
本次的練習是:如下圖1所示,單元格區域A2:E5中包含一系列值和空單元格,其中有重復值,要求從該單元格區域中生成按字母順序排列的不重復值列表,如圖1中G列所示。
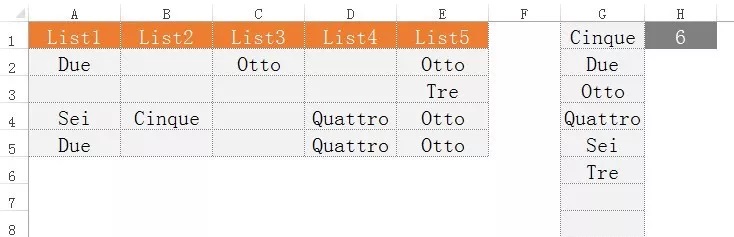
圖1
在單元格G1中編寫一個公式,下拉生成所要求的列表。
先不看答案,自已動手試一試。
公式
在單元格G1中的公式為:
=IF(ROWS($1:1)>$H$1,””,INDEX(Arry4,MATCH(SMALL(IF(FREQUENCY(IF(Range1<>””,MATCH(Range1,Arry4,0)),Arry1),COUNTIF(Range1,”<“&Arry4)),ROWS($1:1)),IF(Arry4<>””,COUNTIF(Range1,”<“&Arry4)),0)))
下拉直至出現空單元格為止。
在單元格H1中的公式為:
=SUMPRODUCT((Range1<>””)/COUNTIF(Range1,Range1&””))
公式中使用了5個名稱,分別為:
名稱:Range1
引用位置:=$A$2:$E$5
名稱:Arry1
引用位置:=ROW(INDIRECT(“1:”&COLUMNS(Range1)*ROWS(Range1)))
名稱:Arry2
引用位置:=1+INT((Arry1-1)/COLUMNS(Range1))
名稱:Arry3
引用位置:=1+MOD(Arry1-1,COLUMNS(Range1))
名稱:Arry4
引用位置:=INDEX(Range1,N(IF(1,Arry2)),N(IF(1,Arry3)))
公式解析
1. 在單元格H1中的公式比較直接,是一個獲取列表區域唯一值數量的標準公式:
=SUMPRODUCT((Range1<>””)/COUNTIF(Range1,Range1&””))
轉換為:
=SUMPRODUCT(({“Due”,””,”Otto”,””,”Otto”;””,””,””,””,”Tre”;”Sei”,”Cinque”,””,”Quattro”,”Otto”;”Due”,””,””,”Quattro”,”Otto”}<>””)/COUNTIF(Range1,Range1&””))
轉換為:
=SUMPRODUCT({TRUE,FALSE,TRUE,FALSE,TRUE;FALSE,FALSE,FALSE,FALSE,TRUE;TRUE,TRUE,FALSE,TRUE,TRUE;TRUE,FALSE,FALSE,TRUE,TRUE}/COUNTIF(Range1,Range1&””))
接著解析COUNTIF部分,該部分計算Range1中每個條目在該區域內出現的次數:
=SUMPRODUCT({TRUE,FALSE,TRUE,FALSE,TRUE;FALSE,FALSE,FALSE,FALSE,TRUE;TRUE,TRUE,FALSE,TRUE,TRUE;TRUE,FALSE,FALSE,TRUE,TRUE}/{2,9,4,9,4;9,9,9,9,1;1,1,9,2,4;2,9,9,2,4})
除法運算后:
=SUMPRODUCT({0.5,0,0.25,0,0.25;0,0,0,0,1;1,1,0,0.5,0.25;0.5,0,0,0.5,0.25})
結果為:
6
2. 在單元格G1的主公式中:
=IF(ROWS($1:1)>$H$1,””,
如果公式向下拖拉的行數超過單元格H1中的數值6,則返回空值。
3. 下面重點看看公式中的:
INDEX(Arry4,MATCH(SMALL(IF(FREQUENCY(IF(Range1<>””,MATCH(Range1,Arry4,0)),Arry1),COUNTIF(Range1,”<“&Arry4)),ROWS($1:1)),IF(Arry4<>””,COUNTIF(Range1,”<“&Arry4)),0))
實際上,這是提取唯一且按字母順序排列的值的標準公式構造,唯一區別是提取值的區域不是單列、一維區域,而是二維區域。然而,在原理上該技術是相同的:首先將二維區域轉換成一維區域,然后應用通用的結構來獲取我們想要的結果。
上述公式構造中的Arry4為:
INDEX(Range1,N(IF(1,Arry2)),N(IF(1,Arry3)))
這里,只是簡單地索引二維區域中的每個元素。然而,我們得到的結果數組將是一維數組且包含的元素與二維區域中的元素完全相同。
為了解構Arry4,我們需要首先查看Arry2和Arry3,它們分別對應著INDEX函數的參數row_num和參數column_num。而它們都引用了Arry1:
=ROW(INDIRECT(“1:”&COLUMNS(Range1)*ROWS(Range1)))
名稱Range1代表的區域有4行5列,因此轉換為:
ROW(INDIRECT(“1:”&5*4))
得到:
{1;2;3;4;5;6;7;8;9;10;11;12;13;14;15;16;17;18;19;20}
再看Arry2:
=1+INT((Arry1-1)/COLUMNS(Range1))
轉換為:
1+INT(({1;2;3;4;5;6;7;8;9;10;11;12;13;14;15;16;17;18;19;20}-1)/5)
轉換為:
1+INT({0;1;2;3;4;5;6;7;8;9;10;11;12;13;14;15;16;17;18;19}/5)
轉換為:
1+INT({0;0.2;0.4;0.6;0.8;1;1.2;1.4;1.6;1.8;2;2.2;2.4;2.6;2.8;3;3.2;3.4;3.6;3.8})
轉換為:
1+{0;0;0;0;0;1;1;1;1;1;2;2;2;2;2;3;3;3;3;3}
得到:
{1;1;1;1;1;2;2;2;2;2;3;3;3;3;3;4;4;4;4;4}
接著看Arry3:
=1+MOD(Arry1-1,COLUMNS(Range1))
轉換為:
1+MOD({0;1;2;3;4;5;6;7;8;9;10;11;12;13;14;15;16;17;18;19},5)
轉換為:
1+{0;1;2;3;4;0;1;2;3;4;0;1;2;3;4;0;1;2;3;4}
得到:
{1;2;3;4;5;1;2;3;4;5;1;2;3;4;5;1;2;3;4;5}
再回到Arry4。可以轉換為:
INDEX(Range1,N(IF(1,{1;1;1;1;1;2;2;2;2;2;3;3;3;3;3;4;4;4;4;4})),N(IF(1,{1;2;3;4;5;1;2;3;4;5;1;2;3;4;5;1;2;3;4;5})))
這里使用了強制INDEX返回數組的技術,詳情可參閱《Excel公式技巧03:INDEX函數,給公式提供數組》。上述公式可轉換為:
INDEX(Range1,{1;1;1;1;1;2;2;2;2;2;3;3;3;3;3;4;4;4;4;4},{1;2;3;4;5;1;2;3;4;5;1;2;3;4;5;1;2;3;4;5})
現在應該可以看清楚為INDEX函數的每個參數傳遞數組的原因了,因為上述公式等價于執行下列每個公式:
INDEX(Range1,1,1)
INDEX(Range1,1,2)
INDEX(Range1,1,3)
INDEX(Range1,1,4)
INDEX(Range1,1,5)
INDEX(Range1,2,1)
INDEX(Range1,2,2)
…
INDEX(Range1,4,5)
因此,Arry4的結果為:
{“Due”;””;”Otto”;””;”Otto”;””;””;””;””;”Tre”;”Sei”;”Cinque”;””;”Quattro”;”Otto”;”Due”;””;””;”Quattro”;”Otto”}
而Excel將Range1解析為:
{“Due”,””,”Otto”,””,”Otto”;””,””,””,””,”Tre”;”Sei”,”Cinque”,””,”Quattro”,”Otto”;”Due”,””,””,”Quattro”,”Otto”}
我們可以看到這兩個數組中的值沒有任何區別。唯一不同的是,Range1包含一個4行5列的二維數組,而Arry4是通過簡單地將Range1中的每個元素進行索引而得出的,實際上是20行1列的一維區域。
好了,現在就可以使用我們掌握的常用的適用于一維區域的技術來操作該數組了!
4. 再看看主公式中的:
INDEX(Arry4,MATCH(SMALL(IF(FREQUENCY(IF(Range1<>””,MATCH(Range1,Arry4,0)),Arry1),COUNTIF(Range1,”<“&Arry4)),ROWS($1:1)),IF(Arry4<>””,COUNTIF(Range1,”<“&Arry4)),0))
先看看這部分:
IF(Range1<>””,MATCH(Range1,Arry4,0))
轉換為:
IF({TRUE,FALSE,TRUE,FALSE,TRUE;FALSE,FALSE,FALSE,FALSE,TRUE;TRUE,TRUE,FALSE,TRUE,TRUE;TRUE,FALSE,FALSE,TRUE,TRUE},MATCH(Range1,Arry4,0))
使用Range1和Arry4替換,得到:
IF({TRUE,FALSE,TRUE,FALSE,TRUE;FALSE,FALSE,FALSE,FALSE,TRUE;TRUE,TRUE,FALSE,TRUE,TRUE;TRUE,FALSE,FALSE,TRUE,TRUE},MATCH({“Due”,””,”Otto”,””,”Otto”;””,””,””,””,”Tre”;”Sei”,”Cinque”,””,”Quattro”,”Otto”;”Due”,””,””,”Quattro”,”Otto”},{“Due”;””;”Otto”;””;”Otto”;””;””;””;””;”Tre”;”Sei”;”Cinque”;””;”Quattro”;”Otto”;”Due”;””;””;”Quattro”;”Otto”},0))
可轉換為:
IF({TRUE,FALSE,TRUE,FALSE,TRUE;FALSE,FALSE,FALSE,FALSE,TRUE;TRUE,TRUE,FALSE,TRUE,TRUE;TRUE,FALSE,FALSE,TRUE,TRUE},{1,#N/A,3,#N/A,3;#N/A,#N/A,#N/A,#N/A,10;11,12,#N/A,14,3;1,#N/A,#N/A,14,3})
得到:
{1,FALSE,3,FALSE,3;FALSE,FALSE,FALSE,FALSE,10;11,12,FALSE,14,3;1,FALSE,FALSE,14,3}
這個數組是FREQUENCY函數的第一個參數,而Arry1是其第二個參數:
FREQUENCY(IF(Range1<>””,MATCH(Range1,Arry4,0)),Arry1)
可轉換為:
FREQUENCY({1,FALSE,3,FALSE,3;FALSE,FALSE,FALSE,FALSE,10;11,12,FALSE,14,3;1,FALSE,FALSE,14,3},Arry1)
將Arry1代入:
FREQUENCY({1,FALSE,3,FALSE,3;FALSE,FALSE,FALSE,FALSE,10;11,12,FALSE,14,3;1,FALSE,FALSE,14,3},{1;2;3;4;5;6;7;8;9;10;11;12;13;14;15;16;17;18;19;20})
生成數組:
{2;0;4;0;0;0;0;0;0;1;1;1;0;2;0;0;0;0;0;0;0}
這是我們使用的相當標準的技術:上述數組中非零值的位置表示在該區域內每個不同值在該數組中的首次出現,因此提供了一種僅返回唯一值的方法。將該數組作為IF函數的條件:
IF(FREQUENCY(IF(Range1<>””,MATCH(Range1,Arry4,0)),Arry1),COUNTIF(Range1,”<“&Arry4))
轉換為:
IF({2;0;4;0;0;0;0;0;0;1;1;1;0;2;0;0;0;0;0;0;0},COUNTIF(Range1,”<“&Arry4))
COUNTIF函數用于確定字母排序:
IF({2;0;4;0;0;0;0;0;0;1;1;1;0;2;0;0;0;0;0;0;0},{1;0;3;0;3;0;0;0;0;10;9;0;0;7;3;1;0;0;7;3})
結果為:
{1;FALSE;3;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;10;9;0;FALSE;7;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE}
這樣,INDEX函數部分現在變成:
INDEX(Arry4,MATCH(SMALL({1;FALSE;3;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;10;9;0;FALSE;7;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE;FALSE},ROWS($1:1)),IF(Arry4<>””,COUNTIF(Range1,”<“&Arry4)),0))
對于SMALL函數,其參數k的值由ROWS($1:1)指定,在單元格G1中為1,因此上述公式轉換為:
INDEX(Arry4,MATCH(0,IF(Arry4<>””,COUNTIF(Range1,”<“&Arry4)),0))
轉換為:
INDEX(Arry4,MATCH(0,IF(Arry4<>””,{1;0;3;0;3;0;0;0;0;10;9;0;0;7;3;1;0;0;7;3},0))
轉換為:
INDEX(Arry4,MATCH(0,{1;FALSE;3;FALSE;3;FALSE;FALSE;FALSE;FALSE;10;9;0;FALSE;7;3;1;FALSE;FALSE;7;3},0))
轉換為:
INDEX(Arry4,12)
將Arry4代入:
INDEX({“Due”;””;”Otto”;””;”Otto”;””;””;””;””;”Tre”;”Sei”;”Cinque”;””;”Quattro”;”Otto”;”Due”;””;””;”Quattro”;”Otto”},12)
得到結果:
Cinque
小結:
本文至少復習/使用了以下公式技術:
1. 統計列表區域中唯一值數量。
2. 將二維區域轉換成一維區域。
3. 強制INDEX返回數組。
4. 確定字母排序。
5. 提取唯一值并按字母排序。





