
Data Fabric(數據編織),自 2019 年開始就在 Gartner 年度技術趨勢榜單上安家,并在 2022 年被列為數據分析領域十大技術趨勢之首,它究竟有哪些價值?又如何在企業落地?
在近日舉辦的全球軟件開發大會 QCon 廣州站上,網易數帆大數據產品技術負責人郭憶做了題為《基于 Data Fabric 的邏輯數據湖架構實踐》的分享,介紹了 Data Fabric 的最新實踐。
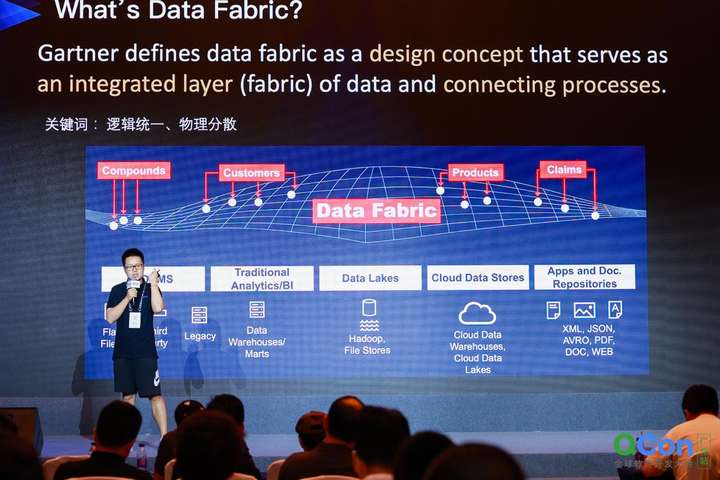
Data Fabric:好處與誤區
Data Fabric,Gartner 將其定義為一種設計理念——構建一個數據和連接過程的集成層(Fabric),以支持數據系統跨平臺的設計、部署和使用,實現靈活的數據交付。網易數帆在Data Fabric方向上,進行了落地實踐,我們將其稱之為邏輯數據湖,網易數帆認為,這個集成層就是跨平臺的邏輯模型,而通過邏輯模型,可以幫助業務人員屏蔽底層復雜的數據架構,業務人員在邏輯模型層之上,只需要選擇數據集合,即可達到開箱即用的目的。從結果來看,無論數據存儲在何處,這種架構模式都可以幫助企業低成本、及時地獲得正確的數據,并且實現數據端到端的治理。郭憶總結了 Data Fabric 的兩大關鍵詞:邏輯統一、物理分散——這也是網易數帆邏輯數據湖實踐的指導思想。
Data Fabric 的好處顯而易見。郭憶介紹道,首先,它可以幫助我們節省 70% 的工作量,包括在數據發現、數據分析以及數據開發工作;其次,可以幫助我們的業務人員更快速的使用數據進行商業分析,不需要所有的數據只有入湖才能進行分析;再次,它在業務人員和數據團隊之間構建了一個統一的界面,也就是邏輯模型層,讓數據團隊和業務團隊之間的協作更加高效;此外,它支持業務人員可以自助完成數據的消費,使得數據使用的范圍大幅度擴大。
實現這些效果,Data Fabric 自然需要一系列完善的核心能力,貫穿數據源到數據消費。

有了真香的 Data Fabric,是否意味著企業之前耗費大量精力與資源建設的數據湖、數據倉庫就沒用了?并非如此!
結合網易數帆的實踐經驗,郭憶給出了4點提醒:首先,Data Fabric 并不是真的要去湖或者去倉,而是構建一個去中心化的數據訪問層,湖或者倉可以作為其中的一個數據源存在。其次,在數據量大的情況下,Data Fabric 會有性能問題,我們可以按需將數據固化到湖或者倉中,Data Fabric 并不是一定要直接去訪問數據源。再次,Data Fabric 只是提供了一種更豐富的數據訪問界面,既可以直接去訪問數據源,也可以通過固化的方式,提供更加高效的訪問。還有很重要的一點,Data Fabric 并不是要去除 ETL,恰恰相反,DataOps 和數據治理是 Data Fabric 基礎。
網易數帆邏輯數據湖:元數據管理是關鍵
邏輯數據湖是網易數帆落地 Data Fabric 的技術方案。驅動網易數帆研發邏輯數據湖的因素,是支撐網易業務時面臨的復雜數據架構、數據分析效率問題、數據部門成為瓶頸以及資源利舊的問題。郭憶分享了網易數帆的邏輯數據湖架構,包括數據源管理、數據目錄、元數據管理、DataOps 全生命周期開發、數據模型層、物化視圖等重要模塊,覆蓋數據的管、算、用。

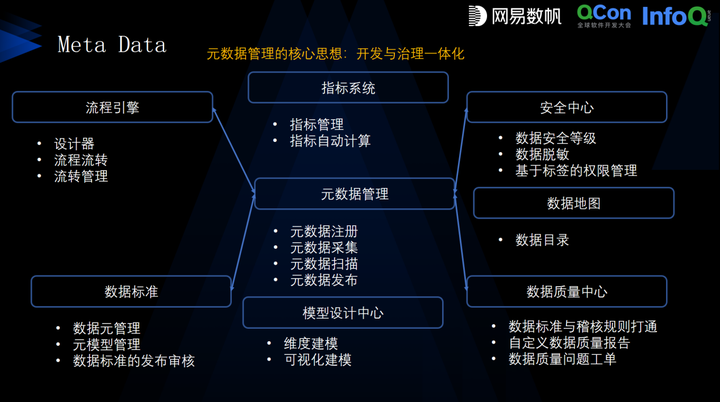
其中元數據管理是連接不同數據源實現 Data Fabric 的關鍵。網易數帆邏輯數據湖通過流程引擎、指標系統、安全中心、數據地圖、數據標準、模型設計中心和數據質量中心等七大組件來支撐元數據管理,并嚴格定義了湖外和湖內元數據發布的核心流程,以前述組件確保這些流程得以執行。
客戶實踐證明了網易數帆邏輯數據湖架構的價值。以一家大型企業客戶為例,客戶引入邏輯數據湖構建一站式開發運營模式,以中臺集約數據開發推動數據作業五統一:統一邏輯入湖、統一開發、統一調度、統一治理、統一服務,提升數據交付效率和共享能力,從而獲得多方面的收益。從平臺能力來看,客戶成功引入了成熟的數據中臺產品,以及配套相關的管理規范。從數據工作模式來看,邏輯數據湖讓業務人員由需求者成為生產者,讓數據開發人員沒有難找的數據。
運營目標的實現,首先是開發效率提升,報表開發效率提升 50%,可視化數據應用頁面開發效率提升 1倍;其次是數據自助分析能力,自助模式占各部門所有取數分析工作的比例到 30%,并培養 200 個自助分析的業務人員;而長期運營目標方面,客戶通過數據中臺能力提升,割接本地網部署的數據集市和數據平臺,改變省內當前 1+N 的模式,進一步提升作業效率和數據安全。
小結
企業數字化轉型的核心目標是降本增效,數據價值的發揮是至關重要,Data Fabric 提供了一種低成本的方式支持企業平滑、快速地落實這一目標,邏輯數據湖則是一種驗證行之有效的落地方案。邏輯數據湖也使得網易數帆數據技術棧能夠靈活地與不同行業不同企業的數據架構水乳交融,幫助客戶實現數據存儲到生產力的轉換,滿足數據驅動業務創新的需求。





