
從流批一體、湖倉一體、NoETL、數據中臺到DataOps,現代數據分析領域熱詞迭出,企業如何抓住本質,經營數據生產力以提質增效?
9月26-27日,ArchSummit全球架構師峰會杭州站舉辦,網易副總裁、網易杭州研究院執行院長、網易數帆總經理汪源受邀在會上發表主題演講,深入淺出地剖析了現代化數據分析架構中最值得關注的三條主線,包括統一的基礎設施、統一的中間層和統一的數據資產,并介紹了國內外的相關技術實踐。

統一的基礎設施:流式湖倉,Iceberg+Arctic將成核心
統一的基礎設施要解決四大問題:湖倉一體、流批一體、標準格式和存算分離——不僅是文件格式,還包括表格式。汪源表示,理想的統一基礎設施是流式湖倉的基礎設施,即湖倉和流批都做到一體。除了最底層的對象存儲,目前已有可用的開源實現。
統一的基礎設施包括六層架構。最底層是存儲層,往上是Parquet文件格式層,中間加了緩存加速層,用來彌補上層需求和底層對象存儲之間的性能差距,現在出現的有Alluxio、JuiceFS、CurveFS,其中CurveFS是網易數帆開源的一個文件存儲系統。
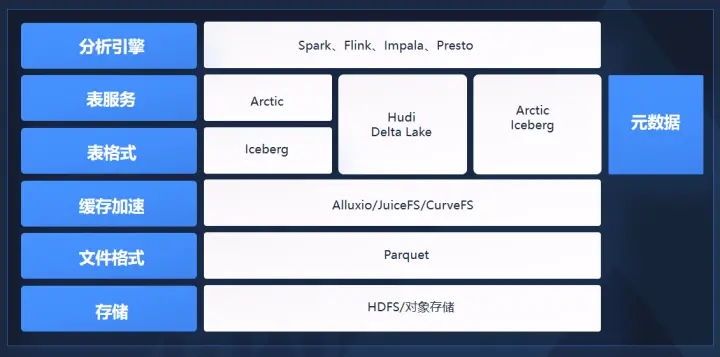
最核心的是最近兩三年出現了兩個新的層次,一個是表格式(table format),如Iceberg、Hudi,一個是表服務(table service),如Arctic。這兩個層次能夠讓底層大數據體系支持湖倉一體、實時更新、版本一致性、ACID等等,之前的大數據沒有這些功能,所以它無法做一些實時的分析服務,只能做T+1的分析。最上層是分析引擎層。
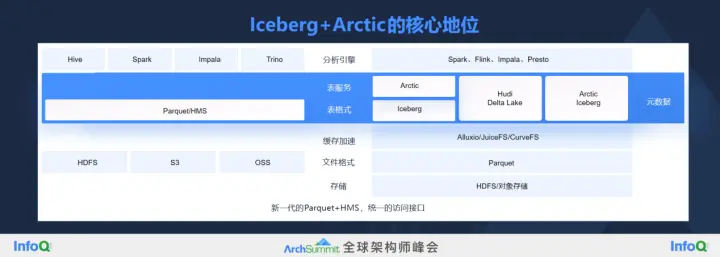
汪源認為Iceberg是最有希望成為table format標準的項目。Iceberg從數據層面提供了ACID的能力,并且可以讀到任何時間點的數據;第二個從元數據層面解決了HMS性能瓶頸,把原來集中式的元數據變成了分布式的元數據,并且相當于給數據構建了一個多級的索引,能夠支持高級過濾,這能解決很多問題。比如大數據場景常見千萬甚至億級文件的查詢,基于Hive的查詢啟動可能要花20分鐘,而Iceberg可以做到一分鐘以內,這是一個非常夸張的進步。
Arctic由網易數帆于2022年8月宣布開源,但在網易數帆內部研發已經將近三年。Arctic主要用來幫助Iceberg把整體的技術體系構建完整,因為Iceberg只是一種格式,無法單獨形成面向分析性能最優化的狀態。Arctic首先提供了基于Iceberg的自優化的能力,以及upsert的功能,支持高效的數據更新。其次支持流批一體,流表和批表定義一致,可以復用。最后是兼容Hive和Iceberg,從而可以快速落地。
汪源認為,今天由Iceberg和Arctic共同構建的這一層會成為一個新的事實的標準,在它下面有不同的存儲,在它上面有不同的計算體系。“這個中間基本上勝出的只有一家,不可能有多家,否則這個技術棧就混亂了。”
統一的中間層:數據倉庫+HeadlessBI
數據分析的過程,理想的狀態是理論大師們規劃的路線:在數據倉庫里面做好了所有的數據轉化,每一個團隊用很好的BI工具只做數據的展現和交互,所有的計算邏輯應該都在數倉里面完成。但實際上每一個團隊都會在自己的BI里面去做很多的計算邏輯,這是數據倉庫的計算邏輯不夠用,導致計算邏輯分散的問題。汪源指出,大家在不同的BI產品中看到的數據口徑和結果的差異,就是由分散的計算邏輯帶來的。
解決該問題的“中國方案”是數據中臺,通過OneData、OneService、OneID,解決指標口徑不一致的問題,所有的口徑定義、計算邏輯都在中臺做好。數據中臺包括了數據倉庫,在數據倉庫定義了一套規范的指標層,包括原始指標、派生指標、復合指標。上面是數據服務層,提供所有對外的數據。同時又引入了數據治理來保證中臺輸出的數據符合質量和安全要求。

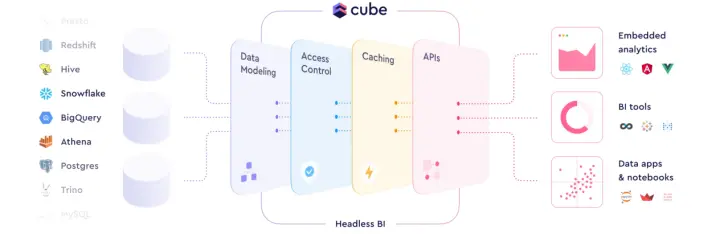
國際方案包括三個核心概念:Semantic Layer、HeadlessBI和Metric Layer。汪源認為最貼切的描述是HeadlessBI,以國外的Cube產品設計為例,數據輸入來自左邊的各種數倉,中間HeadlessBI要做的是數據建模、安全相關的訪問控制、性能加速,最后以API的方式提供給右邊的下游消費者,主要是BI工具以及嵌入式的分析。
在這個方向上,網易數帆強調的是開發和治理一體化,在建數倉、建指標等開發活動的過程中把數據治理同步完成,讓指標、模型等持續保持高質量。此前,網易數帆發現很多客戶先找開發的方案來做開發,做完之后發現數據質量不佳,又去做數據治理的項目。汪源表示,在開發環節同時把開發治理做好了,就不會有這樣的后遺癥。
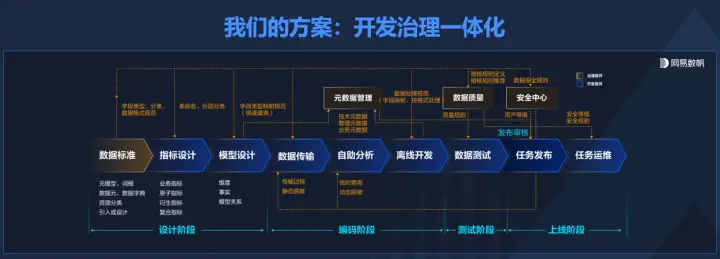
汪源對統一的中間層的期待,包括數據倉庫和HeadlessBI兩層,后者能做建模,包括指標,做權限、加速和服務,同時把開發和治理一體化,通過統一的模型指標計算邏輯和口徑,實現事前事中事后的持續治理。這樣BI層可以真正聚焦在展現和交付上,汪源將其命名為“NecklessBI”,與HeadlessBI對應。

汪源還強調,在此過程中,ETL不會被消除,它只能被轉移或隱藏,因為從數據源到分析所需要的數據一定是有很多不匹配的,比較現實的是做ETL的自動化,即AutoETL。
統一的數據資產:Data Fabric已落地
數據資產管理面臨的問題,是數據找不到,找到了看不懂,看了之后信不過、不敢用,管不牢等。汪源認為比較可行的思路就是分析機構提出的Data Fabric,它的目的是實現數據的整合利用,它是一個架構思想或者設計理念,并不綁定一個特定的技術實現。

Data Fabric和其他數據整合利用的方式有明顯的區別:數據倉庫或者數據中臺,比較強調數據的集中,同時也強調數據比較深度的預加工。數據湖強調數據的集中,但是它強調數據不要做太多的預加工,應該按照原始的數據格式都存在湖里面,需要的時候再把它拿出來處理。Data Fabric則強調元數據的集中。
Data Fabric的實際落地需要構建四個方面的核心能力,包括連接數據源、主動元數據(active metadata)、數據虛擬化和邏輯數據湖。汪源認為數據虛擬化能最大程度發揮Data Fabric的能力,因為它能夠在數據沒有完成集中之前就能夠做一定程度的利用,但并非所有的數據分析都可以基于數據虛擬化來做。網易數帆已經落地的邏輯數據湖,也是Data Fabric的一種實現,它從邏輯上看是一個湖,但是從物理實現上數據還是分散存儲在Hadoop、Oracle、MySQL等系統里面。
總結
總體來說,現代數據分析技術的三大主題,第一個是構建一個統一的基礎設施,能夠支撐實時數據更新與消費,并且是開放、低成本的流式湖倉基礎設施。第二個是統一的中間層,包括數據倉庫和HeadlessBI兩個層次,要做到統一的模型、指標、計算邏輯和口徑,并實現事前事中事后持續的數據治理。第三個是統一的數據資產,目的是企業全域數據資產的高效的發現、整合和管理,它在實現上能夠兼容各種風格的數據處理技術。
“我希望整個行業能夠往這些方向去聚焦,不要產生太多的相互割裂的概念。”汪源說。





