
逐漸增多的聯網設備設施,如果不對其產生的海量數據進行治理或分析,僅僅對單獨某個企業個體而言,或許都將釀造一場數據災難。
反之,擅用數據治理并擁有大數據能力的企業,他們的財務表現、做出決策的速度和正確性,都將遠遠超過競爭對手。
近年工信部密集發布《工業數據分類分級指南(試行)》、《關于工業大數據發展的指導意見》、《關于組織開展2021年大數據產業發展試點示范項目申報工作的通知》等政策通知,旨在提升企業數據治理能力,打造應用繁榮、產業進步的大數據生態體系。
企業們在從傳統模式轉變到數字化模式一段時間以后,也開始從底層資源需求進階到數據層需求,他們希望把獲取到的數據盤活,對數據價值進行利用,甚至創造新的業務模式。
數據治理的戰略地位得到提升。根據賽迪顧問預測,2023年我國大數據產業規模將超過萬億元,2027年將達到1.8萬億。大數據產業鏈組成豐富,政府機構、技術和產品服務商、場景運營方陸續加入玩家陣營。
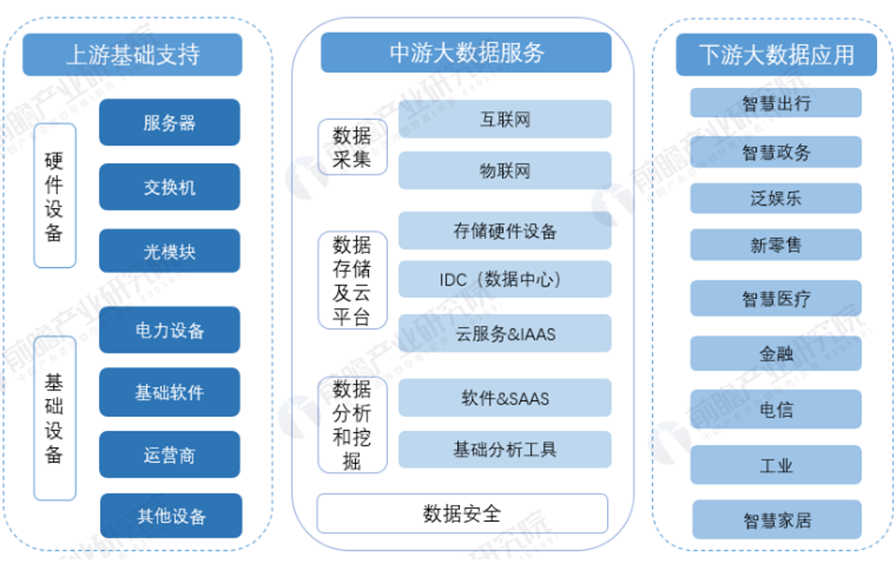
大數據產業鏈,來源:前瞻產業研究院
從2014年發布第一款數據產品開始,青云科技便緊跟行業趨勢和客戶需求,配備近百人的研發團隊,持續推出了近30款數據產品和服務,涵蓋數據庫與緩存、消息隊列與中間件、對象存儲、大數據服務、數據倉庫和BI,為百行千業的客戶提供優質服務。
近日,青云正式發布“大數據工作臺”產品,目標在于幫助企業打通大數據全鏈路,從海量數據中提煉出最有價值的信息和知識,輔助業務決策和創新。在物聯傳媒記者向青云QingCloud大數據產品經理劉雄風的提問溝通中,我們進一步看懂了關于大數據的趨勢,以及青云大數據工作臺發布的意義所在。

一個工廠一天產生2.6億條數據
互聯網時代,大數據分析最常見的用途是了解用戶的使用習慣、消費偏好、行為特征等,從而做出個性化推薦。并且互聯網大數據對時效沒有太高要求,主要是從長期積累中找出關聯性。
物聯網應用與此不同。數據集成、實時計算分析、統一監控和調度是普遍需求,數據越完整、越全面、反饋實時性越高,企業降本增效的效果就越好。
但物聯網數據治理并非易事。
某中國環保行業的領導者,旗下每個工廠分別部署3000多個數據采集點,每個工廠每秒傳送數據0.5MB,每天傳送數據大小為38GB,數據量為2.6億條。將情況復制到集團21個工廠,一天的數據量達到54億條、798GB,保留6個月的數據總量將高達9720億條、140TB。
數據量大不是唯一特點,很多場景下的數據源更顯多樣化。
某行業領先的工業自動化測試設備與整線系統解決方案商,其數據源涵蓋生產相關設備,如機加工設備、SMT設備、AGV、立庫、質檢等相關設備,以及生產外運營相關的IoT設備,如水電氣、空調暖通、給排水、道閘門禁、溫濕度傳感器終端等,具有非常強的多樣性。
再加上各類設備數據的采集頻次、數據留存時間各不相同,需要應用不同的采集策略。
另外在工業、能源等諸多對安全、保密性有要求的場景,其網絡環境屬于高度隔離狀態,數據采集點位于企業工控網,不允許外部訪問,這將為數據治理帶來新的難度。
總而言之,數據治理值得被重視,且相比于安排專門崗位來計算日常的數據產出、支付這項額外的人力成本,仍然可以將精力專注在核心業務開發上。
按照青云的介紹,一般客戶數據量達到GB級別,就具備了使用大數據工作臺的條件。對于客戶關注的成本問題,青云大數據工作臺在復雜場景下,每CU(Computing Unit,1CU含計算資源:1核CPU,4GB內存)每秒可以處理3000條至1.5萬條數據,每CU計費模式為0.4元/小時,并且目前青云大數據工作臺產品處于公測階段,支持免費開放使用。
客戶厭煩具有“割裂感”的產品
站在客戶的角度,大數據的價值不是數據本身,而是背后隱藏的對業務有影響的信息和知識。大數據產品的內涵也不在簡單堆疊Hadoop、Spark和Flink等產品組件,客戶更加希望有獨立的實時計算平臺,且平臺能帶來良好的使用體驗。
基于這一點,青云在提供大數據工作臺產品的基礎上,將其與KubeSphere容器平臺和IoT平臺形成合力,充分發揮各自優勢,組建了完善的“大數據工作臺+KubeSphere+IoT”三位一體技術方案。
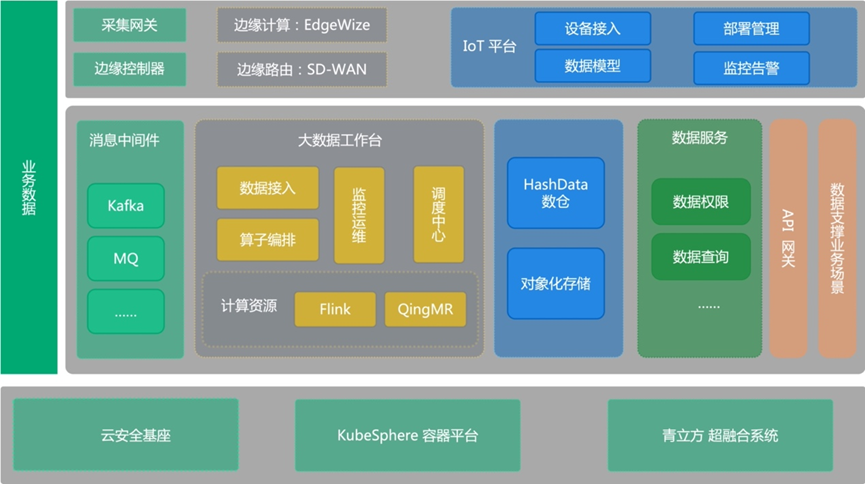
“青云大數據工作臺+KubeSphere 容器平臺+IoT 平臺”三位一體技術方案
方案架構上,最上層是物聯網平臺,中間是大數據平臺,最底層是容器平臺。
在容器平臺層,提供按需使用、彈性伸縮、一鍵擴容、在線運維的功能保障。
在大數據平臺層,結合消息中間件、數據倉庫、數據服務等云原生產品組件,從橫向數據流方面提供一站式的數據實時處理和輸出能力;
在物聯網平臺層,形成“云、網、邊、端”統一管理、統一數據采集和統一邊緣控制。
這再次證明青云大數據工作臺出于打通大數據全鏈路的初衷而建立,在整合大數據相關產品及服務后,為客戶提供一站式智能大數據開發與治理平臺,并具有6點突出特性:
第一,開箱即用。公有云環境下幾分鐘即可完成環境的創建和部署,即開即用、便捷高效。在私有云的部署一般是半天或一天時間完成,且仍在進行一鍵部署的優化。
第二,彈性擴容。具備云原生彈性擴容的能力,可以幫助客戶合理地節省資源,提高資源的使用率。通過提供細粒度管控,最小資源使用的粒度只需要0.5CU,支持按量、包年包月計費,可以更好地適配不同的需求,價格低廉,安全穩定。
第三,存算分離。與青云的對象存儲服務無縫銜接,海量數據可以高效、低成本的存儲。同時支持數據計算按需擴容,極具性價比。
第四,開放兼容。擁抱開源,百分百兼容Apache Flink,支持平滑上云,通過內嵌的Connector可以無縫對接主流的數據產品和開源大數據生態組件。同時,客戶可以將原有的大數據任務遷移到青云大數據工作臺上,進行統一的調度和監控,節省運維和調度成本。
第五,安全可靠。按照云原生的架構模式進行設計,可以基于多種基礎設施進行部署。內部按照功能模塊以微服務的方式劃分為多個組件,彼此之間相互隔離,避免相互影響。同時,所有的服務都具備高可用和高擴展能力,可以在部分節點故障的情況下,保障服務的可用性和數據的可靠性。
第六,生態整合。除了青云大數據工作臺本身提供的服務外,還可以在云上與其他產品緊密整合,可以連通云平臺上孤立的多種數據存儲的服務,讓客戶在云平臺上的數據流轉更加便捷。
目前上線的青云大數據工作臺1.0版本,主要滿足數據存儲、數據加工、統一存儲和服務功能,下一階段將在數據治理、數據資產、優化體驗等方面滿足更高級別需求。
沒有歷史包袱非常關鍵,專注滿足業務訴求
青云此次推出大數據工作臺的時間不算早,市面上互聯網背景的公有云廠商及通用大數據公司都已在開拓該市場,他們產品的特點大致如下所示:
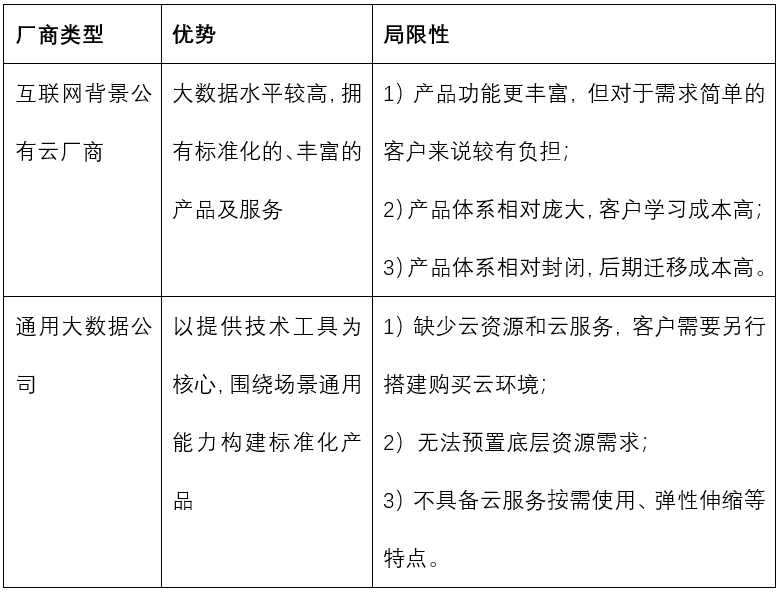
而從此次青云發布的大數據工作臺來看:
與互聯網背景的公有云廠商相比,青云大數據工作臺基于云原生架構,可以部署在開源的Kubernetes容器平臺上,也能部署在其他云原生產品上,這對客戶來說更加開放和包容,避免了被云廠商綁定。
同時,青云大數據工作臺的界面及功能上沒有歷史包袱,包括支持提供流批一體的Flink引擎,使客戶能更輕松完成對計算集群的創建、管理和銷毀,讓客戶將精力更聚焦在業務計算本身。
另與市面上的通用大數據公司相比,青云大數據平臺產品可依托云計算屬性,提供快速反饋和更新的能力,并且支持彈性計費和靈活擴容。
同時,相較于目前主流的企業數據中臺,青云大數據大數據工作臺沒有基于傳統的Hadoop體系的YARN來做資源調度,而是基于Kubernetes做資源調度,聚焦于數據使用場景下,解決數據集成、流批一體計算、統一運維和統一數據服務共享的問題,通過一站式、便捷低成本的方式,幫助中小企業快速掌握數據價值,構建“云上數據中臺”。
當然,大數據市場規模龐大,每類產品都有其主要受眾并且可能面向不同的場景領域。
青云大數據工作臺將面向4類場景提供服務,分別為:
精細化運營分析場景,包括用戶畫像、推薦、數據分析、大屏展示、數據治理等場景,主要受眾為中小型互聯網或移動互聯網公司。
實時計算場景,包括IoT終端實時數據分析、實時用戶日志分析、實時運營數據分析、實時風控等,主要受眾為智慧工業、智慧零售等對實時數據有加工處理需求的企業。
可視化開發與運維場景,包括數據ETL、數據挖掘等場景,主要受眾為以學習或科研為目標的客戶。
構建數倉場景,包括數據集成、實時或離線計算、數據存儲等場景,主要受眾為青云云平臺上使用了消息隊列、數據庫、數據倉庫、大數據計算存儲的客戶。
至此,青云大數據工作臺的核心面貌得到呈現。
倘若再回到文章開頭提及的大數據趨勢一問,答案已經不言自明:在企業數字化轉型的道路上,青云正在用專業技術研發和深入市場研究的實際行動,助力企業挖掘珍貴的數據資產,掌握潛力無限的數據價值。





