擊這里在線咨詢客服")
從去年的“百模大戰(zhàn)”到今年的“優(yōu)勝劣汰”,AI大模型賽道呈現(xiàn)賽馬機(jī)制,不少國(guó)產(chǎn)大模型以GPT-4o為標(biāo)桿快速迭代,在核心能力上持續(xù)趕超。近期,由國(guó)內(nèi)權(quán)威大模型評(píng)估平臺(tái)OpenCompass(司南)公布的CompassArena周榜上,科大訊飛星火大模型連續(xù)三周位列前三,兩次摘得第二桂冠。由于榜單采用專業(yè)用戶投票方式,結(jié)合了用戶對(duì)各款大模型的真實(shí)體驗(yàn),更具客觀性和說服力,含金量十足。
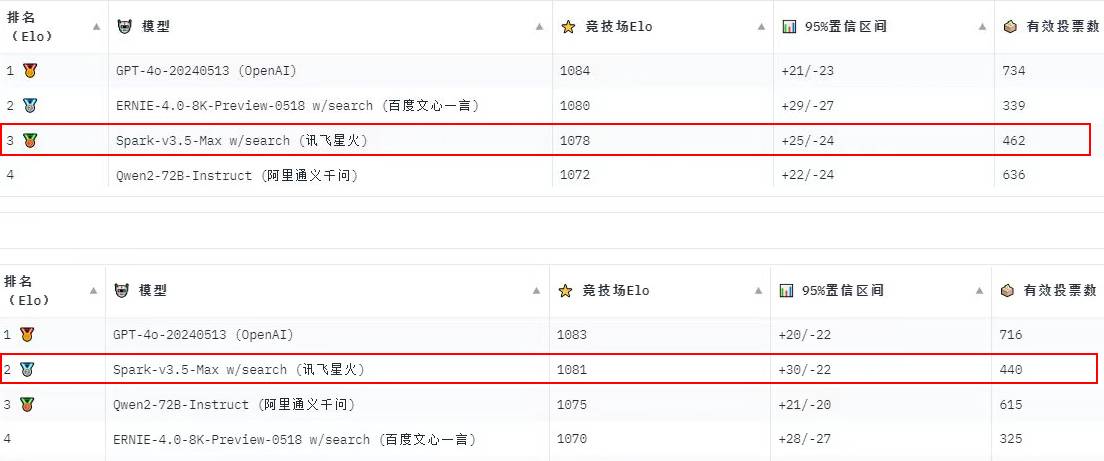
OpenCompass(司南)是由上海人工智能實(shí)驗(yàn)室發(fā)布的開源大模型評(píng)測(cè)體系,目前已成為業(yè)界權(quán)威的大模型評(píng)估平臺(tái),涵蓋學(xué)科、語(yǔ)言、知識(shí)、理解、推理等評(píng)測(cè)維度,可全面評(píng)估大模型的綜合能力。在最新三期專業(yè)用戶投票的周榜評(píng)選中,訊飛星火以Elo-1078和Elo-1081位居前三,榜單前四強(qiáng)還出現(xiàn)阿里通義千問和百度文心一言的身影,它們共同組成了國(guó)產(chǎn)大模型的第一梯隊(duì),不斷向榜單第一名的GPT-4o發(fā)起挑戰(zhàn)。
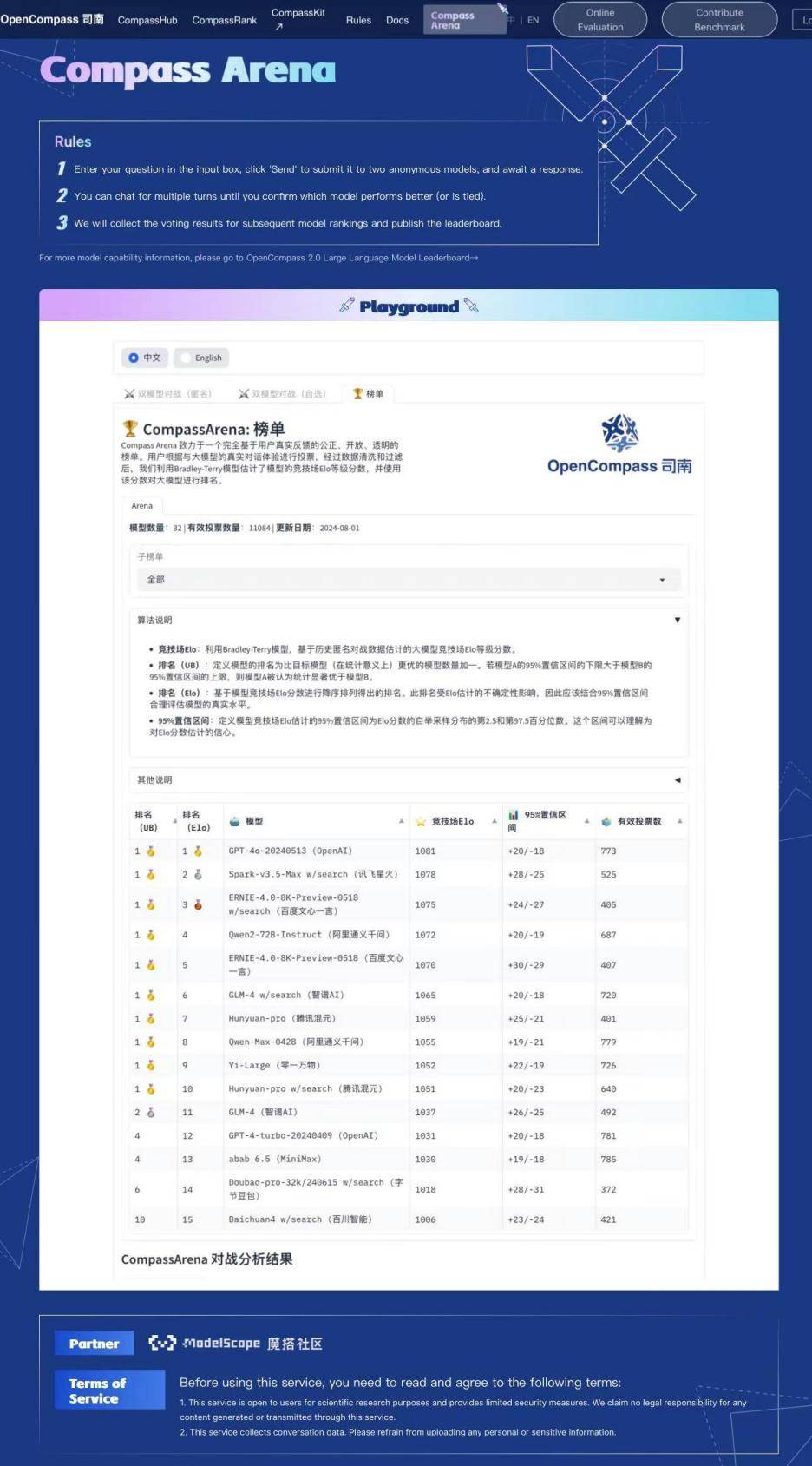
根據(jù)CompassArena榜單排名規(guī)則,平臺(tái)會(huì)利用Bradley-Terry模型,基于歷史匿名對(duì)戰(zhàn)數(shù)據(jù)評(píng)估大模型競(jìng)技場(chǎng)Elo的等級(jí)分?jǐn)?shù),并使用該分?jǐn)?shù)對(duì)大模型進(jìn)行排名。最終數(shù)據(jù)可以公正、開放、透明的反映當(dāng)前各家大模型產(chǎn)品的綜合實(shí)力。
作為明確提出對(duì)標(biāo)OpenAI的國(guó)內(nèi)大模型公司,科大訊飛在今年6月27日發(fā)布的星火V4.0版本上,已完成了對(duì)GPT-4 Turbo的整體超越。根據(jù)八個(gè)國(guó)際主流測(cè)試集的橫向評(píng)測(cè),訊飛星火V4.0排名第一,在文本生成、語(yǔ)言理解、知識(shí)問答、邏輯推理、數(shù)學(xué)能力等方面完成了整體超越。這些測(cè)試集既有HumanEval、WinoGrande、GPQA等英文評(píng)測(cè),也有C-Eval、CMMLU等中文評(píng)測(cè),充分展現(xiàn)了訊飛星火的全方位實(shí)力。
此前,訊飛星火還在國(guó)際權(quán)威的《麻省理工科技評(píng)論》橫評(píng)中脫穎而出,憑借領(lǐng)先的語(yǔ)言能力、數(shù)學(xué)、理綜等多項(xiàng)核心能力,超越了同期的其它國(guó)產(chǎn)大模型選手,并以1013分的總分?jǐn)孬@國(guó)產(chǎn)主流大模型榜首席位。該機(jī)構(gòu)還認(rèn)為,訊飛星火在工作提效方面具有明顯優(yōu)勢(shì),是一款優(yōu)秀的提效類工具。
目前,訊飛星火憑借領(lǐng)先技術(shù)優(yōu)勢(shì)和出色的體驗(yàn),持續(xù)領(lǐng)跑國(guó)內(nèi)大模型第一梯隊(duì)。根據(jù)訊飛星火V4.0發(fā)布會(huì)上公布的數(shù)據(jù),其安卓端APP的累計(jì)下載量已經(jīng)高達(dá)1.31億次,位列國(guó)內(nèi)工具類通用大模型APP第一。更有大量圍繞日常工作、生活與學(xué)習(xí)的實(shí)用助手“源源不斷”地涌現(xiàn),持續(xù)幫助用戶解放生產(chǎn)力,釋放想象力。
歷經(jīng)一年多迭代,訊飛星火快速成長(zhǎng)為國(guó)內(nèi)領(lǐng)先的大模型,對(duì)標(biāo)GPT-4o的下一代版本也在研發(fā)中。隨著核心能力的持續(xù)升級(jí),訊飛星火不僅將穩(wěn)居國(guó)產(chǎn)大模型第一梯隊(duì),更有機(jī)會(huì)成為國(guó)產(chǎn)大模型的代表去對(duì)戰(zhàn)GPT-4o。





