擊這里在線咨詢客服")
使用FREQUENCY函數(shù),可以幫助創(chuàng)建頻率分布。例如,計(jì)算某班學(xué)生的語文成績的頻率分布,分別在0~59、60~69、70~79、80~89、90分以上的區(qū)間的學(xué)生數(shù)。
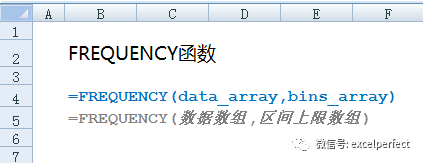
圖1
什么情況下使用FREQUENCY函數(shù)?
FREQUENCY函數(shù)以一列垂直數(shù)組返回一組數(shù)據(jù)的頻率分布。它能夠:
創(chuàng)建學(xué)生成績的頻率分布
創(chuàng)建百分比形式的頻率分布
統(tǒng)計(jì)單元格區(qū)域中不重復(fù)值的數(shù)量
獲取單元格區(qū)域中不重復(fù)值
FREQUENCY函數(shù)語法
FREQUENCY函數(shù)有2個(gè)參數(shù),其語法如下:
FREQUENCY(data_array,bins_array)
data_array: 代表用來計(jì)算頻率的數(shù)組,或者單元格區(qū)域。
bins_array: 由每個(gè)區(qū)間上限數(shù)字組成的數(shù)組或者單元格區(qū)域。
返回的值為一個(gè)數(shù)組,代表每個(gè)區(qū)間的數(shù)值個(gè)數(shù)且該數(shù)組包含的元素?cái)?shù)總比參數(shù)bins_array中的個(gè)數(shù)多1,多出的這個(gè)數(shù)字是Excel自動(dòng)創(chuàng)建的最后一個(gè)區(qū)間中的數(shù)值個(gè)數(shù)。
返回的數(shù)組為垂直數(shù)組,可以使用TRANSPOSE函數(shù)將其轉(zhuǎn)換成水平數(shù)組。
該函數(shù)忽略空單元格和文本。
如果參數(shù)bins_array中有重復(fù)的值,那么重復(fù)的值統(tǒng)計(jì)的數(shù)為0。
FREQUENCY函數(shù)陷阱
在參數(shù)bins_array中,只需指定每個(gè)區(qū)間的上限,但不一定需要指定最后一個(gè)區(qū)間的上限(因?yàn)樗赡苁菬o窮大),它會(huì)自動(dòng)包括在區(qū)間中。由于FREQUENCY函數(shù)的返回值是數(shù)組,因此輸入完成后應(yīng)按Ctrl+Shift+Enter鍵。如果參數(shù)bins_array中有n個(gè)值,那么函數(shù)輸出的區(qū)域應(yīng)該包括n+1個(gè)單元格,否則數(shù)據(jù)會(huì)顯示不全。
FREQUENCY函數(shù)統(tǒng)計(jì)的結(jié)果包括區(qū)間的上限值,但不包括區(qū)間的下限值。如果想統(tǒng)計(jì)的結(jié)果不包括區(qū)間的上限值但包括區(qū)間的下限值,可以使用COUNTIF函數(shù)和COUNTIFS函數(shù)。
示例1: 創(chuàng)建學(xué)生成績的頻率分布
如下圖2的示例工作表,要?jiǎng)?chuàng)建學(xué)生語文成績的頻率分布,即分別在0~59、60~69、70~79、80~89、90分以上的區(qū)間的學(xué)生數(shù),使用數(shù)組公式:
=FREQUENCY(B3:B28,D4:D7)
返回?cái)?shù)組{4;4;5;6;7}。

圖2
示例2: 創(chuàng)建百分比形式的頻率分布
下圖3所示工作表中,命名區(qū)域Data為A1:D9。計(jì)算區(qū)域Data中分別落在0~20、21~40、41~60、61~80、81~100區(qū)間的數(shù)值數(shù)量的公式為:
=FREQUENCY(Data,G3:G7)
這是一個(gè)數(shù)組公式,因此輸入完成后要按Ctrl+Shift+Enter組合鍵。
創(chuàng)建百分比形式的頻率分布的數(shù)組公式為:
=FREQUENCY(Data,G3:G7)/COUNT(Data)
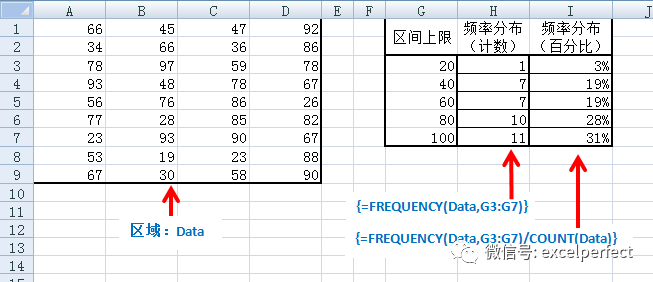
圖3
示例3: 統(tǒng)計(jì)單元格區(qū)域中不重復(fù)值的數(shù)量
有多種方法可以統(tǒng)計(jì)單元格區(qū)域中不重復(fù)值的數(shù)量,使用FREQUENCY函數(shù)是其中的一種。如下圖4所示的工作表,需要統(tǒng)計(jì)列A中有多少唯一的付款賬戶,數(shù)組公式為:
=SUMPRODUCT(–(FREQUENCY(A2:A7,A2:A7)>0))
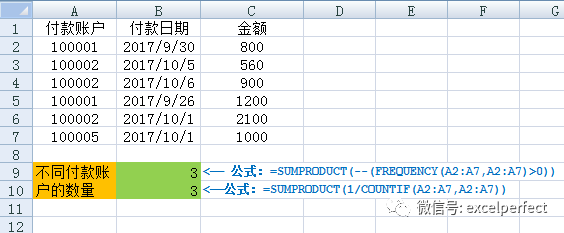
圖4
也可以使用COUNIF函數(shù)進(jìn)行統(tǒng)計(jì),數(shù)組公式為:
=SUMPRODUCT(1/COUNTIF(A2:A7,A2:A7))
如果要統(tǒng)計(jì)的不重復(fù)值的數(shù)據(jù)是文本(如圖5)或者文本和數(shù)據(jù)的混合,例如,統(tǒng)計(jì)圖5列D中不同付款人的數(shù)量,那么可以使用數(shù)組公式:
=SUMPRODUCT(–(FREQUENCY(MATCH(D2:D7,D2:D7,0),ROW(D2:D7)-ROW(D2)+1)>0))
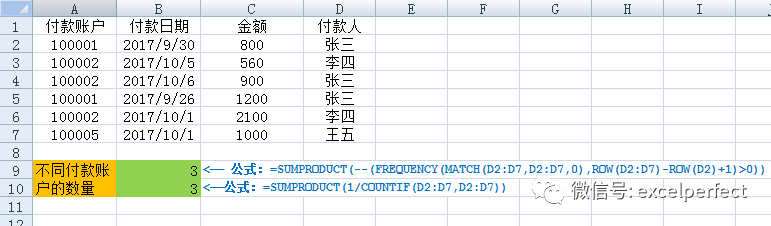
圖5
當(dāng)然,此時(shí)使用COUNTIF函數(shù)的公式將更簡單。
如果要統(tǒng)計(jì)滿足多于1個(gè)條件的不重復(fù)值的數(shù)量,例如下圖6所示的工作表,要統(tǒng)計(jì)付款日期為2017年9月30日之后且付款金額大于等于1000的唯一付款賬戶數(shù),在單元格D9中輸入指定的日期,單元格D10中輸入金額,那么數(shù)組公式為:
=SUM(IF(FREQUENCY(IF(B2:B7>D9,IF(C2:C7>=D10,MATCH(A2:A7,A2:A7,0))),ROW(A2:A7)-ROW(A2)+1),1))
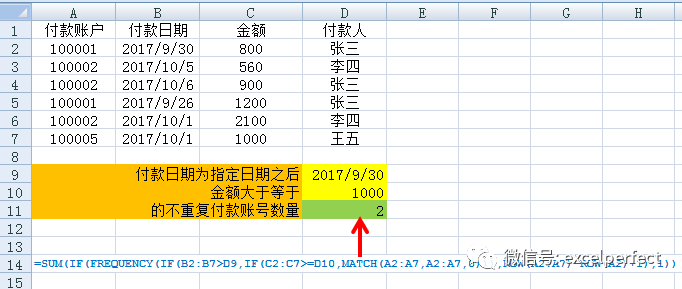
圖6
示例4: 獲取單元格區(qū)域中不重復(fù)值
上面的示例統(tǒng)計(jì)了單元格區(qū)域中不重復(fù)值的數(shù)量,下面獲取該工作表中不重復(fù)的付款人列表。如圖7所示,在單元格B13中輸入數(shù)組公式:
=IF(ROWS(B$13:B13)>$B$9,””,INDEX($D$2:$D$7,SMALL(IF(FREQUENCY(IF($D$2:$D$7<>””,MATCH($D$2:$D$7,$D$2:$D$7,0)),ROW($D$2:$D$7)-ROW($D$2)+1),ROW($D$2:$D$7)-ROW($D$2)+1),ROWS(B$13:B13))))
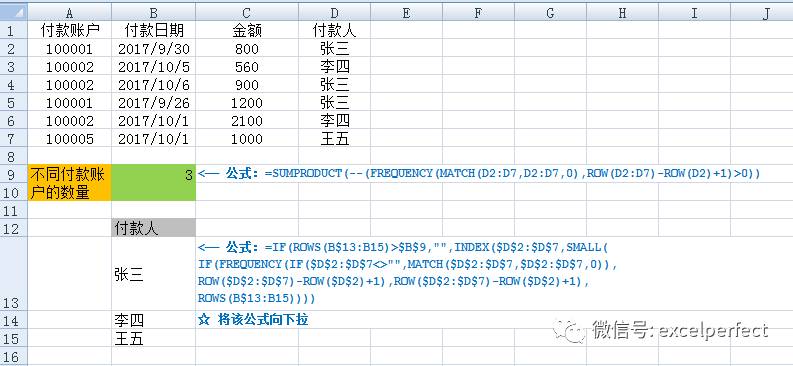
圖7
將單元格B13向下拉獲取不重復(fù)的付款人列表。





