠商 NineData 進行了第三方公開 RDS sysbench 測試,華為云,百度云分列第一二位,反而不是大家理解的阿里、騰訊。說明在這個領域國內云廠商競爭還是非常激烈的,阿里騰訊保持優勢也還是非常困難的。也說明這個領域發展還是比較快的。應該說 RDS 仍能是常青大盤型產品。NoSQL 主要是向量數據庫有一些發展,期待傳統的緩存,文檔數據庫以及一些細分時序,圖等領域有更多的創新點。
趨勢七:國產數據庫紛紛演進 RAC 架構,企圖突破集中式架構
RAC 架構是 Oracle 經典架構,在 Oracle 10/11 就已經推出。
互聯網廠商因為數據量特別大,Oracle license 又特別貴,所以紛紛用 MySQL,疊加各種分布式技術來實現 Oracle 的替代,這就是轟轟烈烈的去 IOE。所以在過去的一段時間,有認為 RAC 就是落后的代表,但是隨著時間的發展,大家還是紛紛發現,一般的企業不一定需要那么大的數據量,在這種場景下 RAC 優勢就比較明顯了。
所以 2023 年在私有化場景上有一個非常明顯的趨勢,就是國產數據庫廠商紛紛發布了類似 RAC 技術的產品。典型的有達夢 DSC 已經在部分用戶那邊商用了,優璇再次發布了 SuperRAC,人大金倉也很快會推出共享存儲多讀多寫的產品,高斯的 RAC 版本已經在路上了,虛谷偉業的 RAC 也在開發中。
但同時有意思的是,國內紛紛支持 RAC, 2023 年 oracle 原廠開始宣布支持分布式能力。所以說技術關鍵還是看場景,適合的場景選擇適合的技術,未來大概率通用數據庫會走的道路是分布式存算分離一體化的道路,給客戶豐富的選擇。
趨勢八:國內融資環境異常艱難
前面講的都是技術方面的,除了技術外,市場環境,廠商發展在 2023 年也是精彩紛呈,值得一看,接下來說幾個關鍵點。
首先就是 2023 年國內的融資環境異常艱難,相對于 2021 年的高歌猛進,2023 年異常冰冷,市場上絕大部份公司都很難融資,只有少數的公司獲得融資,而且金額也不是很高。
所以我們會看到國內很多大佬紛紛下場,預言 2027 年國內數據庫廠商十家,二十家左右。應該說國內數據庫廠商現在是有點多了,近 300 個數據庫,200 家廠商,而數據庫又是一個非常通用的產品,所以是非常難容得下這么多的廠商的,至于是十家,還是二十家不關鍵;關鍵是怎么在這個殘酷的市場競爭力活下來是非常考驗的。
總的來說,我相信最有創新能力,客戶服務能力強的廠商會活下來。
趨勢九:信創提速
信創從 2019 年大力推行以來,金融行業走的最快,金融行業基本完成了大行,股份制的劃分,推進到了中小行。國家在推動信創目錄上也是動作頻頻。12 月剛公布的新一輪信創目錄:http://www.itsec.gov.cn/aqkkcp/ywjs/。
另外除了金融行業,明顯看到其他關鍵行業如電信、電力都加快了信創的速度。現在信創最大的問題還是競爭太激烈,導致沒有一個實際賺到錢的廠商。大概估計數據庫研發人均收入還不足 50 萬,離健康的 500 萬差 10 倍以上。
信創就是個雙刃劍,給了數據庫廠商希望,估計未來大量倒閉的也是出在這個領域。
趨勢十:頭部獨立廠商商業化能力越來越強
最后一個趨勢,留給在數據庫行業掙扎的企業。
應該說宏觀環境很不好,但是頭部廠商還是持之以恒的突破。像 OB 加大了公有云投入,獲得了一些標桿客戶,像包括新零售行業的海底撈、二維火和客如云,制造業的理想汽車,互聯網行業的高德、攜程、快手、作業幫、翼鷗教育、GCash,以及跨境行業的洋蔥集團、縱騰集團、遞四方等。
TiDB 還在持續拓展海外客戶,包括嘗試 Serverless 等,和 AWS 合作在客戶上也有不錯的進展。
國內深圳計算所推出的崖山數據庫,是今年的異軍突起,有一些標桿客戶,主打 Oracle 兼容,包括推出個人版已向所有用戶和開發者全面開放下載,大家可以去嘗試使用一下。
2024 年,數據庫領域將是柳暗花明又一村
2023 艱難的一年過去,迎來了有希望的 2024 年。展望 2024,我們判斷未來會有這么幾個大的趨勢:
- AI 代碼改寫會越來越成熟,Oracle 轉 MySQL,PG 預計會變得很簡單。
- 向量數據庫會走向更務實的實用階段,預計在智能問答,助手等領域會有更多實際應用。
- 存算分離和分庫分表分布式技術會走向融合。
- 1~2 年之內,Serverless 在國內會變得很普及,各個云廠商都預計會推出 serveless 數據庫產品。
- 數據倉庫領域,湖倉一體化,會成為數據倉庫的主要形態,形成共識。
- 2024 年應該會是數據庫的轉折點,有一些數據庫廠商會被淘汰。
微軟 Copilot 生成暴力色情圖且拒不更改,內部工程師絕望舉報至政府!
奧特曼無罪重返董事會!谷歌華人工程師被捕:號稱自己能力“全球僅10個”;美國要求字節跳動半年內剝離TikTok | Q資訊
谷歌:不建議未成年人接觸 C++,太過危險!Yann LeCun 和馬斯克看到都笑了
馬斯克最新回應:OpenAI 的“郵件攻擊”在說謊!斯諾登力挺:OpenAI 這么做是反人類!





