
如下圖1所示,在單元格區域A1:A10中有一些數據。現在,想從該區域中提取單詞并創建唯一值列表,如列B中的數據所示。
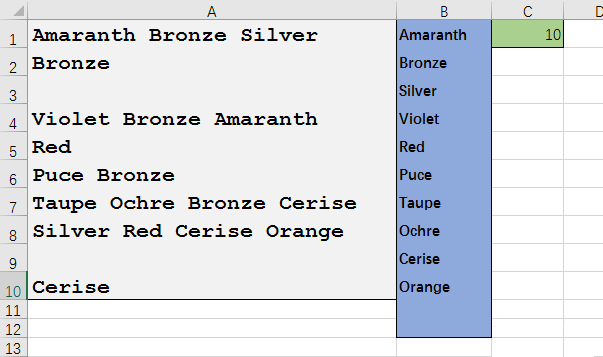
圖3
在單元格B2中,計算列表中返回的唯一值個數:
=SUMPRODUCT((A2:A10<>””)/(COUNTIF(A2:A10,A2:A10&””)))
在列D中,使用FREQUENCY函數來獲取唯一值列表。在單元格D2中輸入數組公式:
=IF(ROWS($1:1)>$B$2,””,INDEX($A$2:$A$10,SMALL(IF(FREQUENCY(IF($A$2:$A$10<>””,MATCH($A$2:$A$10,$A$2:$A$10,0)),ROW($A$2:$A$10)-MIN(ROW($A$2:$A$10))+1),ROW($A$2:$A$10)-MIN(ROW($A$2:$A$10))+1),ROWS($1:1))))
下拉至出現空單元格為止。
在列E中,使用COUNTIF函數來獲取唯一值列表。在單元格E2中輸入數組公式:
=IF(ROWS($1:1)>$B$2,””,INDEX($A$2:$A$10,MATCH(0,IF($A$2:$A$10<>””,COUNTIF(E$1:E1,$A$2:$A$10&””)),0)))
下拉至出現空單元格為止。
(作者個人傾向于使用第1個公式,更靈活且比COUNTIF版本要更快,特別是,想要從中獲得唯一值的數組是從公式中的其他函數生成的數組的情形下。COUNTIF函數的缺點在于傳遞給它的參數必須是實際的工作表區域引用。)
從上面的示例中可以看出,FREQUENCY函數可以處理單行或單列數組,而我們這里生成的是10行4列數組,那么FREQUENCY函數可以處理這樣的二維數組嗎?不幸的是,答案是否定的。雖然INDEX、SMALL和FREQUENCY函數可以處理這類數組,但MATCH函數不能,傳遞給它的lookup_array參數必須是單行或單列。
因此,我們需要采用一種將這里的數組轉換成單行或單列數組的技術。
(3)回到前面,現在定義名稱Arry3的公式可以轉換成:
INDEX({“Amaranth”,”Bronze”,”Silver”,””;”Bronze”,””,””,””;””,””,””,””;”Violet”,”Bronze”,”Amaranth”,””;”Red”,””,””,””;”Puce”,”Bronze”,””,””;”Taupe”,”Ochre”,”Bronze”,”Cerise”;”Silver”,”Red”,”Cerise”,”Orange”;””,””,””,””;”Cerise”,””,””,””},N(IF(1,1+INT((Arry2-1)/MAX(Arry1)))),N(IF(1,1+MOD(Arry2-1,MAX(Arry1)))))
我們可以看到,這里對INDEX的行參數和列參數使用了兩個構造:
N(IF(1,1+INT((Arry2-1)/MAX(Arry1))))
和
N(IF(1,1+MOD(Arry2-1,MAX(Arry1))))
這里引用了名稱Arry2:
ROW(INDIRECT(“1:”& (MAX(Arry1)*ROWS(Data))))
上文中已計算出Arry1的最大值為4,Data中的行數為10,因此上面的公式轉換為:
ROW(INDIRECT(“1:” & 40))
于是,Arry2為由1至40組成的單列數組:
{1;2;3;4;5;6;7;8;9;10;11;12;13;14;15;16;17;18;19;20;21;22;23;24;25;26;27;28;29;30;31;32;33;34;35;36;37;38;39;40}
這樣,上述構造中的:
1+INT((Arry2-1)/MAX(Arry1))
成為:
1+INT(({1;2;3;4;5;6;7;8;9;10;11;12;13;14;15;16;17;18;19;20;21;22;23;24;25;26;27;28;29;30;31;32;33;34;35;36;37;38;39;40}-1)/4)
轉換為:
1+INT({0;0.25;0.5;0.75;1;1.25;1.5;1.75;2;2.25;2.5;2.75;3;3.25;3.5;3.75;4;4.25;4.5;4.75;5;5.25;5.5;5.75;6;6.25;6.5;6.75;7;7.25;7.5;7.75;8;8.25;8.5;8.75;9;9.25;9.5;9.75})
轉換為:
1+{0;0;0;0;1;1;1;1;2;2;2;2;3;3;3;3;4;4;4;4;5;5;5;5;6;6;6;6;7;7;7;7;8;8;8;8;9;9;9;9}
結果為:
{1;1;1;1;2;2;2;2;3;3;3;3;4;4;4;4;5;5;5;5;6;6;6;6;7;7;7;7;8;8;8;8;9;9;9;9;10;10;10;10}
同樣,列參數構造中的:
1+MOD(Arry2-1,MAX(Arry1))
可以轉換為:
{1;2;3;4;1;2;3;4;1;2;3;4;1;2;3;4;1;2;3;4;1;2;3;4;1;2;3;4;1;2;3;4;1;2;3;4;1;2;3;4}
由于這兩個數組都具有相同的向量位移(即它們都是單列數組),我們知道,將它們傳遞給INDEX函數進行處理時,這些數組中相對應的元素將被“配對”,因此我們將指示INDEX返回一個值數組,其row_num和col_num參數將依次為:1/1、1/2、1/3、1/4、2/1、2/2、2/3、2/4、3/1,…,依此類推。也就是說,我們將依次從上文生成的10行4列的數組中取值。
現在定義名稱Arry3的公式可以轉換成:
INDEX({“Amaranth”,”Bronze”,”Silver”,””;”Bronze”,””,””,””;””,””,””,””;”Violet”,”Bronze”,”Amaranth”,””;”Red”,””,””,””;”Puce”,”Bronze”,””,””;”Taupe”,”Ochre”,”Bronze”,”Cerise”;”Silver”,”Red”,”Cerise”,”Orange”;””,””,””,””;”Cerise”,””,””,””},{1;1;1;1;2;2;2;2;3;3;3;3;4;4;4;4;5;5;5;5;6;6;6;6;7;7;7;7;8;8;8;8;9;9;9;9;10;10;10;10},{1;2;3;4;1;2;3;4;1;2;3;4;1;2;3;4;1;2;3;4;1;2;3;4;1;2;3;4;1;2;3;4;1;2;3;4;1;2;3;4})
轉換成最終的結果:
{“Amaranth”;”Bronze”;”Silver”;””;”Bronze”;””;””;””;””;””;””;””;”Violet”;”Bronze”;”Amaranth”;””;”Red”;””;””;””;”Puce”;”Bronze”;””;””;”Taupe”;”Ochre”;”Bronze”;”Cerise”;”Silver”;”Red”;”Cerise”;”Orange”;””;””;””;””;”Cerise”;””;””;””}
至此,成功地將原來的10行4列數組轉換成40行1列的數組。這樣,就可以將這個數組傳遞給MATCH函數而不會出錯了。
注意,在上述構造中,前面的部分為N(IF(1,是為了強制INDEX返回數組,詳細原因參見《Excel公式技巧03:INDEX函數,給公式提供數組》。
2. 使用Arry3替換掉上文中使用FREQUENCY函數求唯一值的公式中的單元格區域,并進行適當的調整,得到單元格B2中的公式:
=IF(ROWS($1:1)>$C$1,””,INDEX(Arry3,SMALL(IF(FREQUENCY(IF(Arry3<>””,MATCH(Arry3,Arry3,0)),Arry2),Arry2),ROWS($1:1))))
3. 對于單元格C1中求唯一值個數的公式:
=SUM((Arry3<>””)/MMULT(0+(Arry3=TRANSPOSE(Arry3)),ROW(INDIRECT(“1:”& COUNTA(Arry3)))^0))
(1)Arry3中的元素是否為空進行比較,得到數組:
{TRUE;TRUE;TRUE;FALSE;TRUE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;TRUE;TRUE;TRUE;FALSE;TRUE;FALSE;FALSE;FALSE;TRUE;TRUE;FALSE;FALSE;TRUE;TRUE;TRUE;TRUE;TRUE;TRUE;TRUE;TRUE;FALSE;FALSE;FALSE;FALSE;TRUE;FALSE;FALSE;FALSE}
(2)看看MMULT中的第二個數組:
ROW(INDIRECT(“1:” &COUNTA(Arry3)))^0
我們已經知道Arry3中元素個數為40,因此上述數組為:
{1;2;3;4;5;6;7;8;9;10;11;12;13;14;15;16;17;18;19;20;21;22;23;24;25;26;27;28;29;30;31;32;33;34;35;36;37;38;39;40}^0
結果為:
{1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1;1}
(3)看看MMULT中的第一個數組:
0+(Arry3=TRANSPOSE(Arry3))
這將轉換成40行40列的數組。由于數組太大,為了方便解釋其原理,將數據區域Data縮減為A1:A2,這樣Arry3為:
{“Amaranth”;”Bronze”;”Silver”;”Bronze”;””;””}
此時,MMULT中的第一個數組轉換為:
0+({“Amaranth”;”Bronze”;”Silver”;”Bronze”;””;””}={“Amaranth”,”Bronze”,”Silver”,”Bronze”,””,””})
兩個正交數組比較后的結果為:
0+{TRUE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,TRUE,FALSE,TRUE,FALSE,FALSE;FALSE,FALSE,TRUE,FALSE,FALSE,FALSE;FALSE,TRUE,FALSE,TRUE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,TRUE,TRUE;FALSE,FALSE,FALSE,FALSE,TRUE,TRUE}
加上0強制轉換為1/0組成的數組:
{1,0,0,0,0,0;0,1,0,1,0,0;0,0,1,0,0,0;0,1,0,1,0,0;0,0,0,0,1,1;0,0,0,0,1,1}
(4)此時,MMULT公式為:
MMULT({1,0,0,0,0,0;0,1,0,1,0,0;0,0,1,0,0,0;0,1,0,1,0,0;0,0,0,0,1,1;0,0,0,0,1,1},{1;1;1;1;1;1})
得到:
{1;2;1;2;2;2}
(5)此時,SUM公式為:
=SUM({TRUE;TRUE;TRUE;TRUE;FALSE;FALSE}/{1;2;1;2;2;2})
轉換為:
=SUM({1;0.5;1;0.5;0;0})
結果為3。表明如果數據區域為A1:A2,有3個唯一值。
(6)回到示例中的數據區域A1:A10,此時的SUM公式為:
=SUM({TRUE;TRUE;TRUE;FALSE;TRUE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;TRUE;TRUE;TRUE;FALSE;TRUE;FALSE;FALSE;FALSE;TRUE;TRUE;FALSE;FALSE;TRUE;TRUE;TRUE;TRUE;TRUE;TRUE;TRUE;TRUE;FALSE;FALSE;FALSE;FALSE;TRUE;FALSE;FALSE;FALSE}/{2;5;2;21;5;21;21;21;21;21;21;21;1;5;2;21;2;21;21;21;1;5;21;21;1;1;5;3;2;2;3;1;21;21;21;21;3;21;21;21})
轉換為:
=SUM({0.5;0.2;0.5;0;0.2;0;0;0;0;0;0;0;1;0.2;0.5;0;0.5;0;0;0;1;0.2;0;0;1;1;0.2;0.333333333333333;0.5;0.5;0.333333333333333;1;0;0;0;0;0.333333333333333;0;0;0})
結果為10。表明數據區域A1:A10中有10個唯一值。
小結
解決本案例的過程是,首先從原來的以空格分隔的字符串中生成子字符串數組,重新構建該數組,以便能夠對其進行處理。我們從本案例中至少可以學到:
1. 使用大量的空格替換來拆分由分隔符分隔的字符串。
2. 從列表中獲取唯一值的標準公式。
3. 將二維數組轉換成一維數組的方法。





