
由清華大學(xué)基礎(chǔ)模型研究中心聯(lián)合中關(guān)村實驗室研制的SuperBench大模型綜合能力評測框架,正式對外發(fā)布2024年3月版《SuperBench大模型綜合能力評測報告》。評測共包含了14個海內(nèi)外具有代表性的模型,結(jié)果顯示:文心一言4.0中文理解、數(shù)學(xué)等多能力全球第一。
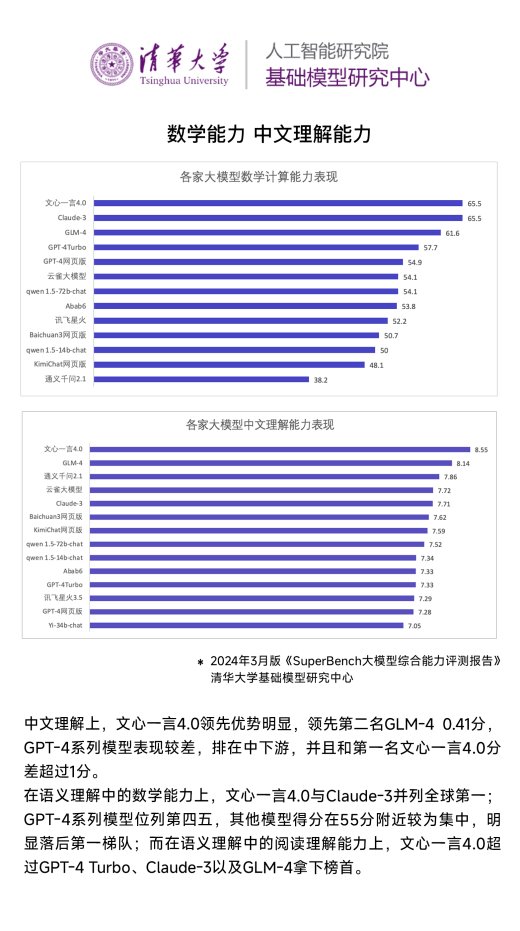
評測顯示,文心一言4.0表現(xiàn)優(yōu)異,在中文推理、中文語言等評測上遙遙領(lǐng)先,和其他模型拉開明顯差距。中文理解上,文心一言4.0領(lǐng)先優(yōu)勢明顯,領(lǐng)先第二名GLM-4 0.41分,GPT-4系列模型表現(xiàn)較差,排在中下游,并且和第一名文心一言4.0分差超過1分。
在語義理解中的數(shù)學(xué)能力上,文心一言4.0與Claude-3并列全球第一; GPT-4系列模型位列第四五,其他模型得分在55分附近較為集中,明顯落后第一梯隊;而在語義理解中的閱讀理解能力上,文心一言4.0超過GPT-4 Turbo、Claude-3以及GLM-4拿下榜首。
在企業(yè)選擇大模型最看重的安全性評測上,國內(nèi)模型文心一言4.0表現(xiàn)亮眼,力壓國際一流模型GPT-4系列模型和Claude-3拿下最高分(89.1分),Claude-3僅列第四。





