
隨著ChatGPT大火,GPU成為了目前最熱單品,一個頂級的GPU可以賣到數萬美元。由于對其產品的需求激增,英偉達(NVIDIA)的市場估值更是飆升至2萬億美元以上。
你有沒有好奇:為什么AI會帶火GPU?AI計算一定要用GPU嗎?

今天我們就來一起聊一下GPU到底是什么?
▉ 什么是GPU,與CPU有何區別?
在GPU火之前,提到最多的就是CPU,那么二者有什么區別呢?CPU是不是會被GPU取代呢?

下面我們來看下二者的具體區別:
CPU是Central Processing Unit的錯寫,CPU通常被稱為計算機的"大腦",主要來承擔計算的處理功能,操作系統和應用程序運行等操作都必須依賴它來進行,CPU 還決定著計算機的整體速度。
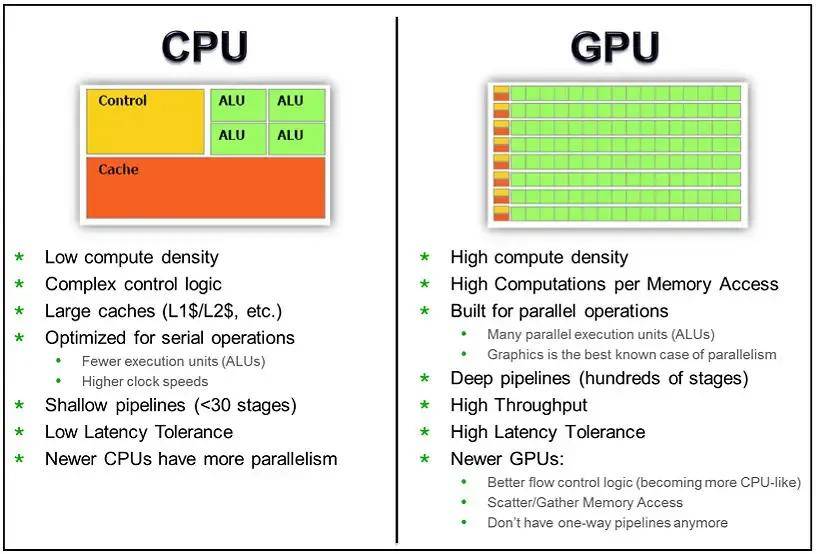
GPU是Graphics Processing Unit的縮寫,其最初的設計是用于輔助3D渲染,能同時并行更多指令,其非常適合現在比較熱門的動漫渲染、圖像處理、人工智能等工作負載。
簡單來說,CPU是為延遲優化的,而GPU則是帶寬優化的。CPU更善于一次處理一項任務,而且GPU則可以同時處理多項任務。就好比有些人善于按順序一項項執行任務,有些人可同時進行多項任務。
為演示 CPU 與 GPU 的不同,英偉達曾經邀請亞當·薩維奇 (Adam Savage) 和杰米·海尼曼 (Jamie Hyneman) 利用機器人技術和彩彈再現了一幅廣為人知的藝術作品--蒙娜麗莎的微笑。這個視頻充分展示了CPU和GPU工作的過程。如下面的視頻:
了不起的云計算
,贊
60
可以通過打比方來通俗的解釋二者的區別。CPU就好比一輛跑車,而GPU則相當于一輛貨車,二者的任務都是從A位置將100 Packages運送到B位置,CPU(跑車)可以在RAM中快速獲取一些內存數據(貨物),而GPU(貨車)執行速度較慢(延遲更高)。但是CPU(跑車)每次只能運送2 Packages,需要50次才能運送完成。
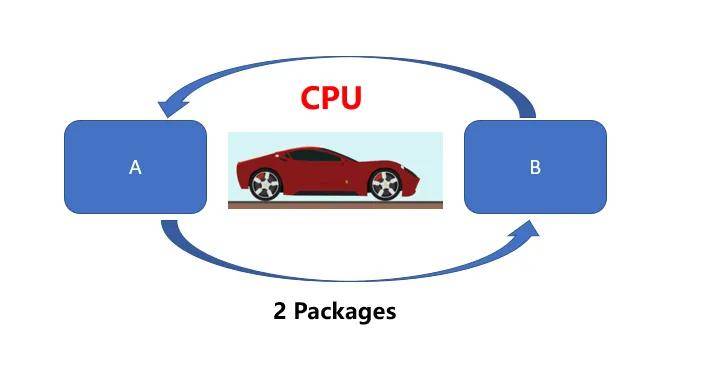
然而GPU(貨車)則可以一次獲取更多內存數據進行運輸。
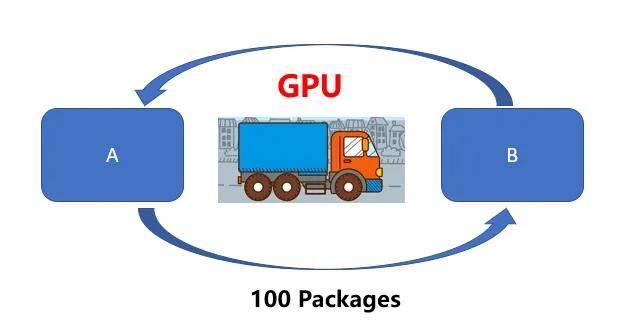
換句話說,CPU更傾向于快速處理少量數據(例如算術運算:5*6*7),GPU更擅長處理大量重復數據(例如矩陣運算:(A*B)*C)。因此,雖然CPU單次運送的時間更快,但是在處理圖像處理、動漫渲染、深度學習這些需要大量重復工作負載時,GPU優勢就越顯著。
目前AI計算的數據類型跟圖像處理,深度學習的類型更相似,這也是導致GPU供不應求的重要原因。
那么是什么CPU和GPU有何不同呢?那還具體來看一下。
▉ GPU和CPU有何不同?
首先是二者架構核心不同
通過下面兩張圖可以有助于我們理解CPU和GPU工作方式的不同。上文中我們提到,CPU是為順序的串行處理而設計的,GPU則是為數據的并行而設計的,GPU有成百上千個更小、更簡單的內容,而CPU則是有幾個大而復雜的內核。
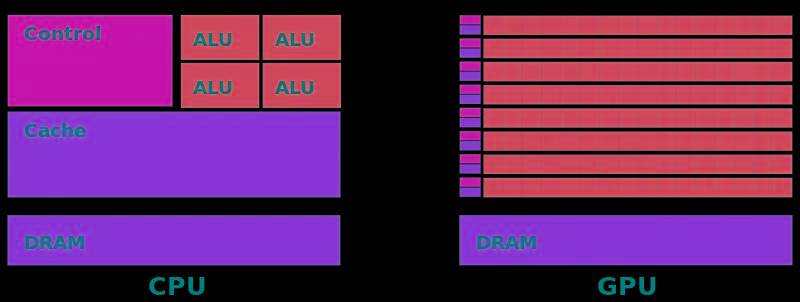
GPU內核經過優化,可以同時對多個數據元素進行類似的簡單處理操作。而且CPU則針對順序指令處理進行了優化,這也導致二者的核心處理能力的不同。
網上有一個比喻用來比較 GPU 和 CPU 核心的區別,我覺得非常貼切,CPU的核心像學識淵博的教授,GPU的核心更像一堆小學生,只會簡單的算數運算,可即使教授再神通廣大,也不能一秒鐘內計算出500次加減法,因此對簡單重復的計算來說單單一個教授敵不過數量眾多的小學生,在進行簡單的算數運算這件事上,500個小學生(并發)可以輕而易舉打敗教授。
其次是內存架構不同
除了計算差異之外,GPU還利用專門的高帶寬內存架構將數據送到所有核心,目前GPU通常用的是GDDR或HBM內存,它們提供的帶寬比CPU中的標準DDR 內存帶寬的帶寬更高。
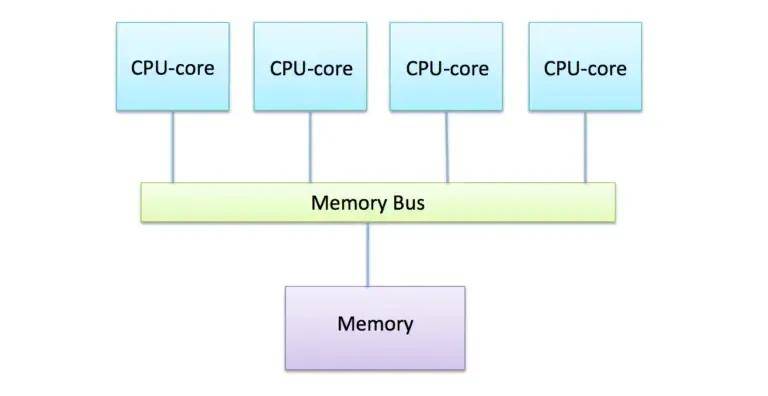
GPU處理的數據被傳輸到這個專門的內存中,以最大限度地減少并行計算期間的訪問延遲。GPU的內存是分段的,因此可以執行來自不同內核的并發訪問以獲得最大吞吐量。
相比之下,CPU內存系統對緩存數據的低延遲訪問進行了高度優化。對總帶寬的重視程度較低,這會降低數據并行工作負載的效率。
第三,是并行性
專用內核和內存的結合使GPU能夠比CPU更大程度地利用數據并行性。對于像圖形、渲染這樣的任務,相同的著色器程序可以在許多頂點或像素上并行運行。
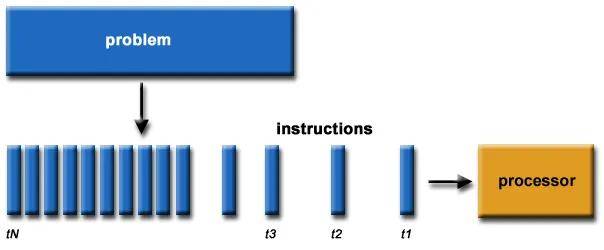
現代GPU包含數千個核心,而高端CPU最多只有不到100個核心。通過更多的核,GPU可以以更高的算術強度在更寬的并行范圍內處理數據。對于并行工作負載,GPU核心可以實現比CPU高100倍或更高的吞吐量。
相比之下,阿姆達爾定律意味著CPU對一個算法所能獲得的并行加速是有限的。即使有100個內部核心,由于串行部分和通信,實際速度也限制在10倍或更低。由于其大規模并行架構,GPU可以實現幾乎完美的并行加速。
第四,是即時(JIT)編譯方面
GPU的另一個優點是即時(JIT)編譯,它減少了調度并行工作負載的開銷。GPU驅動程序和運行時具有JIT編譯功能,可以在執行之前將高級著色器代碼轉換為優化的設備指令。
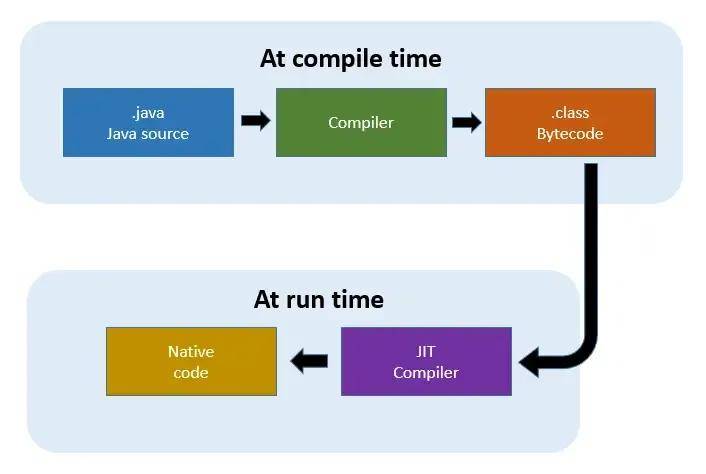
這為程序員提供了靈活性,同時避免了CPU所需的傳統離線編譯步驟。JIT還支持基于運行時信息的優化,綜合效果將GPU開銷降低到幾乎為零。
相比之下,CPU必須堅持預編譯的機器碼,不能根據運行時行為自適應地重新編譯,因此CPU的調度開銷更高,靈活性也更差。
第五,在編程模型方面
與CPU相比,GPU還提供了一個更加出色的并行編程模型CUDA,開發人員可以更快速編寫并行代碼,而不必擔心低級別的線程、同步和通信等問題。
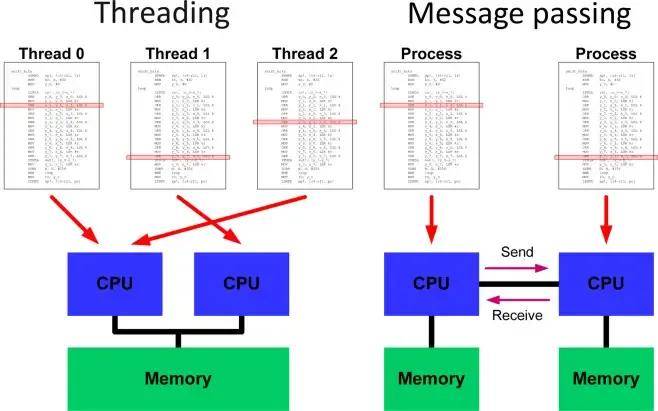
CUDA和OpenCL提供C/ C++編程語言,其中代碼專注于跨抽象線程的并行計算,凌亂的協調細節在幕后被無形地處理。
相反,CPU并行性要求使用OpenMP等庫直接處理線程。在線程管理、鎖和避免競爭條件方面,存在明顯的額外復雜性。這使得從高層考慮并行性變得更加困難。
第六,二者響應方式不同
CPU基本上是實時響應,對單任務的速度要求很高,所以就要用很多層緩存的辦法來保證單任務的速度。
GPU往往采用的是批處理的機制,即:任務先排好隊,挨個處理。
第七,二者的應用方向不同
CPU所擅長的像操作系統這一類應用,需要快速響應實時信息,需要針對延遲優化,所以晶體管數量和能耗都需要用在分支預測、亂序執行、低延遲緩存等控制部分。
GPU適合對于具有極高的可預測性和大量相似的運算以及高延遲、高吞吐的架構運算。目前廣泛應用于三大應用市場:游戲、虛擬現實和人工智能。

另外,GPU還可以應用于自動駕駛、醫療影像分析、金融風控等領域。不過,由于不同應用場景對GPU性能的要求不同,因此在選擇GPU時需要考慮其計算能力、功耗和應用領域等因素。需要根據任務類型選擇最合適的GPU,并進行優化以發揮其性能優勢。
▉ GPU的下一步是什么?
由于內核數量和運行速度的提高,GPU的數字處理能力正在穩步提高。但這些改進主要是由臺灣臺積電(TSMC)等公司在芯片制造方面的改進所推動的。
目前,單個晶體管(任何計算機芯片的基本組成部分)的尺寸正在減小,這使得在相同數量的物理空間中可以放置更多的晶體管。但這并不代表傳統GPU對于人工智能相關的計算任務是最佳的。
正如GPU最初設計是為圖形提供專門的處理來加速計算機一樣,各種加速器也被設計用來加速機器學習任務。由AMD和NVIDIA等公司正在為傳統的GPU制造各種加速器來提供其對人工智能等場景的計算需求,例如NVIDIA CUDA以及AMD的ROCm都能夠為開發者提供了一個全面的環境,用于創建、優化和部署 GPU 加速應用,確保在各種平臺上實現高性能和可擴展性。
除此之外,例如谷歌的張量處理單元和Tenstorrent的Tensix Cores芯片,都是從頭開始設計,被用于加速深度神經網絡。
通常,數據中心GPU和其他AI加速器通常比傳統GPU附加卡配備更多內存,這對于訓練大型AI模型至關重要。人工智能模型越大,GPU的能力就要越強,準確度越高。
為進一步加快訓練速度,處理更大AI模型(例如ChatGPT),研發者可將許多數據中心GPU匯集到一起形成超級計算機。而這需要更復雜軟件方可正確利用可用的數字處理能力。另一種方法則是創建一個非常大規模的加速器,例如芯片初創企業Cerebras生產的“晶圓級處理器”(wafer-scale processor)。
同時,CPU方面的發展并未停滯。AMD和英特爾的最新CPU內置低級指令,可加速深度神經網絡所需的數字運算。這一附加功能主要有助于“推理”任務,即利用其他已經開發的AI模型。
但目前來說,要訓練人工智能模型,首先需要GPU或者類似GPU的大型加速器。
為特定的機器學習算法創建更專業的加速器是可能的。例如,最近一家名為Groq的公司生產了一種“語言處理單元”(LPU),專門設計用于沿著ChatGPT的路線運行大型語言模型。
但歷史表明,任何爆火的機器學習算法都很快地達到頂峰然后式微——因此昂貴的GPU或加速器硬件可能很快就過時。
目前,中國的GPU芯片在市場份額上仍然占據較小的比例,但國產GPU芯片的入局者也越來越多,越來越多的國內企業向圖形處理領域轉型,比如芯動科技、景嘉微等,國產GPU芯片也有了更好的發展機遇。隨著美國實施更多的出口管制措施,或將為"中國芯"崛起制造機會窗口,這可能導致英偉達在中國市場面臨更大的競爭壓力。





