
“哪些業務需求可以數字化?”
“數據科學只是單純的技術問題?”
“數據科學家的最大的挑戰是什么?”
第四次工業革命來臨,許多企業已經意識到了要利用數據科學能力推動商業模式的創新,嘗試將經營中產生的數據轉化為適配業務需求的決策模型,由原本依靠經驗的“人治”變為“數治”。
數據科學的應用領域同數據科學領域本身一樣多樣化,但成功突圍的卻是少數。“數據智能項目很難達到目標,90%的立項,最后只能草草收場。”
越是艱難,越是能讓這些項目形成企業能力上的核心資產。任何企業都會產生數據,但數據本身不是萬靈丹,它只是加速器,方向盤仍舊掌握在人的手中。
截至2021年,和鯨已經幫助了七個行業的 Top3 客戶完成了數據智能的價值落地。將協同能力的內核落實到數據科學開發的全流程中,和鯨的經驗或許能幫助大家揭開數據科學的圖景。我們邀請了和鯨科技創始人兼 CEO 范向偉先生,對大家常提出的問題進行了統一回答。

和鯨科技創始人 范向偉
01 數據智能項目的兩個挑戰
問:過去5、6年,大數據經歷了一個高峰,也經歷了一個低谷。高峰期在16-17年,市面上最貴的工程師都投身于人工智能,而低谷也就是過去兩年,人工智能主流的公司在上市過程中遇到了很大的挑戰。一個現象就是,大部分人工智能項目都賺不到錢,對此您怎么看?
范向偉:現象確實存在。無論是在乙方還是在甲方內部,目前人工智能相關項目評估下來的 ROI 都很低。數據智能項目普遍達不到立項的目標,這個比例在90%,相信接觸過相關項目的小伙伴都會有一些比較感同身受的經歷。
和鯨作為數據科學平臺,其實也做過各方面調研,我們歸納下來認為,大部分數據智能項目都面臨著兩個挑戰,是導致項目失敗的常見原因。
一個在供給側,一個在需求側。
供給側,為企業數據能力負責的數據工程師或者算法科學家,都會去構建一個基礎設施的金字塔結構,也就是保證底層的技術平臺盡可能穩固、標準、可拓展,從而可以處理更多數據,產生更高計算效率。然后再一層層往上疊,將這個能力轉化為更低的服務成本,去支撐更多需求場景。這是對數據工程師的挑戰。
而需求側,目前幾乎所有可以用 KPI 描述業務的部門,都會給數據部門提需求,需求場景是指數級上升的。但100個需求場景中,合理的比例,可能只有10%,剩下的90%,是因為他缺乏業務的思路,單純想看到更多數據報表,這就會導致需求描述不清楚。所以這是對業務人員的挑戰。
這樣的結構,導致數據智能項目,往往很難讓做數據的人和用數據的人看到進展,因為它是一個非線性爬坡的過程,你不知道是在哪里被卡住了。需求本身不確定,用什么樣的數據也不確定,往往還不知道自己哪里做錯了,項目就被叫停了。
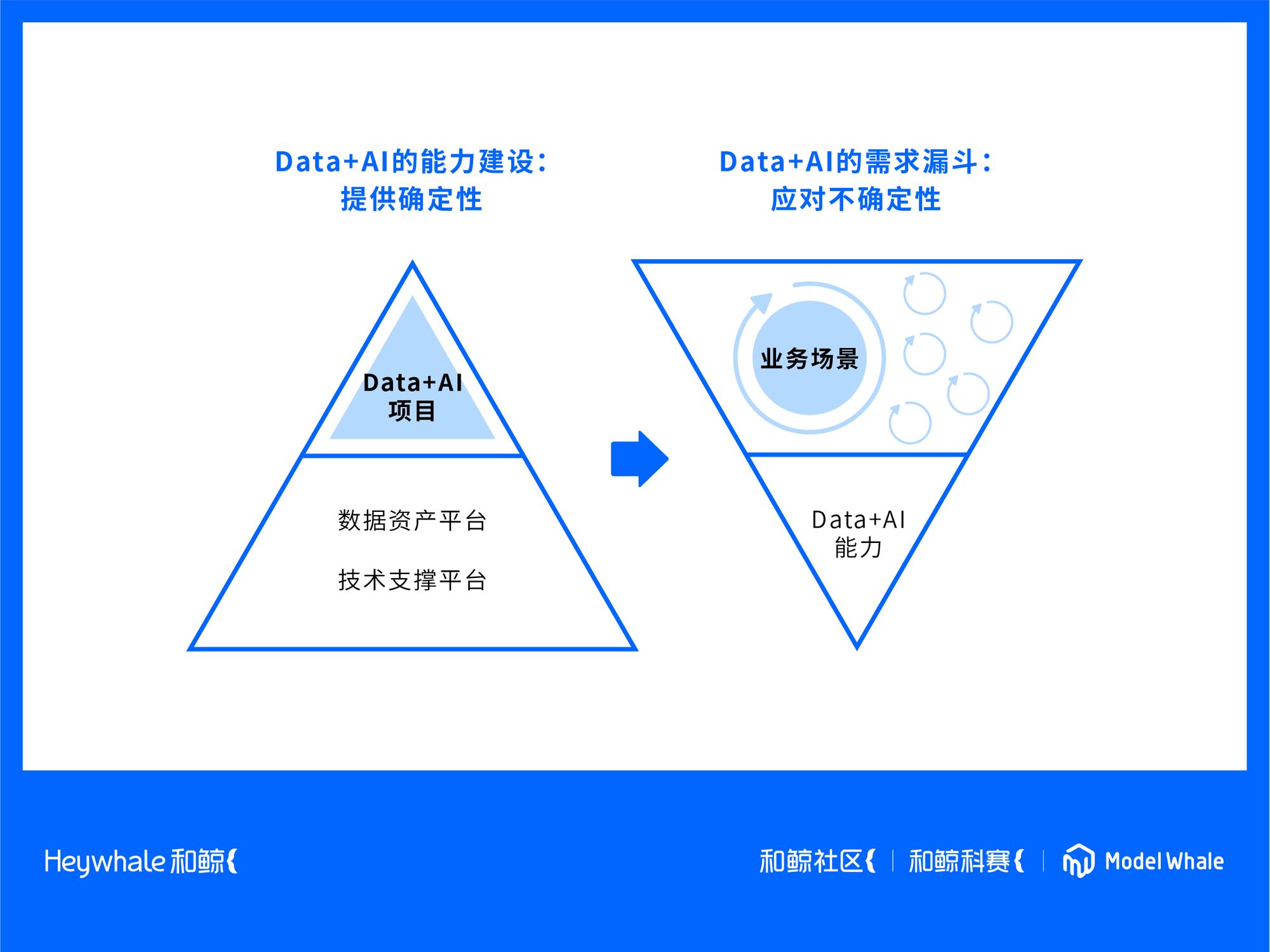
供給與需求的結構性矛盾
這兩個挑戰帶來的結果是什么?
一個是更高的工程成本,或者說指數級的工程成本。要搭建起金字塔結構,工程師將面臨著大量跟機器學習、數據分析無關的基礎工作、協調工作要處理 ,需要大量時間投入。與此同時,系統搭建起來后跑模型,模型結果不好的原因也有很多,而且相互影響、相互嵌套,導致排查、調試的時間成本是指數級上升的。
另一個結果,可以概括為更不確定的業務需求。既然業務鏈條中的各種問題都會找到數據部門,那數據部門到底怎么設計數據平臺的架構、怎么積累算法模型的能力、怎么安排時間,就類似于是個風險投資問題了。數據智能項目的 ROI 符合冪律分布(Power Law)——極少數項目產生的價值非常大,而大部分項目幾乎不產生價值。它就要求數據科學家一定要非常慎重地去做需求分析,如果業務方無法清晰地陳述自己的需求,就很可能是偽需求。
所以這兩個挑戰直接導致企業中供給和需求存在著結構性的錯配,數據部門跟業務部門常常相互不滿意。業務部門想要提需求,但很難把數據智能的需求說清楚,數據權限都拿不到,或者找不到合適的數據。又因為需求不清楚,成功率不高,企業不愿意投入資源,拿不到資源,也很難完成模型的打磨。數據智能的落地,就陷入了需求不清晰、供給低質量的惡性循環。
02 從數據到業務應用的反饋閉環
問:既然供給側和需求側存在著錯配,那讓它重新形成回路是不是就能解決這些問題了。放到實際工作場景中,供需雙方該如何去做呢?可以通過彼此多“溝通”解決嗎?
范向偉:如何去做,基本原則很簡單,就是按照敏捷開發的原則,把大回路拆成小回路,最重要的是,要跟業務部門掰扯清楚,業務到底想回答什么問題,要搞清楚這個事情到底有沒有價值。
這是一門很大的學問,我們觀察下來,大部分數據工程師都不喜歡干這個事情,不喜歡進行需求的爭論和探究。但這件事又很重要,我們自己認為,一個項目70%的成敗與否都取決于這個需求是不是一個真實的需求、重要的需求。
因為和工程相關的工作,在過去幾年已經越來越成熟了,包括現在也出現了大模型,自動化調參、分布式訓練的方案,這里面的平均水準越來越高。更大的問題還是在于,大部分業務需求的質量還是很低,很少有業務人才能夠把自己的數據需求、算法需求給理清楚。
一個是需求的質量,一個是數據的質量,這兩塊現在在 AI 的實踐中問題很大。不管多優秀的算法科學家,在這兩段都容易掉到坑里面去。我們能建議的,就是在實戰中,數據工程師可以更多地去關注,或者說多想一想 Power Law 分布——到底這個需求有沒有前途,或者說需求方到底有沒有想清楚。數據智能在企業中表現出的是需求的流轉,在各個業務部門都會提需求的情況下,數據科學家一定要看到整一個的大畫面,要能夠在需求之間進行比較和取舍。
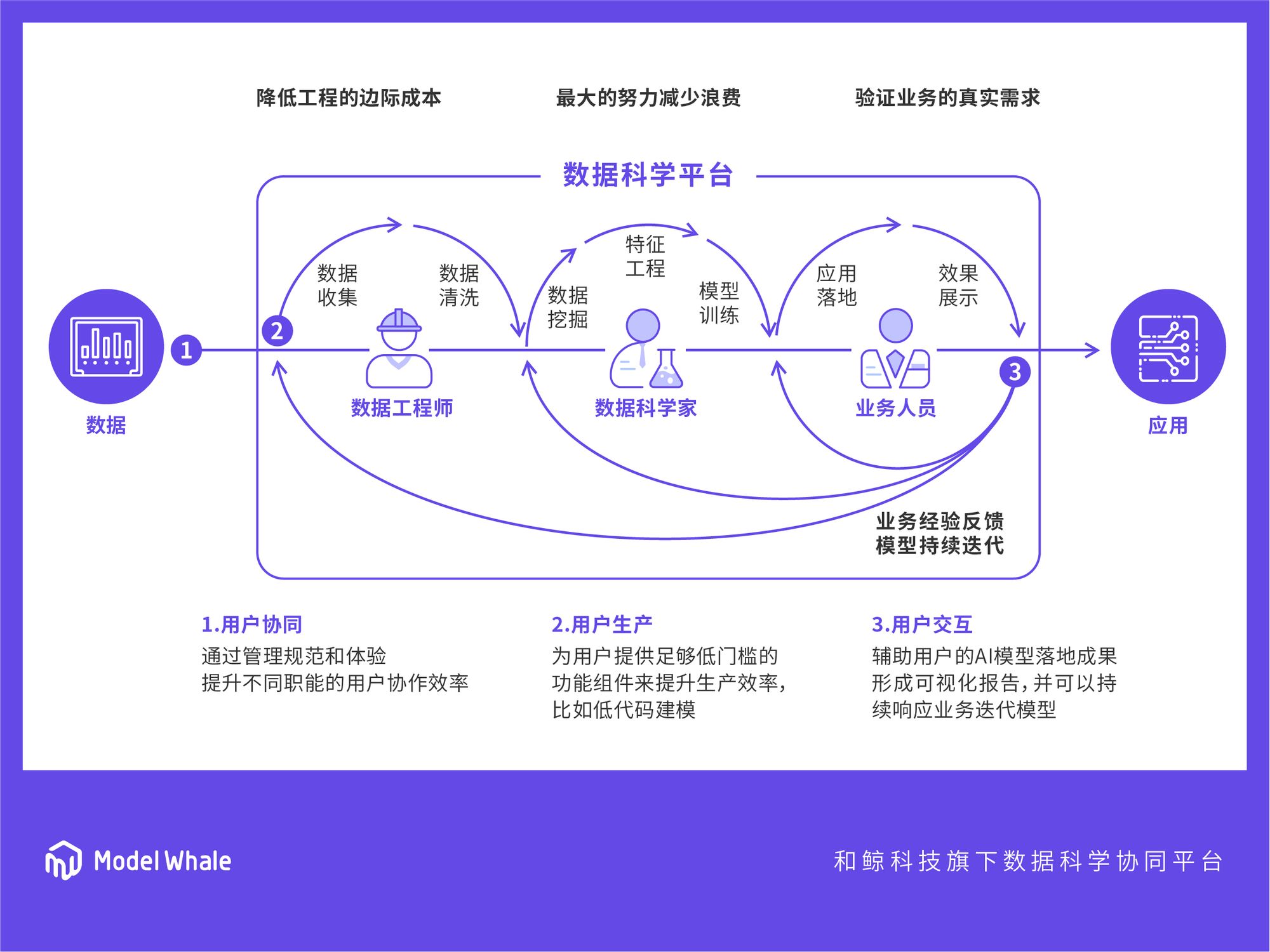
從數據到業務應用的反饋閉環
不過即使這樣,想實現從數據到業務應用的反饋閉環,還是很困難。早在2016年,我們和拍拍貸、攜程、百度等企業合作算法比賽的過程中,就發現了這個問題。業務需求溝通成本高,開發環境搭建、模型成果復用難度大,整個鏈條存在著驚人的浪費。模型開發、模型評價、模型落地的三個環節,彼此間是斷裂的。
這不是光靠“溝通”就能解決的問題。數據科學家普遍都很聰明,但工作流程卻很原始,效率很低。不僅僅是重復造輪,更像是“科學家在開拖拉機”。
所以這也是和鯨產品的協同理念最開始形成的原因,就是把數據工具的開源化,和開發工具的協同化,這兩個趨勢結合起來。
03 三位一體:社區、賽事、工具
問:您說到了協同,我們知道協同其實是所有的生產力工具的核心價值,任何 SaaS 產品,都需要考慮協同作為一種核心能力、核心體驗。大家能理解協同的重要性,但數據科學場景下的協同有什么特殊之處呢?實現起來的難點又在哪里?
范向偉:特殊之處,可能就是跟其他場景相比,數據科學的協同更加難以實現吧。
其實 SaaS 的協同都不好設計,看似簡單的場景,做深了都是在考驗產品團隊的世界觀。只是數據科學這件事會更難,要讓數據、鏡像、算力、模型、圖表、文檔等各個要素,在任務的各個階段,被企業的各個角色,在業務的各個場景,都能夠安全、可控、友好地被接入、被使用、被分享,這對于產品設計來說,幾乎是一個不可能完成的任務。
和鯨也不是天生就有對數據科學用戶和場景的敏感度的,我們在社區中天天和用戶泡在一起,才看到了別人看不到的問題。社區、賽事、工具三位一體的商業模式就是和鯨自身最獨特的協同能力,支撐著我們的協同產品 ModelWhale 有更高的研發效率、觸達效率。
和鯨應該是在數據公司里面,很少能把 PLG 模式運轉起來的公司,這個模式對于企業的要求很高,需要有足夠多的用戶,足夠好的產品體驗,還要有足夠強的企業級價值。否則很容易陷入,有用戶,但是沒有收入,或者有收入,但是沒有增長的兩種怪圈里面。
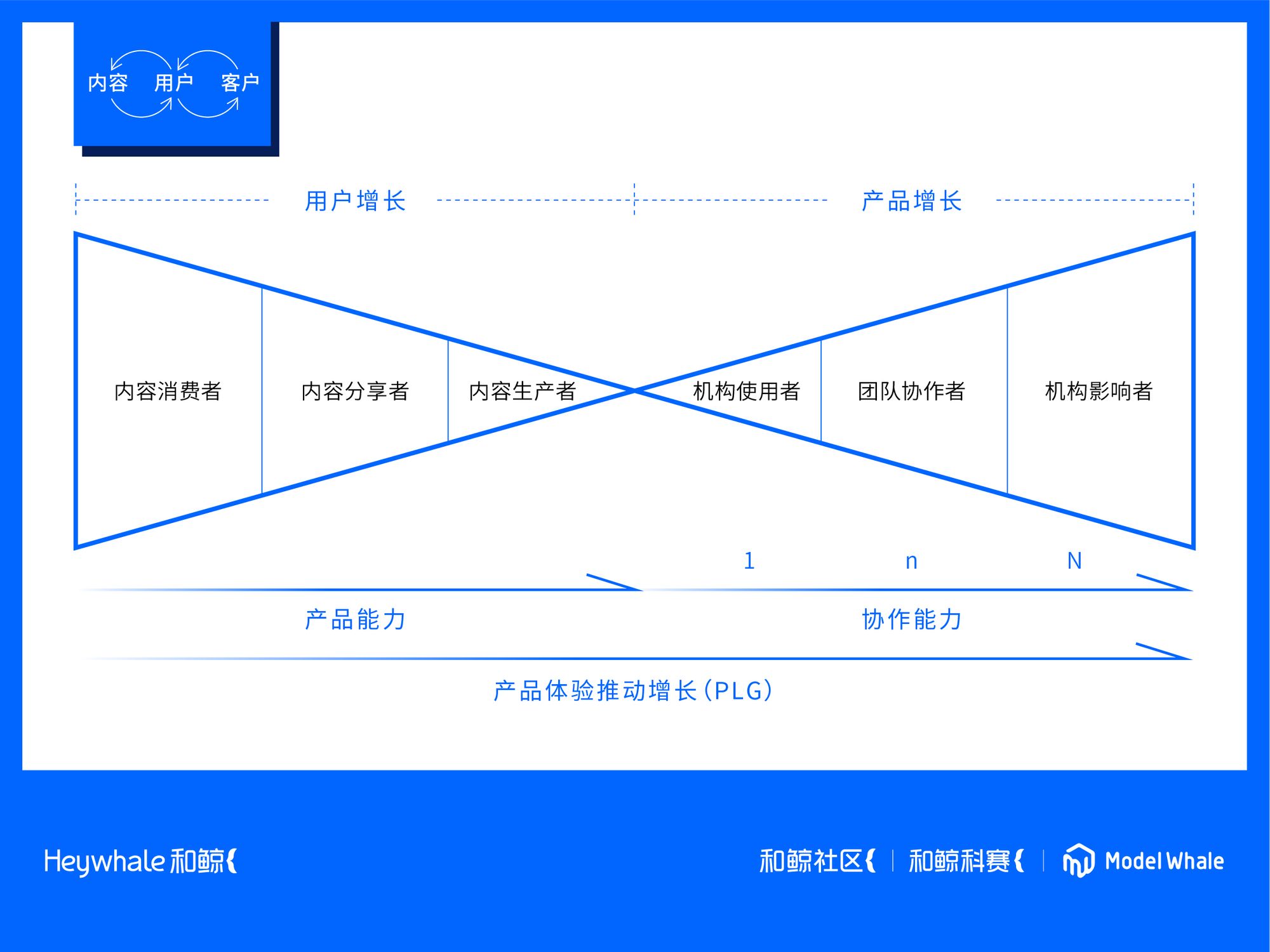
產品體驗推動增長(PLG)
問:目前在數據智能的基礎設施的行業里,我們看到好像只有和鯨把機器學習的團隊協同當做核心能力來建設,選擇走這樣一條獨木橋,您有沒有后悔過?
范向偉:后悔肯定是沒有,但確實發現了協同這個事兒遠非我們當初想的那么簡單。
開始我們只是想把 Gitlab 和 Jira 的產品模式應用在機器學習這個領域,后面發現,數據科學家協同的復雜性,比軟件工程師的協同還要高一個數量級。數據科學的業務落地、能力普及,都在很早期的階段,可能進度條只到了10%。和鯨也只是在路上。要成為一個理想的協同工具,我們做好了還有很長一段路要走的心理準備。
在數據科學團隊協作產品這個賽道里,中國幾乎沒有細分定位的生存土壤,我們的產品只有越來越厚,才能生存下來。雖然中間確實走過一些彎路,但比較高興的是,16年到現在,和鯨在協同這件事情上,還是走到了很深的無人區。
和鯨社區場景和賽事場景的協同深度都是很少見的,ModelWhale 已經包括了團隊級協同(數據科學家、數據分析師之間的協作)、企業級協同(IT、數據、業務部門之間的協作)和產業級協同(企業和供應商、科研院所、社區開發者的協同),每一層又都相互穿透、相互支撐。
所以在2021年,我們看到有七個行業的 Top3 客戶都做出了產品置換的決策,從同類產品遷移到了 ModelWhale ,這對于我們來說,是比較實在的鼓勵,因為 PaaS 產品的競爭力,很大程度上是由行業標桿客戶定義的。
04 工作流:用更好的數據回答問題
問:Gartner 已經把“協同”定義成數據科學平臺和機器學習平臺的核心能力,相信未來大家會越來越重視。那我們回到之前的話題,既然數據部門和業務部門之間很難合作起來,和鯨的產品是如何去幫助他們實現的?有沒有比較典型的客戶案例實踐可以給大家參考?
范向偉:我們的理念很簡單,就是把之前說的全鏈路放到一個統一的工作環境中。當然,理念雖然簡單,工程實現還是很復雜,產品設計也有很多挑戰。
首先,前端不僅要有開發環境,還要能把整體邏輯先拆開、再拉通,讓業務部門明白你的代碼、你的模型是什么意思,你用了什么數據,比如哪個環節是在接入數據,哪個環節是在建模,哪個環節是在做預測。總之,要讓業務部門能盡可能看懂,并且提出來自于業務視角的問題和建議。
其次,機器學習中的很多問題,歸根結底是數據問題,很多問題的解決只是因為找到了很好的數據。但是數據質量存在著巨大的方差,而工程師是不太喜歡跟數據打交道的,這是“雜活累活”。所以 ModelWhale 會把各種各樣的數據源,做干凈的接入,可以實現數據和模型開發的全流程的對接、管控和追溯。
另外,做好成果沉淀、代碼沉淀,在數據科學、機器學習項目中是很容易被忽視的,會造成很多重復勞動、資源浪費。機器學習項目經常處于一種黑箱狀態,沒有辦法講清楚到底哪個環節發生了問題,反正模型效果就是不好。所以每個階段的思路,不同參數、不同版本、不同結果,最后都應該變成一個知識庫,支撐未來的復用和迭代。
模型環節也有很復雜的流轉和很長的生命周期,“模型要用”和“模型要改”,這兩件事情永遠做不完,怎么用一個工作流水線,讓它的效率能夠大幅提升就很重要。一旦某個模型跑通了,只要過程是可以追溯的,結果是可以復現的,企業就會發現機器學習是可靠的、有用的,并產生更多模型開發的需求。
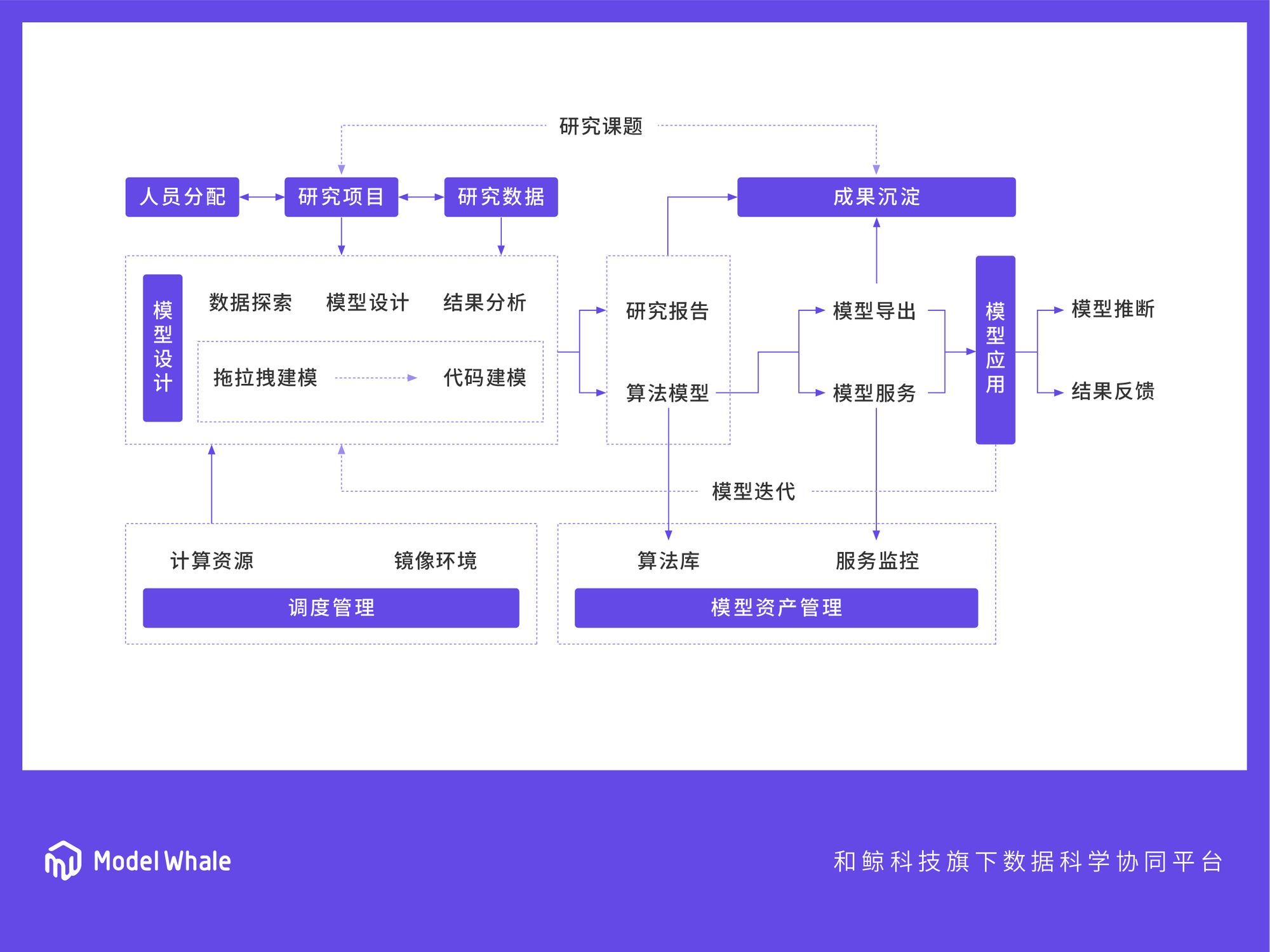
ModelWhale 適用研究
因為新能源也是未來的支柱產業,產業需求和數據科學協同平臺的關系,我可以介紹一下金風科技的案例。大家可能很難理解說人工智能去預測一個風機的運行狀態,這有什么難的,用個邏輯回歸不就可以判斷哪些機器有故障了嗎。站在理論的角度是這樣,模型的原理就是這樣的,但這只解決了所有問題的10%。風機在沙漠里,草原上、海里等等不同的地理環境,數據用什么方式回傳,是在端上處理還是回到數據中心處理,要處理通信問題、網絡問題和設備問題。風機故障也有很多種不同的原因,是因為電擊,還是低溫結冰,又或是風速太大葉片斷裂了,也對應了不同的干預策略,涉及到了IT、運維、數據等不同部門,進行持續的數據傳輸、模型訓練、效果驗證、設備維護、設備維修的協同工作。
因為存在著大量的重復工作、實驗工作、協調工作,所以可以復用的工作流,就尤其重要,要讓工作模塊化的程度、可復用的程度、自動化的程度、包括可解釋的程度盡可能的高,否則一個問題就會把整個團隊的工作卡住,而這樣的問題又是一個接一個的。
05 數據智能的大同世界
問:我們從數據智能項目的大環境講到了和鯨的協同產品,最后一個問題是,那您認為數據科學協同產品的實質是什么?或者說和鯨最終的理念又是什么?
范向偉:不知道你有沒有發現,在聊天的過程中我們多次提到了數據科學、人工智能,這兩者其實很接近,但定位不同。和這些年很多商學院會新建數據科學專業,計算機學院則是更多會建人工智能專業一樣,它們一個關注經濟效益,一個關注工程效率,這就關系到了數據科學協同產品的實質。
企業對于數據科學平臺的期待,可能和大多數的人想的不一樣。性能怎么樣、速度怎么樣、功能怎么樣,當然都很重要,但數據科學的實質不是一個技術問題、業務問題,而是一個管理問題、經營問題:到底怎樣借助數字化能力,幫助公司實現更好的生存。
領先的企業會把數據科學,當做一個杠桿、一個樞紐來看待,用數據科學的關聯能力、預測能力,把整個企業的資產、流程、指標串聯起來,構建起一個經營效率爬坡的良性循環,也就是“業務數據化”。這是一個很難實現的轉變,但 TikTok 、Shein 、元氣森林已經實現了各個行業中的打樣,得到的效果是很驚人的。
所以在我們的設想中,數據科學協同產品最大的價值,就是變成一張網,覆蓋企業所有的數據資產、人才資產、需求場景,并把他們連接起來、運轉起來,為人才賦予數字化的能力,為場景賦予智能化的效率,從而成為一個企業的數字化轉型的樞紐。這個樞紐的內核還是人才資產,而不是數據資產。這是 SaaS 產品的生命力的源頭——SaaS 產品的價值,是改善人的處境,進而改善企業效率。
我們希望數據工程師、數據科學家,可以幫助業務人才建立起用數據的習慣和能力。數據部門要把數據的能力沉淀成可復用的、低代碼、已落地的算法模板、模型倉庫,業務人員是在不同的能力模板里面做實驗和復用,把已經跑通的少數模型能力、模型資產,在更多的業務場景進行復制。
AI 的需求是無窮多的,預測的需求是無窮多的,但是AI的底層原理是相同的,業務的需求邏輯也是相似的,如果不開發業務人員的數據能力,大部分分析需求、預測需求,是來不及被滿足的。
面對現在工程和技術進步的速度,大家都有比較強的焦慮,所以無論是工程師、數據科學家還是業務人員,都要用好時間、節約時間、快速成長。業務人才需要學會用數據,數據人才需要學會做管理。
下個階段工程師所面對的新世界是不一樣的。過去,工程師在做ETL 、建數據庫、搭云平臺、做模型,但是真正的機會其實是在數據消費。數據團隊需要走出舒適圈,提高數據平臺易用性,需要對接所有的數據需求場景、所有的數據需求人員,幫助他們用好數據,否則數據平臺是沒有未來的。
更強的數據計算平臺+更多的業務用戶+更多的需求場景,這三者如何結合,才是最大的機會所在。
我們希望,以數據科學協同能力為底座,每一個問題都能找到它所需要的數據,每一個模型都找到需要它的問題。
這就是我們理想中的,數據智能的大同世界。





