擊這里在線咨詢客服")
來源:雷科技
3月22日,玩家和AI從業(yè)者們又愛又恨的老黃,帶著他的新“核彈”來了。遺憾的是,這次的新“核彈”與玩家沒有太大關(guān)系,主要是針對企業(yè)和工業(yè)市場,與玩家有關(guān)的RTX 40系估計最快也要等到9月份才會有消息。

好了,廢話不多說,讓我們看看老黃這次又拿了怎樣的“大寶貝”出來。首先是A100顯卡的接任者,新一代計算卡皇H100閃亮登場,H100采用全新的Hopper架構(gòu)和臺積電最新的4nm工藝,各方面的參數(shù)對比上一代的A100都有明顯的提升。
英偉達(dá)的超級服務(wù)器芯片Grace也再度曝光,對比上一次給出的數(shù)據(jù),此次曝光的Grace芯片性能有了驚人的提升,根據(jù)發(fā)布會的描述來看,英偉達(dá)似乎也走上與蘋果相同的道路,用更多的芯片拼裝成一顆處理器。
除了硬件方面的產(chǎn)品曝光和發(fā)布,英偉達(dá)在軟件領(lǐng)域同樣帶來了不少新東西,比如主打云端協(xié)作的Omniverse Cloud,讓多名用戶可以在云端直接參與同一個媒體文件的編輯和渲染等工作。
此外英偉達(dá)還展示了不少基于虛擬現(xiàn)實(shí)環(huán)境的工業(yè)、交通模擬案例,還有一套由AI驅(qū)動的虛擬角色系統(tǒng),該系統(tǒng)可以通過深度學(xué)習(xí)進(jìn)行動作訓(xùn)練,訓(xùn)練結(jié)束后不需要額外的骨骼動作設(shè)計等操作就能夠依照指令做出對應(yīng)動作,這下不僅是AI從業(yè)者狂喜,電影及游戲從業(yè)者也要狂喜。
不得不說,老黃這次帶來的東西并不少,每一樣都能對AI等行業(yè)的發(fā)展帶來明顯的改變,下面我們就來詳細(xì)的看看英偉達(dá)到底都發(fā)布了什么吧。
H100與Grace
從去年開始,就有消息稱英偉達(dá)將會在今年發(fā)布新一代計算卡,并且將用上全新的Hopper架構(gòu)。目前來看消息準(zhǔn)確的,只不過當(dāng)初大家猜測新一代計算卡將采用臺積電5nm工藝,但是如今看來英偉達(dá)選擇一步到位使用了最新的4nm工藝,雖然本質(zhì)上是5 nm+,但是在功耗方面則有著更好的表現(xiàn),而且也可以集成更高的晶體管。
實(shí)際上,從H100的核心規(guī)格來看,也不難理解為什么英偉達(dá)最終選了4nm,高達(dá)800億的晶體管集成度,比上一代A100多了整整260億個,內(nèi)核數(shù)量則是提高到了16896個,這是目前世界上內(nèi)核數(shù)量最高的芯片核心,同時也是上一代100的2.5倍。

夸張的內(nèi)核參數(shù)提升帶來的性能提升也極為夸張,根據(jù)英偉達(dá)官方給出的數(shù)據(jù),H100的浮點(diǎn)計算和張量核心運(yùn)算能力將比上一代提升至少3倍,F(xiàn)P32高達(dá)60萬億次/秒,而上一代的A100為19.5萬億次/秒。
H100還將是首款支持PCIe 5.0和HBM3,讓內(nèi)存帶寬達(dá)到驚人的3TB/s,老黃表示只需要20張H100就可以處理目前全球的網(wǎng)絡(luò)流量,雖然聽起來很夸張,但是確實(shí)體現(xiàn)出了H100夸張的性能參數(shù)。
強(qiáng)大性能也伴隨著夸張的功耗,英偉達(dá)給出的H100功耗高達(dá)700W(真正意義上的“核彈”顯卡),作為對比上一代A100的功耗僅400W,不過用2倍的功耗換來3倍的性能提升,整體來說也不虧。
H100還針對AI訓(xùn)練等所要用到的模型進(jìn)行針對性優(yōu)化,為Transformer搭載了優(yōu)化引擎,讓大模型的訓(xùn)練速度可以提升至原來的6倍,極大的降低了大型AI模型等訓(xùn)練所需要的時間,這個特性也與下面將會談到的AI虛擬角色系統(tǒng)相呼應(yīng)。
在英偉達(dá)給出的測試數(shù)據(jù)中,訓(xùn)練一個擁有1750億參數(shù)的GPT-3模型,時間將由原來的一周降低到僅需19小時,而一個擁有3950億參數(shù)的Transforme模型也僅需21小時就可以完成訓(xùn)練,效率提升近9倍。
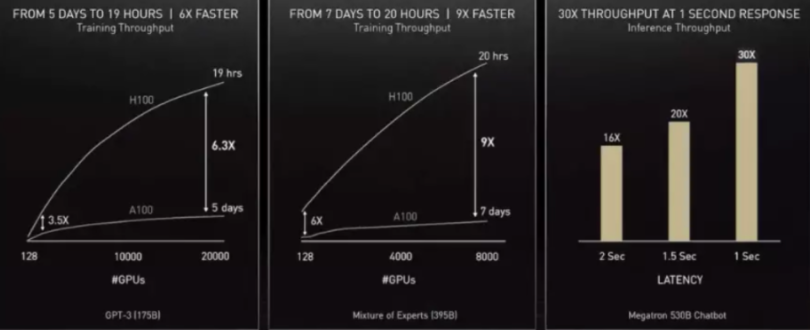
雖然參數(shù)看起來十分美好,但是實(shí)際的性能表現(xiàn)如何還有待后續(xù)的實(shí)際測試結(jié)果來揭曉,至少從RTX 30系和A100的經(jīng)驗來看,最終的實(shí)際性能提升幅度可能在2倍-2.5倍之間,不太可能真的達(dá)到3倍,不過即使只有2倍提升也已經(jīng)相當(dāng)出色,至少在AI方面已經(jīng)完全碾壓了AMD的計算卡。
而且,H100還引入了英偉達(dá)最新的NVIDIA NVLink第四代互連技術(shù),該技術(shù)能夠進(jìn)一步提升多GPU串聯(lián)的效率,在英偉達(dá)給出的數(shù)據(jù)中,串聯(lián)后的I/O帶寬能夠擴(kuò)展至900GB/s,比上一代提升了50%。
再來看看英偉達(dá)的新“玩具”Grace,這是英偉達(dá)為服務(wù)器業(yè)務(wù)準(zhǔn)備的超級服務(wù)器芯片,此前就有過不少的曝光,這次則是有了更多的信息,同時還帶來了全新的系列產(chǎn)品。Grace芯片采用最新的Arm V9架構(gòu),英偉達(dá)以此為基準(zhǔn)打造了兩款超級芯片——Grace Hopper和Grace CPU超級芯片。
其中,Grace Hopper由一個Grace CPU和一個Hopper架構(gòu)的GPU的GPU組成,兩者將會形成一個完整的運(yùn)算系統(tǒng),只需要一顆芯片就可以搭建出一個強(qiáng)大的運(yùn)算服務(wù)器,同時也可以將多個芯片串聯(lián)起來組成更龐大的運(yùn)算陣列。

而Grace CPU超級芯片則是由兩顆Grace CPU組成,兩顆芯片通過NVIDIA NVLink-C2C技術(shù)互連,組成一個內(nèi)置了144個Arm核心并且擁有1TB/s內(nèi)存帶寬的巨無霸級芯片(Grace CPU Ultra?)。

說實(shí)話,英偉達(dá)的這顆Grace CPU超級芯片很難不讓人聯(lián)想到蘋果在春季發(fā)布會上發(fā)布的M1 Ultra,同樣是基于Arm架構(gòu),同樣是由兩顆芯片組合而成,同樣也有著夸張的內(nèi)存帶寬和性能表現(xiàn)。
顯然,芯片互聯(lián)拼裝技術(shù)已經(jīng)成為行業(yè)的趨勢之一,AMD方面也曝光有采用類似技術(shù)的CPU正在研發(fā)中,最早將在2023年與大家見面。只能說如今單顆芯片的性能發(fā)展已經(jīng)接近極限,接下來想要擁有更大的提升,或許將不得不借助類似的互聯(lián)技術(shù)進(jìn)行芯片堆疊了。
不過,Grace CPU超級芯片的功耗并不低,英偉達(dá)官方給出的數(shù)據(jù)是500W,已經(jīng)遠(yuǎn)遠(yuǎn)超過了傳統(tǒng)的x86架構(gòu)CPU,當(dāng)然,考慮到Grace CPU超級芯片的夸張性能:SPECrate跑分740分,較第二名提升60%,這個功耗也不是不能接受。
顯然,在Arm服務(wù)器領(lǐng)域,英偉達(dá)的野心是非常大的。
英偉達(dá)的虛擬世界
除了一堆高性能的硬件,英偉達(dá)此次也展出了不少的軟件示范案例,其中就包括使用H100等硬件來模擬一個虛擬現(xiàn)實(shí)環(huán)境,用以進(jìn)行各種測試和模擬。在英偉達(dá)的示范中,未來的企業(yè)可以通過強(qiáng)大的英偉達(dá)硬件構(gòu)建一個擬真的虛擬測試環(huán)境,并在其中測試自動駕駛、智能工廠的運(yùn)作等。
通過虛擬測試環(huán)境的使用,研究者可以更輕松的測試自動駕駛面對各種突發(fā)狀況時的反饋,并且在測試中直接定位問題,降低整體的測試成本。此外,還可以構(gòu)建一個1:1的“數(shù)字化工廠”提前模擬運(yùn)行,尋找提高效率和找到可能出現(xiàn)的問題,降低工廠正式運(yùn)行后出現(xiàn)問題的概率。

英偉達(dá)將這一套應(yīng)用稱為“數(shù)字孿生”,能夠大幅度降低自動化工廠和自動駕駛等方面的研究及測試投入。
Omniverse Cloud是英偉達(dá)新推出的一款云端創(chuàng)作服務(wù),用戶通過Omniverse Cloud可以在任意地點(diǎn)訪問和編輯大型3D場景,并且無須等待大量數(shù)據(jù)的傳輸,并且還可以讓用戶能夠直接在線協(xié)作共同搭建3D模型。
在過去,3D模型和3D場景的協(xié)同構(gòu)建都需要在一個服務(wù)器上進(jìn)行,而在Omniverse Cloud推出后,相關(guān)創(chuàng)作者就可以通過任意支持Omniverse Cloud的終端,直接用網(wǎng)絡(luò)訪問協(xié)作空間并參與其中,極大的提升了創(chuàng)作者的響應(yīng)速度和工作自由。
另外,英偉達(dá)還為創(chuàng)作者們準(zhǔn)備了第二個驚喜,一套由AI驅(qū)動的虛擬角色系統(tǒng),該系統(tǒng)可以讓AI在短時間內(nèi)完成訓(xùn)練,學(xué)會各種指令所對應(yīng)的動作。比如一個簡單的劈砍動作,在正常的制作流程中首先需要動作架構(gòu)師通過對動作骨架的一步步調(diào)整(俗稱K幀),然后再放到場景中進(jìn)行測試,整個流程需要耗費(fèi)大量的時間,而且每個不同的動作都需要重新進(jìn)行調(diào)試。

而在這套AI虛擬角色系統(tǒng)的幫助下,當(dāng)你想要虛擬模型做出劈砍的動作,只需要一條指令,AI就會從已學(xué)習(xí)的動作中找出關(guān)聯(lián)動作并自動運(yùn)行,直接節(jié)省了大量的時間和人力,對于游戲開發(fā)者和特效制作者而言,這個系統(tǒng)將讓他們能夠?qū)⒏嗟木Ψ旁谄渌胤健?/p>
英偉達(dá)的此次發(fā)布會,雖然并沒有太多的提到元宇宙,但是從硬件到軟件都是未來構(gòu)建元宇宙的基礎(chǔ)。目前元宇宙無法成為現(xiàn)實(shí)的原因主要是兩點(diǎn),一個是硬件性能無法滿足我們的需要,另一個就是軟件領(lǐng)域尚不成熟,無法提供實(shí)時的擬真環(huán)境模擬,而這兩者是點(diǎn)亮元宇宙科技的基礎(chǔ)。
在此之前,我們首先需要的就是更強(qiáng)大的計算硬件及更智能的AI系統(tǒng)。英偉達(dá)的H100,虛擬現(xiàn)實(shí)環(huán)境及AI虛擬角色系統(tǒng)的出現(xiàn),將讓我們朝著真正的元宇宙再邁進(jìn)一大步。





