擊這里在線咨詢客服")
來源:電子工程專輯
8月9日壁仞科技的首顆GPU芯片發(fā)布之際,發(fā)布會(huì)上播放的宣傳片還真是能讓人聯(lián)想起英偉達(dá)“IamAI”的那則著名視頻。而壁仞科技選擇的這條賽道,和大部分做AI芯片的國內(nèi)廠商都不大一樣:其GPU芯片、板卡和系統(tǒng)是要和英偉達(dá)正面硬碰硬,用于云上大規(guī)模的AI訓(xùn)練與推理,以及HPC的。
壁仞科技創(chuàng)始人、董事長、CEO張文說從最初走訪20家客戶的反饋來看,大家都想要一款“國產(chǎn)大算力芯片”。雖說“做通用GPU芯片,99%都做不下去”,但“我思考,周期長、壁壘高、投入大,換句話說就是資本密集、人才密集和資源密集的需求。這三點(diǎn)恰好都是我的長項(xiàng)。”于是在成功說服投資人以后,壁仞就開啟了這一征程。
壁仞科技成立于2019年9月,用張文的話來說“三年時(shí)間,發(fā)展到千人團(tuán)隊(duì)、芯片從PPT到量產(chǎn)”是個(gè)奇跡。今年3月底就有壁仞B(yǎng)R100芯片成功點(diǎn)亮的消息,“全球通用GPU算力記錄,第一次由中國企業(yè)創(chuàng)造。”張文說,“中國通用GPU芯片,第一次進(jìn)入每秒1千萬億次的計(jì)算新時(shí)代。”
而從壁仞科技的宣傳片來看,其GPU芯片要覆蓋“從微觀細(xì)胞到浩瀚宇宙,從堅(jiān)實(shí)的道路到虛擬的空間”,從生物科學(xué)、工業(yè)設(shè)計(jì)、生產(chǎn)制造,到農(nóng)業(yè)耕作、航天航海、地質(zhì)勘探與宇宙探索。大約算是與英偉達(dá)的全方位市場重合了。要做到這些可真的不容易,也絕不僅僅是算力堆砌所能輕易達(dá)成的。本文我們就詳細(xì)談?wù)劚谪鹂萍急敬伟l(fā)布的1個(gè)架構(gòu)、2顆芯片(及對應(yīng)的OAMmodule與PCIe板卡)、1臺(tái)服務(wù)器,以及對應(yīng)于生態(tài)建設(shè)的軟件棧。

兩顆芯片:BR100與BR104
這次壁仞科技發(fā)布了兩顆芯片:BR100和BR104。這兩者的區(qū)別主要在于BR100是兩片相同的die(或chiplet)封裝到一起;BR104則只用了1片die,所以相關(guān)算力與IO等參數(shù)大多為前者的一半,適配不同的市場需求。
所以我們將注意力主要放在BR100身上。從一些關(guān)鍵數(shù)據(jù)就可以看出本次發(fā)布的BR100GPU是真正的“大”芯片。壁仞在宣傳中提到“創(chuàng)下全球(通用GPU芯片的)算力記錄”“單芯片算力達(dá)到PFLOPS級別”“峰值算力是國際廠商在售旗艦產(chǎn)品3倍以上”。
從制造和封裝技術(shù)的堆料來看,應(yīng)該更能體會(huì)其規(guī)模,包括7nm工藝、“770億個(gè)晶體管”,以及張文提到的“1000mm²”左右的diesize。這個(gè)diesize數(shù)字當(dāng)然也就突破了光刻機(jī)所能處理的reticlelimit,所以是將兩片die封裝到一起。

從壁仞科技聯(lián)合創(chuàng)始人、CTO洪洲的介紹來看,BR100明確采用了臺(tái)積電的2.5D CoWoS-S封裝方案——兩片die和周邊HBM2e內(nèi)存都放在一片硅中介(silicon interposer)上。我們在剛剛發(fā)布的《先進(jìn)封裝的現(xiàn)在和將來》一文中詳細(xì)介紹過這種先進(jìn)封裝技術(shù),國內(nèi)廠商在用的應(yīng)當(dāng)還寥寥無幾。
而且dietodie互連采用超高速112GPAM4SerDes,die間通訊帶寬達(dá)到了896GB/s——這個(gè)速度可一點(diǎn)也不比某“國際大廠”發(fā)布沒多久的GraceHopperSuperchip的NVLink-C2C差。
基于以上數(shù)字,推薦感興趣的同學(xué)去比一比,以及Intel Ponte Vecchio GPU,在die size、晶體管數(shù)量和先進(jìn)封裝技術(shù)的應(yīng)用上都有一定的可比性;也能更進(jìn)一步地體會(huì)壁仞B(yǎng)R100大約是怎樣的定位。
實(shí)際上,英偉達(dá)在今年GTC上發(fā)布、尚未上市的Hopper架構(gòu)的GH100diesize為814mm²,800億個(gè)晶體管。“大芯片”之間過招,在堆料上真的已經(jīng)到了白熱化程度。

BR100的理論算力水平如上圖所示,不同格式與精度的算力值,對應(yīng)于BR100在訓(xùn)練和推理方面的適用性。壁仞提到的“全球算力記錄”和突破PFLOPS,應(yīng)該就是指BF16格式(1024TFLOPS)。
這里有個(gè)TF32+,是壁仞新推的一種數(shù)據(jù)格式,后文將會(huì)提到。在AI訓(xùn)練中相對關(guān)鍵的BF16、TF32/TF32+峰值理論算力,都有著很漂亮的水平;著力推理的Int8也達(dá)到了2048TOPS。
其他配置數(shù)據(jù)還包括2.5D封裝在一起的64GBHBM2e內(nèi)存,“超300MB片上緩存”,2.3TB/s外部I/O帶寬,64路高清編碼、512路高清解碼加速。

對比“國際廠商在售旗艦”的峰值算力數(shù)據(jù)——這很顯然比的就是Ampere架構(gòu)的A100;AI計(jì)算相關(guān)主要數(shù)據(jù)格式的差異還是實(shí)打?qū)嵉模‵P32的數(shù)據(jù),屬于欺負(fù)A100的算力側(cè)重點(diǎn)了;而且A100堆的FP64算力在HPC領(lǐng)域也是很重要的)。
據(jù)說在“開發(fā)者云上的實(shí)測算力”,BR100的數(shù)據(jù)還更好看一些。有興趣的同學(xué)還可以拿尚未發(fā)售的英偉達(dá)Hopper新架構(gòu)來比一比,雖然這種峰值算力對比的意義并不算特別大。另外要考慮對比雙方的芯片產(chǎn)品大規(guī)模鋪貨的時(shí)間。

到更為真實(shí)的負(fù)載中,跑主流、具代表性的網(wǎng)絡(luò),包括CV、NLP,還有現(xiàn)在很流行的Transformer,壁仞B(yǎng)R100仍然是有不小的優(yōu)勢的,“平均加速比2.6x”。不過這種涉及到實(shí)際業(yè)務(wù)的對比,不僅是芯片本身,還要帶上系統(tǒng)、軟件的對比,應(yīng)當(dāng)進(jìn)一步明確對比對象和內(nèi)容。我們很期待未來看到壁仞B(yǎng)R100及對應(yīng)系統(tǒng)參與MLPerf基準(zhǔn)測試。
實(shí)則從這些與競品的性能對比數(shù)據(jù),是能夠發(fā)現(xiàn)壁仞研發(fā)團(tuán)隊(duì)的前瞻性的。這家公司2019年定義BR100芯片,到如今產(chǎn)品發(fā)布?xì)v經(jīng)3年時(shí)間,AI與通用計(jì)算加速市場環(huán)境變化不小。首次做芯片,就要預(yù)見未來3年的算力增長,并在對應(yīng)時(shí)間節(jié)點(diǎn)把產(chǎn)品拿出來,既有風(fēng)險(xiǎn)又有難度。
另外,單die的BR104主要配置與參數(shù)如下圖所示。據(jù)說即便是單die的BR104,相比于“國際廠商在售旗艦”仍然有著1.4-1.6倍的算力優(yōu)勢,包括上述不同數(shù)據(jù)格式,與主流模型基準(zhǔn)測試性能比較。

有關(guān)芯片架構(gòu)、特性、存儲(chǔ)子系統(tǒng)、IO互連的部分此處還尚未提到;比如說主機(jī)接口PCIeGen5,也特別支持了CXL互連協(xié)議;還有壁仞自研的BLink點(diǎn)對點(diǎn)全互連技術(shù)能將8個(gè)GPU有效連接在一起等等。我們將這部分放到本文的最后。
芯片構(gòu)成模組、板卡和服務(wù)器以后
更往上的板級系統(tǒng)層面,BR100、BR104芯片當(dāng)然是需要對應(yīng)到具體的產(chǎn)品形態(tài)的。這次壁仞發(fā)布了兩款具體的硬件產(chǎn)品:壁礪100和壁礪104,分別應(yīng)用了BR100和BR104芯片,這兩款產(chǎn)品分別以O(shè)AM(OCPAcceleratorModule)模組與PCIe板卡的形態(tài)存在。算力規(guī)格之外,功耗分別對應(yīng)550W和300W。


壁仞科技聯(lián)合創(chuàng)始人、總裁徐凌杰特別提到,其中壁礪100“在板級和系統(tǒng)層面做了非常多的創(chuàng)新”。供電方面,“我們專門為這套系統(tǒng)打造了48V電源,有著超高的電源密度和開關(guān)頻率,提供穩(wěn)定的供電和超高的電源效率。”
而在散熱方面,“我們在板卡上采用快速均溫技術(shù),增加了熱腔體積和撞風(fēng)面積,有效提升了散熱效率。”徐凌杰表示,“我們還優(yōu)化了散熱器的外形,能夠在不影響散熱的前提下降低5%以上的風(fēng)阻。”除此之外,“考慮到系統(tǒng)的穩(wěn)定性和可靠性,我們也設(shè)計(jì)了一套專門的中斷和保護(hù)機(jī)制。”右圖的熱力圖表現(xiàn)的是OAM模組之上溫度的分布情況。

系統(tǒng)和性能擴(kuò)展相關(guān)的部分,應(yīng)該也是很多人關(guān)注的重點(diǎn)。“我們把8個(gè)OAM模組放在通用UBB主板上,形成8卡之間點(diǎn)對點(diǎn)的全互連拓?fù)洹3浞掷肂R100上面的高速接口,和UBB的互連基礎(chǔ)設(shè)施,8張卡之間兩兩互連。”徐凌杰說,“節(jié)點(diǎn)內(nèi)每張卡能夠有448GB/s的互連帶寬,節(jié)點(diǎn)之外還有64GB的帶寬。”8卡對分帶寬1.8TB/s。
這是“國內(nèi)芯片設(shè)計(jì)廠商中,第一個(gè)實(shí)現(xiàn)在OAM系統(tǒng)中,單節(jié)點(diǎn)8卡的全互連拓?fù)?rdquo;。全互連拓?fù)涞膬r(jià)值,自然就在于專線通信,每張卡在系統(tǒng)中完全對稱,便于分布式調(diào)度和部署。

PCIe板卡形態(tài)的壁礪104則能夠部署在大部分2-4U的服務(wù)器里。徐凌杰特別提到,壁礪104也能夠?qū)崿F(xiàn)多卡之間的高速互連。“我們?yōu)榇藢iT設(shè)計(jì)了高速的橋片,能夠在4張卡之間形成點(diǎn)對點(diǎn)的全互連拓?fù)洌瑤?92GB/s。”

值得一提的是,本次發(fā)布會(huì)上壁仞特別宣布了與浪潮合作推出的OAM服務(wù)器:海玄。這臺(tái)服務(wù)器的理論峰值算力(BF16)達(dá)到8PFLOPS;512GBHBM2e內(nèi)存;支持PCIe5.0和CXL;1.8TB/s對分互連帶寬;最大功耗7kW。
這個(gè)部分的最后,有必要說一說AI芯片與GPU廠商于系統(tǒng)層面的常規(guī)對比項(xiàng)目:少不了要和“國際廠商”對比TCO(總擁有成本)和功耗。這是真正涉及到性價(jià)比和效率的部分。
徐凌杰表示,“用國際巨頭在售的旗艦產(chǎn)品,6000臺(tái)服務(wù)器(DGXA100640GB?)可以達(dá)到15EFLOPS的浮點(diǎn)算力,需要3000臺(tái)機(jī)柜,占地空間1萬平方米以上,峰值功耗39兆瓦,最高需要3.4億度電每年,相當(dāng)于4.2萬噸煤的發(fā)電量。”

而如果換成OAM服務(wù)器海玄,“只需要2000臺(tái)海玄服務(wù)器,達(dá)到16EFLOPS的算力;只需要1000個(gè)機(jī)柜,占地面積不超過3500平方米,峰值功耗14兆瓦,1.2億度年用電量,相當(dāng)于1.5萬噸標(biāo)準(zhǔn)煤發(fā)電量,實(shí)現(xiàn)了整體方案64%的成本下降。”
當(dāng)然這是個(gè)理想數(shù)據(jù),我們在不少AI芯片供應(yīng)商那里都看到過類似的對比;實(shí)際情況很大程度還是受到業(yè)務(wù)類型、開發(fā)生態(tài)、軟件和系統(tǒng)效率等各方面的因素影響。目前壁礪104PCIe板卡已經(jīng)向部分用戶“開放邀測”,而海玄OAM服務(wù)器則“正在內(nèi)部進(jìn)行緊鑼密鼓的測試,即將在下個(gè)季度與客戶見面”。
軟件與生態(tài)建設(shè)情況
洪洲在介紹芯片架構(gòu)之前就提到,壁仞科技要“占領(lǐng)數(shù)字經(jīng)濟(jì)的制高點(diǎn)”。“我們計(jì)劃通過我們的芯片、計(jì)算卡,要承載我們的軟件來對接應(yīng)用。剛開始兼容主流生態(tài),然后搶占整個(gè)生態(tài)的話語權(quán)”。“我們關(guān)鍵是要打造生態(tài),真正將生態(tài)打好才是立足之本。”
要在現(xiàn)如今的通用計(jì)算GPU市場有所發(fā)展,芯片做得再好,沒有龐大的生態(tài)都將難以生存。而且生態(tài)一直也是英偉達(dá)賴以生存與業(yè)績數(shù)年持續(xù)躥升的根源所在。英偉達(dá)當(dāng)前所涉足的通用計(jì)算加速領(lǐng)域,每年GTC上新發(fā)布的加速庫、框架、軟件和應(yīng)用,都足以讓競爭對手汗顏——甚至是一些細(xì)分、小眾的領(lǐng)域。
尤其是每年更新個(gè)什么庫,相同硬件的效率就提升1倍,有時(shí)都足以將DSA架構(gòu)芯片的效率領(lǐng)先優(yōu)勢吃干抹凈。更不用談上層應(yīng)用面向開發(fā)者時(shí),易用性有時(shí)可以將競爭對手甩開幾條街。
壁仞科技作為一家剛剛發(fā)布第一顆芯片、成立才3年的新入局者,自然不大可能做到一蹴而就。我們此前采訪不少生態(tài)投入時(shí)間超過5年的AI芯片企業(yè),他們都對英偉達(dá)的生態(tài)建設(shè)水平感到無奈。這預(yù)計(jì)也將成為壁仞科技接下來很長一段時(shí)間內(nèi)要投入大量人力物力的部分。
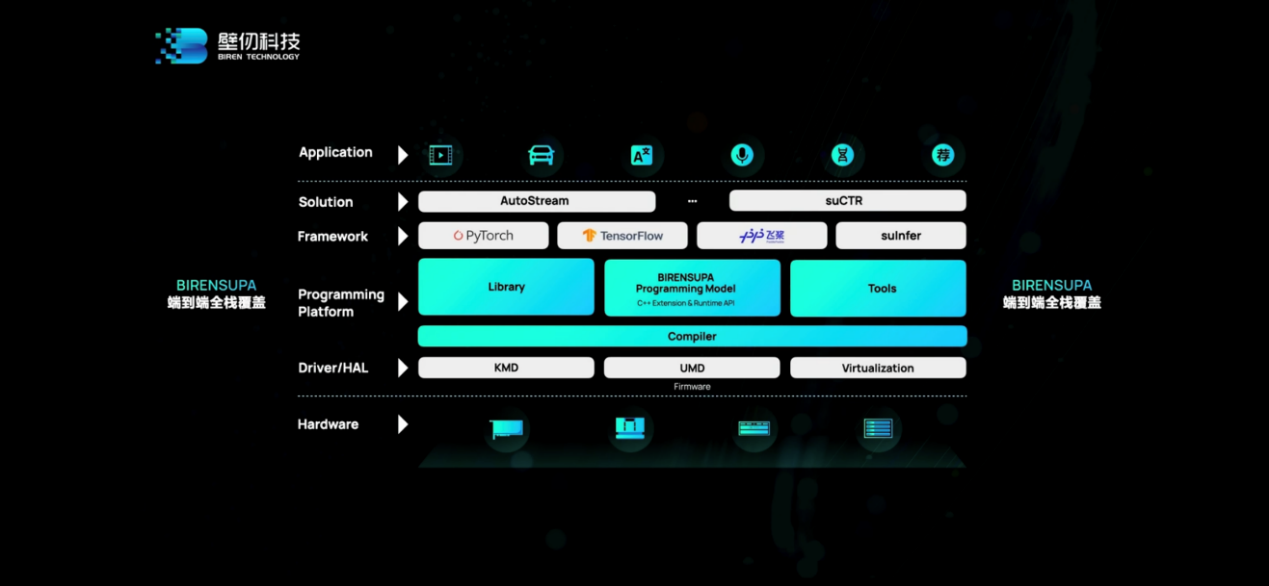
上面這張圖是壁仞的BIRENSUPA(以下簡稱SUPA)軟件全棧,從驅(qū)動(dòng)、硬件抽象層、編程平臺(tái)、框架,到具體的解決方案和應(yīng)用。除了相關(guān)壁仞GPU自身架構(gòu)特性的一些接口(下文架構(gòu)介紹中也會(huì)有涉及),這里比較值得一提的包括框架層支持PyTorch、TensorFlow,和已經(jīng)在合作中的百度飛槳PaddlePaddle——百度也出現(xiàn)在發(fā)布會(huì)上,給出了“產(chǎn)品兼容性證明”;框架層有個(gè)壁仞自研的推理引擎suInfer。
上層的解決方案,現(xiàn)階段主要有兩個(gè):AutoStream和suCTR。壁仞科技聯(lián)席CEO李新榮介紹說,AutoStream智能視頻分析引擎是基于GStreamer框架開發(fā)的軟件庫,用于端到端的智能分析。“它可以對圖像以及視頻的數(shù)據(jù)做前端和后端的處理,充分利用壁仞GPU的解碼能力和推理加速能力,高效地支持視頻分析應(yīng)用。”未來還會(huì)有更多AutoStream的功能問世。
而suCTR是個(gè)廣告推薦訓(xùn)練框架,“支持基于GPU架構(gòu)的訓(xùn)練框架,用在廣告推薦場景上;采用多級稀疏參數(shù)存儲(chǔ)架構(gòu),單機(jī)就可以支持TB級參數(shù),并且可以通過多級擴(kuò)展來支持更多的大規(guī)模參數(shù);兼容TensorFlow,減少用戶開發(fā)的遷移成本。”
開發(fā)者比較關(guān)心的部分具體內(nèi)容可見以下PPT;就一家剛剛發(fā)布芯片的企業(yè)而言,我們認(rèn)為這樣的生態(tài)構(gòu)建水平已經(jīng)是比較優(yōu)秀的了:



另外作為生態(tài)建設(shè)的一環(huán),壁仞科技“開發(fā)者云”當(dāng)前已經(jīng)上線。壁仞也現(xiàn)場演示了開發(fā)者云的使用。“開發(fā)者云是基于壁仞suCloud機(jī)器學(xué)習(xí)平臺(tái)搭建的集成式開發(fā)環(huán)境,旨在為開發(fā)者提供可遠(yuǎn)程訪問壁仞GPU資源的云端入口。”
生態(tài)建設(shè)前期,壁仞似乎和不少高校展開了合作,主要著力在和高校建立合作關(guān)系,從學(xué)術(shù)研究、人才培養(yǎng)和科研成果轉(zhuǎn)換上入手。從壁仞展示的視頻來看,目前涉及的合作方向包括醫(yī)療影像、分子動(dòng)力學(xué)、電磁仿真等領(lǐng)域。雖然不清楚合作深度和成果產(chǎn)出如何,但這本身就是生態(tài)擴(kuò)展、為未來打基礎(chǔ)的長遠(yuǎn)方案。
“壁立仞”芯片架構(gòu)
感覺能在發(fā)布會(huì)上從高抽象層級談技術(shù)的企業(yè),在國內(nèi)還真是稀缺。壁仞在這次發(fā)布會(huì)上,花了比較多的篇幅著墨于自家GPU芯片的“壁立仞”架構(gòu)。做大算力可不是堆晶體管就行的,這其中涉及到PPA權(quán)衡、內(nèi)存功耗限制問題、兼容性等等。本文最后,我們就來談一談構(gòu)成BR100/BR104芯片的壁立仞架構(gòu),有何獨(dú)特之處。
洪洲給出了壁立仞架構(gòu)的6大特性:TF32+數(shù)據(jù)格式支持、TDA張量數(shù)據(jù)存取加速器、C-Warp協(xié)作開發(fā)模式、NME近存儲(chǔ)計(jì)算引擎、NUMA/UMA訪存機(jī)制、SVI安全虛擬實(shí)例。雖然聽起來其中的某些還是比較通用。
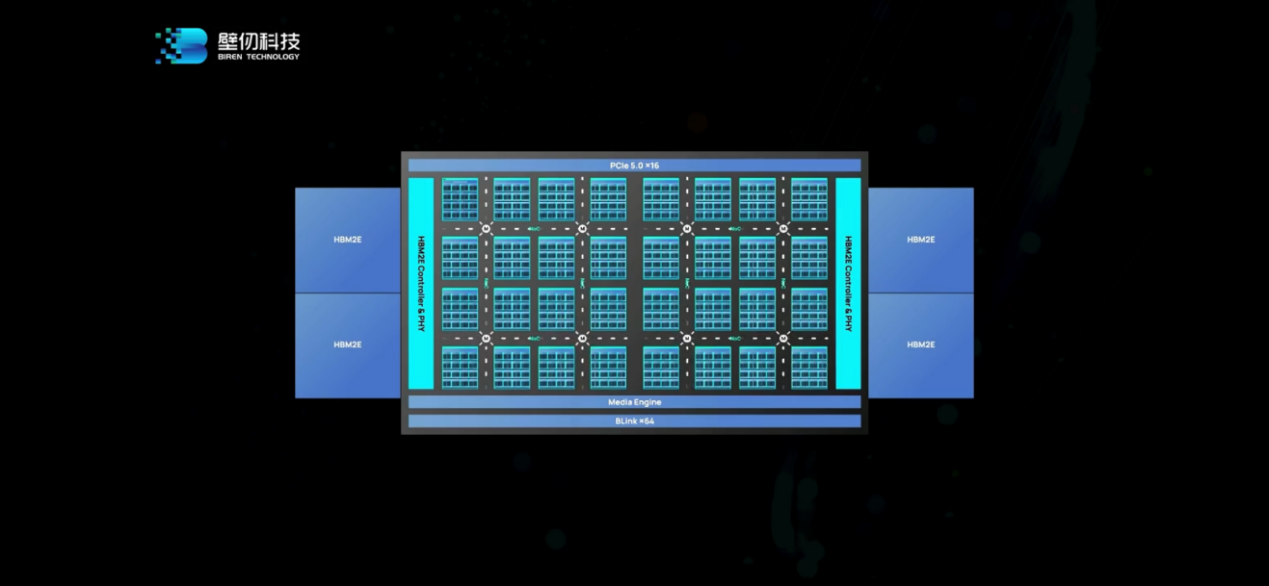
這是BR100邏輯框架圖,其上包含有計(jì)算單元、2Dmesh片上網(wǎng)、HBM2e存儲(chǔ)系統(tǒng)、媒體引擎、連接主機(jī)的PCIeGen5接口、互連接口。

放大計(jì)算核部分,這是流處理器簇(SPC),采用標(biāo)準(zhǔn)化的模塊化設(shè)計(jì),上面能跑4096并行線程。一個(gè)SPC內(nèi)部包含有16個(gè)EU(執(zhí)行單元),每4個(gè)EU可配置成1個(gè)CU(計(jì)算單元)。一個(gè)BR100內(nèi)部有32個(gè)這樣的SPC流媒體簇。

放大其中的EU。一個(gè)EU主要包含兩部分,一部分是“通用流式處理器(V-core)”。“我們采用了SIMT通用并行處理器”,BR100的“通用性主要就來自這個(gè)處理器,它支持各種各樣的指令,而且是完全并行的通用架構(gòu)”。這部分應(yīng)該也是能夠兼容CUDA的原因。
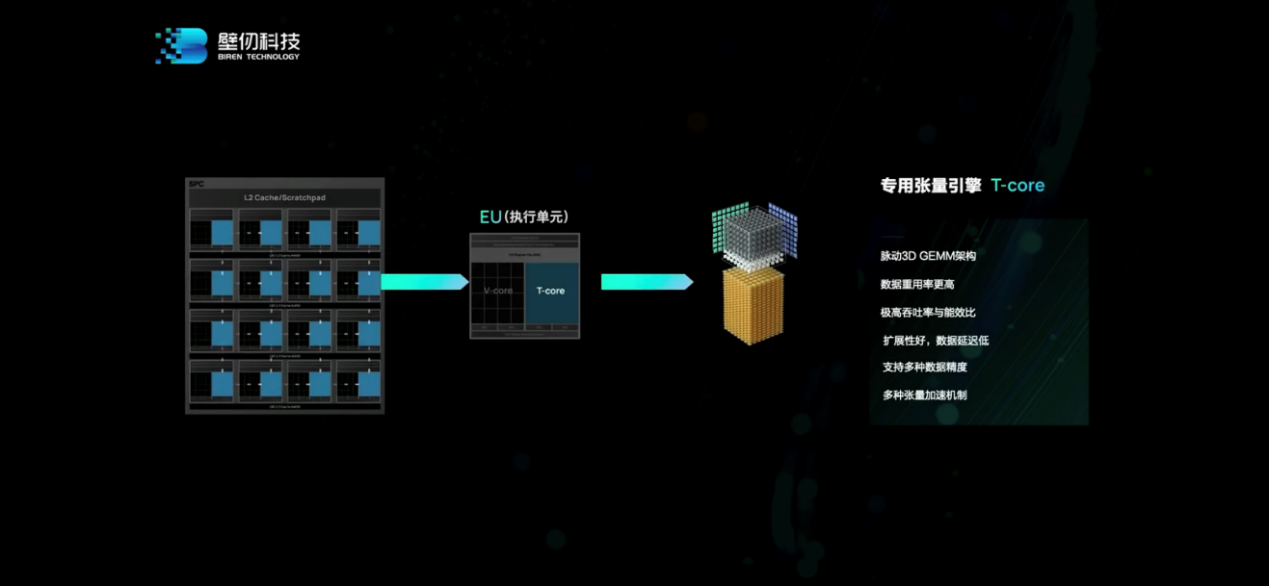
另一個(gè)部分就是tensorcore。“我們的做法和業(yè)界不大一樣。我們的tensor核是完全集成在向量核里面的,作為向量核的加速器。”洪洲說,“其優(yōu)點(diǎn)在于,可以把16個(gè)tensor核連在一起,達(dá)成更大的tensor核,讓矩陣運(yùn)算效率得到極大提高。我們算下來大概能提高30%。”
“矩陣運(yùn)算是AI、HPC里面最重要的運(yùn)算。所以這個(gè)設(shè)計(jì)至關(guān)重要。這樣的設(shè)計(jì)能提高能效比,讓數(shù)據(jù)重用性變得更好。”
“我覺得到底用通用架構(gòu)還是DSA架構(gòu),這個(gè)爭論是沒有意義的。”洪洲談到,“BR100里面,這兩者都有了,既有通用性,也有很好的PPA。”

分布式共享L2cache也是洪洲特別提到的創(chuàng)新點(diǎn)。“傳統(tǒng)GPU的L2cache一般在芯片中間,或者芯片邊上,在memorycontroller旁邊。我們的設(shè)計(jì)是分布式緩存,和每個(gè)大的計(jì)算核在一起,也能夠共享,通過片上網(wǎng)將其連在一起。”“這樣的好處是,讓數(shù)據(jù)和計(jì)算單元挨得很近,與此同時(shí)又在芯片level做共享。”
基于以上信息,BR100芯片同時(shí)能跑128000個(gè)線程,總計(jì)8192個(gè)通用流式處理器、512個(gè)張量加速器,256MB分布式共享緩存。

BR100所用的片上網(wǎng)絡(luò)(NoC),為“網(wǎng)格式多播(multicast)片上互連”。“權(quán)重一般來說是可以共享多播的;當(dāng)你跑模型并行,trainingsample也可以共享多播。這樣就能極大減少對內(nèi)存的帶寬壓力,減少片上網(wǎng)link的帶寬壓力。”

IO方面值得一提的特性,除了PCIeGen5主機(jī)接口支持——128GB/s帶寬,并且支持CXL互連協(xié)議以外;BLink點(diǎn)對點(diǎn)全互連技術(shù),在壁仞科技的版圖中應(yīng)該也是很重要的——可類比于英偉達(dá)的NVLink。
“我們有8組BLink接口,其中7個(gè)接口可以連接另外7個(gè)GPU,最終將8個(gè)GPU有效連在一起。”洪洲說,“我們?yōu)槭裁匆匝羞@個(gè)接口?因?yàn)樗軌蚪o我們更好的控制。通過這項(xiàng)技術(shù),把8個(gè)GPU當(dāng)成1個(gè)GPU來用,并且把數(shù)據(jù)多播、計(jì)算核之間同步都通過接口來實(shí)現(xiàn)。”
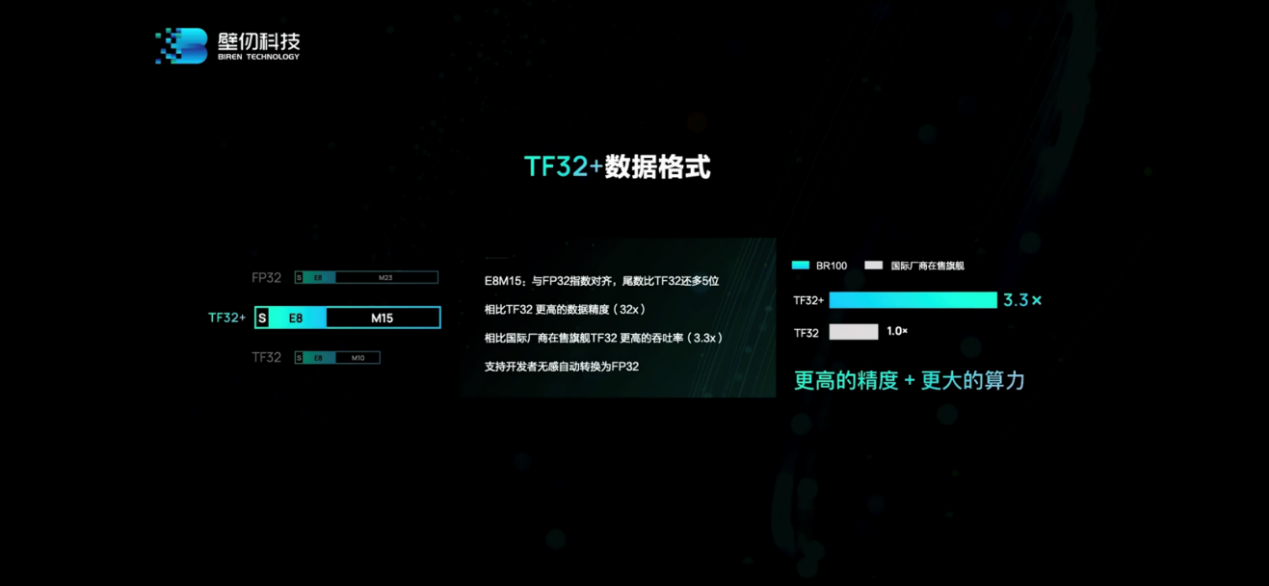
6大亮點(diǎn)中的第一個(gè)就是TF32+數(shù)據(jù)格式的支持。“兩年前,頭部廠商引入了TF32,這個(gè)格式能夠讓網(wǎng)絡(luò)比較容易收斂。但我們和客戶交流的時(shí)候發(fā)現(xiàn),這還遠(yuǎn)遠(yuǎn)不夠。很多客戶在某些場景下,為了0.1%的精度提高,寧愿速度跑慢一點(diǎn),或者加更多設(shè)備。”
“我們的TF32+,精度bit有15bit(E8M15),TF32就只有10bit。我們增加了5bit,相當(dāng)于增加了32倍精度。”洪洲說,“即使這樣,我們的TF32+算力仍然是頭部廠家TF32的3.3倍。”所以最終達(dá)成了“更高的精度”和“更大的算力”。

架構(gòu)層面的另一個(gè)亮點(diǎn)在于TDA(TensorDataAccelerator)張量數(shù)據(jù)存取加速器。這個(gè)加速器用于offload計(jì)算單元(SPC)的數(shù)據(jù)存取工作。“它是個(gè)專門的加速器,像數(shù)據(jù)的加壓、解壓、地址計(jì)算、同步。它能讓計(jì)算和數(shù)據(jù)搬動(dòng)做到異步。”
實(shí)際上,以下多項(xiàng)特性都著力于減少數(shù)據(jù)通訊產(chǎn)生的開銷——在AI計(jì)算時(shí)代,這個(gè)命題正被不斷放大。而“高算力”架構(gòu)現(xiàn)在總是要花大量的精力在應(yīng)對存儲(chǔ)墻的問題上。包括C-Warp協(xié)作并發(fā)、NME近存儲(chǔ)計(jì)算引擎、NUMA/UMA訪存機(jī)制:



比如C-Warp協(xié)作并發(fā)相比于傳統(tǒng)GPU的warp和warp之間不能直接通訊(需要經(jīng)由cache來交換數(shù)據(jù)),“我們這種模式可以藉由一些同步方式,通過RegisterFile來直接傳遞數(shù)據(jù),也就減少了數(shù)據(jù)的搬移。”
而NME近存計(jì)算引擎應(yīng)當(dāng)和前面提到的分布式L2cache也有關(guān),“讓計(jì)算發(fā)生在數(shù)據(jù)呆著的地方。數(shù)據(jù)走到哪兒,計(jì)算就應(yīng)該在哪兒發(fā)生。”這里的“reductionengine”大約是關(guān)竅所在。NUMA/UMA訪存機(jī)制也是考量不同數(shù)據(jù)特性,減少數(shù)據(jù)通訊的距離和次數(shù)。
洪洲說由于數(shù)據(jù)存取需要大量開銷,很多馮諾依曼體系架構(gòu)的芯片,功耗真正花在“算”的部分就只有10%。“我們很驕傲地說,BR100測下來,大部分功耗都是花在了‘算‘上面。基于不同的場景,有些場景能到70%,有些60%,這已經(jīng)非常好了。這是對計(jì)算模式的顛覆。”以上所有技術(shù)在此應(yīng)當(dāng)都是至關(guān)重要的。

虛擬化和安全相關(guān)的技術(shù),對當(dāng)代數(shù)據(jù)中心GPU而言自然也不能少。SVI安全虛擬實(shí)例特性的一個(gè)亮點(diǎn),應(yīng)該是支持1、2、4、8份實(shí)例的“物理切分”。“每個(gè)物理切分,memory、緩存、計(jì)算單元、片上網(wǎng)的link都是私有的,和旁邊在跑的東西完全隔離,相互不會(huì)有影響。”
另外還有國密1級安全標(biāo)準(zhǔn)支持等特性,以及性能方面BR100“即使切成8份,每份算力也有256TOPS(INT8),是現(xiàn)在主流推理卡的2倍性能”等。

這是個(gè)很好的起點(diǎn)
壁仞B(yǎng)R100/BR104芯片,以及軟件生態(tài)、OAM模組與PCIe板卡的發(fā)布還是相當(dāng)振奮人心的。至少從這次的發(fā)布會(huì)來看,3年時(shí)間交出的答卷讓人滿意。無論是芯片算力水平、架構(gòu)亮點(diǎn)、所用的制造和封裝技術(shù),還是系統(tǒng)產(chǎn)品的能效、TCO。而且如前所述,壁礪104很快就要量產(chǎn)出貨了,海玄OAM服務(wù)器今年Q4也將開放邀測。
不過GPU通用計(jì)算和AI市場的競爭也實(shí)在不簡單,要在既有市場參與者占據(jù)統(tǒng)領(lǐng)地位的環(huán)境中占得一席之地,甚至“搶占生態(tài)話語權(quán)”都絕非短時(shí)間內(nèi)可以達(dá)成。實(shí)際上,英偉達(dá)當(dāng)前的優(yōu)勢,一方面來自xPU芯片和系統(tǒng)的覆蓋,不僅是GPU芯片和系統(tǒng),還體現(xiàn)在networking等領(lǐng)域的不斷開花結(jié)果。而老生常談的軟件生態(tài),更是全棧自下而上的覆蓋,以及持續(xù)不斷的行業(yè)橫向擴(kuò)張。
無論如何壁仞B(yǎng)R100的發(fā)布都是個(gè)出色的開端,接下來等待壁仞科技的還會(huì)有更多的挑戰(zhàn)。產(chǎn)品落地和持續(xù)的生態(tài)建設(shè)會(huì)是所有人都將密切關(guān)注的。





