
Q:如圖1所示,在列B中有幾千行這種不規則的數據,現在只想篩選出左邊是數字右邊是字母的數據,例如558fjk、07ad,如何能夠實現?
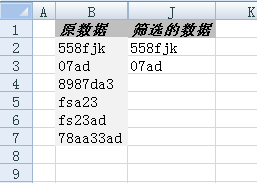
圖1
A:下面介紹如何使用數組公式來實現目的。為便于理解,我們先使用一些中間結果,然后組合成最終的數組公式。
我們的思路是,首先將數據分解成單個的字符,然后找出字符在數據中首次出現的位置,接著取自字符首次出現到數據末尾的部分,看看是否還會出現數字,如果再次出現數字,則表明數據不符合要求,否則獲取原數據,即原數據滿足要求。
以單元格B2中的數據“558fjk”為例。
單元格C2中的數組公式:
=MID(B2,ROW(INDIRECT(“1:”& LEN(B2))),1)
得到數組{”5”,”5”,”8”,”f”,”j”,”k”}
在單元格D2中,使用1來乘以單元格C3中的公式得到的數組:
=1*MID(B2,ROW(INDIRECT(“1:”& LEN(B2))),1)
得到數組{5,5,8,#VALUE!,#VALUE!,#VALUE}
單元格E2中,將數組傳遞給ISERROR函數:
=ISERROR(1*MID(B2,ROW(INDIRECT(“1:”& LEN(B2))),1))
得到數組{FALSE,FALSE,FALSE,TRUE,TRUE,TRUE}
單元格F2中,使用數組公式:
=MATCH(TRUE,ISERROR(1*MID(B2,ROW(INDIRECT(“1:”& LEN(B2))),1)),0)
得到數據中第1個非數字字符出現的位置,本例中為4。
單元格G2中,數組公式:
=MID(B2,MATCH(TRUE,ISERROR(1*MID(B2,ROW(INDIRECT(“1:”& LEN(B2))),1)),0),LEN(B2))
獲取自第1個非數字字符開始至數據結尾的部分,本例中為fjk。
單元格H2中,使用數組公式:
=MATCH(FALSE,ISERROR(1*MID(G2,ROW(INDIRECT(“1:”& LEN(B2))),1)),0)
判斷單元格G2中的數據是否還有數字,如果有返回數字的位置值,否則返回#N/A錯誤值。
單元格I2中,公式:
=IF(ISNA(H2),B2,””)
判斷單元格H2中是否是#N/A值,如果是,表明單元格B2中的數據滿足條件,返回單元格B2中的數據;否則不滿足條件,返回空。這樣,就得到了最終的結果。
將上述步驟中使用的公式組合起來,得到一次獲取滿足條件的數據的數組公式:
=IF(ISNA(MATCH(FALSE,ISERROR(1*MID(MID(B2,MATCH(TRUE,ISERROR(1*MID(B2,ROW(INDIRECT(“1:”& LEN(B2))),1)),0),LEN(B2)),ROW(INDIRECT(“1:” &LEN(B2))),1)),0)),B2,””)
將公式下拉,即可得到相應的滿足條件的數據,如上圖1所示。





