
有一個包含數字和空的單元格區域,如下圖1所示示例的單元格區域A1:F6,要求生成這些數字的唯一值,并按數字出現的頻率順序排列,出現頻率高的排在前面,如果幾個數字出現的頻率相同,則數字小的排在前面,如圖1中列I所示。
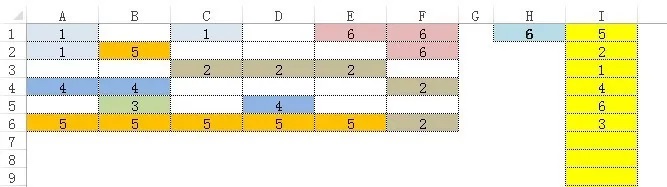
圖1
先不看答案,自已動手試一試。
公式
在單元格I1中的數組公式為:
=IF(ROWS($1:1)>$H$1,””,MIN(IF(IF(Range1<>””,COUNTIF(Range1,Range1)+1/(Range1*10^6))=LARGE(IF(INDEX(FREQUENCY(0+(Range1&0),0+(Range1&0)),N(IF(1,COLUMNS(Range1)*Arry2-TRANSPOSE(COLUMNS(Range1)-Arry1)))),IF(Range1<>””,COUNTIF(Range1,Range1)+1/(Range1*10^6))),ROWS($1:1)),Range1)))
向下拖拉至出現空單元格為止。
單元格H1中為返回的數字數量,公式為:
=SUMPRODUCT((Range1<>””)/COUNTIF(Range1,Range1&””))
公式解析
在公式中,使用了3個名稱,分別為:
名稱:Range1
引用位置:=$A$1:$F$6
名稱:Arry1
引用位置:=ROW(INDIRECT(“1:”&COLUMNS(Range1)))
名稱:Arry2
引用位置:=ROW(INDIRECT(“1:”&ROWS(Range1)))
單元格H1中的公式是一種用于確定單元格區域內不同元素數量的標準公式結構。公式:
=SUMPRODUCT((Range1<>””)/COUNTIF(Range1,Range1&””))
轉換為:
=SUMPRODUCT(({1,””,1,””,6,6;1,5,””,””,””,6;””,””,2,2,2,””;4,4,””,””,””,2;””,3,””,4,””,””;5,5,5,5,5,2}<>””)/COUNTIF(Range1,Range1&””))
轉換為:
=SUMPRODUCT(({TRUE,FALSE,TRUE,FALSE,TRUE,TRUE;TRUE,TRUE,FALSE,FALSE,FALSE,TRUE;FALSE,FALSE,TRUE,TRUE,TRUE,FALSE;TRUE,TRUE,FALSE,FALSE,FALSE,TRUE;FALSE,TRUE,FALSE,TRUE,FALSE,FALSE;TRUE,TRUE,TRUE,TRUE,TRUE,TRUE})/COUNTIF(Range1,Range1&””))
公式中的COUNTIF(Range1,Range1&””)用來計算Range1區域中每個元素出現的次數,注意到在COUNTIF函數的第2個參數中添加了空字符串,其主要原因詳解如下:
假設不添加空字符串,則為:
COUNTIF(Range1,Range1)
Excel首先會解析其第二個參數criteria:
COUNTIF(Range1,{1,0,1,0,6,6;1,5,0,0,0,6;0,0,2,2,2,0;4,4,0,0,0,2;0,3,0,4,0,0;5,5,5,5,5,2}))
然后解析其第一個參數range:
COUNTIF({1,””,1,””,6,6;1,5,””,””,””,6;””,””,2,2,2,””;4,4,””,””,””,2;””,3,””,4,””,””;5,5,5,5,5,2},{1,0,1,0,6,6;1,5,0,0,0,6;0,0,2,2,2,0;4,4,0,0,0,2;0,3,0,4,0,0;5,5,5,5,5,2}))
由于在第一個數組中沒有0,因此結果為:
{3,0,3,0,3,3;3,6,0,0,0,3;0,0,5,5,5,0;3,3,0,0,0,5;0,1,0,3,0,0;6,6,6,6,6,5}
這意味著,將其作為除法的分母時,結果數組中將包含#DIV/0!,這將導致SUMPRODUCT函數出錯。
通過在第二個參數指定的值后添加一個空字符串,Excel將空單元格解析為空字符串而不是0,因此公式:
COUNTIF(Range1,Range1&””)
解析為:
COUNTIF(Range1,{“1″,””,”1″,””,”6″,”6″;”1″,”5″,””,””,””,”6″;””,””,”2″,”2″,”2″,””;”4″,”4″,””,””,””,”2″;””,”3″,””,”4″,””,””;”5″,”5″,”5″,”5″,”5″,”2″})
這樣,已轉換的:
=SUMPRODUCT(({TRUE,FALSE,TRUE,FALSE,TRUE,TRUE;TRUE,TRUE,FALSE,FALSE,FALSE,TRUE;FALSE,FALSE,TRUE,TRUE,TRUE,FALSE;TRUE,TRUE,FALSE,FALSE,FALSE,TRUE;FALSE,TRUE,FALSE,TRUE,FALSE,FALSE;TRUE,TRUE,TRUE,TRUE,TRUE,TRUE})/COUNTIF(Range1,Range1&””))
轉換為:
=SUMPRODUCT({TRUE,FALSE,TRUE,FALSE,TRUE,TRUE;TRUE,TRUE,FALSE,FALSE,FALSE,TRUE;FALSE,FALSE,TRUE,TRUE,TRUE,FALSE;TRUE,TRUE,FALSE,FALSE,FALSE,TRUE;FALSE,TRUE,FALSE,TRUE,FALSE,FALSE;TRUE,TRUE,TRUE,TRUE,TRUE,TRUE}/{3,15,3,15,3,3;3,6,15,15,15,3;15,15,5,5,5,15;3,3,15,15,15,5;15,1,15,3,15,15;6,6,6,6,6,5})
轉換為:
=SUMPRODUCT({0.333333333333333,0,0.333333333333333,0,0.333333333333333,0.333333333333333;0.333333333333333,0.166666666666667,0,0,0,0.333333333333333;0,0,0.2,0.2,0.2,0;0.333333333333333,0.333333333333333,0,0,0,0.2;0,1,0,0.333333333333333,0,0;0.166666666666667,0.166666666666667,0.166666666666667,0.166666666666667,0.166666666666667,0.2})
得到結果:
6
因此,將單元格I1中的公式向下拖拉時,超過6個單元格將返回空,也就是公式的開頭部分:
=IF(ROWS($1:1)>$H$1,””,
下面看看公式中的主要構造:
MIN(IF(IF(Range1<>””,COUNTIF(Range1,Range1)+1/(Range1*10^6))=LARGE(IF(INDEX(FREQUENCY(0+(Range1&0),0+(Range1&0)),N(IF(1,COLUMNS(Range1)*Arry2-TRANSPOSE(COLUMNS(Range1)-Arry1)))),IF(Range1<>””,COUNTIF(Range1,Range1)+1/(Range1*10^6))),ROWS($1:1)),Range1))
其中的:
COUNTIF(Range1,Range1)+1/(Range1*10^6)
將為單元格區域內的每個值生成一個計數數組,這很重要,因為問題的癥結在于根據值在該區域內的頻率返回值。使用額外的子句的原因是為我們提供一種方法,使我們可以區分在區域內兩個或多個值出現頻率相同的情況。更重要的是,此子句的目的是在這種情況下首先返回較小的值。
上述部分公式轉換為:
{3,0,3,0,3,3;3,6,0,0,0,3;0,0,5,5,5,0;3,3,0,0,0,5;0,1,0,3,0,0;6,6,6,6,6,5}+1/({1000000,0,1000000,0,6000000,6000000;1000000,5000000,0,0,0,6000000;0,0,2000000,2000000,2000000,0;4000000,4000000,0,0,0,2000000;0,3000000,0,4000000,0,0;5000000,5000000,5000000,5000000,5000000,2000000})
注意,如果區域內有任何空字符串,那么這里將會解析為#VALUE!錯誤,然而該部分之前的IF子句——IF(Range1<>””將意味著不會考慮這些錯誤值。上面的結果轉換為:
{3,0,3,0,3,3;3,6,0,0,0,3;0,0,5,5,5,0;3,3,0,0,0,5;0,1,0,3,0,0;6,6,6,6,6,5}+{0.000001,#DIV/0!,0.000001,#DIV/0!,1.66666666666667E-07,1.66666666666667E-07;0.000001,0.0000002,#DIV/0!,#DIV/0!,#DIV/0!,1.66666666666667E-07;#DIV/0!,#DIV/0!,0.0000005,0.0000005,0.0000005,#DIV/0!;0.00000025,0.00000025,#DIV/0!,#DIV/0!,#DIV/0!,0.0000005;#DIV/0!,3.33333333333333E-07,#DIV/0!,0.00000025,#DIV/0!,#DIV/0!;0.0000002,0.0000002,0.0000002,0.0000002,0.0000002,0.0000005}
得到:
{3.000001,#DIV/0!,3.000001,#DIV/0!,3.00000016666667,3.00000016666667;3.000001,6.0000002,#DIV/0!,#DIV/0!,#DIV/0!,3.00000016666667;#DIV/0!,#DIV/0!,5.0000005,5.0000005,5.0000005,#DIV/0!;3.00000025,3.00000025,#DIV/0!,#DIV/0!,#DIV/0!,5.0000005;#DIV/0!,1.00000033333333,#DIV/0!,3.00000025,#DIV/0!,#DIV/0!;6.0000002,6.0000002,6.0000002,6.0000002,6.0000002,5.0000005}
同樣,其中的任何錯誤值將在下面解決:
IF(Range1<>””,COUNTIF(Range1,Range1)+1/(Range1*10^6))
轉換為:
{3.000001,FALSE,3.000001,FALSE,3.00000016666667,3.00000016666667;3.000001,6.0000002,FALSE,FALSE,FALSE,3.00000016666667;FALSE,FALSE,5.0000005,5.0000005,5.0000005,FALSE;3.00000025,3.00000025,FALSE,FALSE,FALSE,5.0000005;FALSE,1.00000033333333,FALSE,3.00000025,FALSE,FALSE;6.0000002,6.0000002,6.0000002,6.0000002,6.0000002,5.0000005}
在此數組中,例如值3.000001、3.00000016666667和3.00000025分別表示在Range1內出現的1、6和4這三個值,其小數部分可進行區分。
現在,我們需要一種方法,該方法可用于從該數組中標識唯一值并將它們按降序排列,即:
6.0000002
5.0000005
3.000001
3.00000025
3.00000016666667
1.00000033333333
然后將它們與原始值進行匹配,我們知道上述值分別代表5出現了6次、2出現了5次、1出現了3次、4出現了3次、6出現了3次、3出現了1次。
為了將我們的數組限制為僅考慮唯一值的數組,公式中使用以下部分:
FREQUENCY(0+(Range1&0),0+(Range1&0))
將轉換為:
{3;15;0;0;3;0;0;6;0;0;0;0;0;0;5;0;0;0;3;0;0;0;0;0;0;1;0;0;0;0;0;0;0;0;0;0;0}
在上面的數組中我們突出顯示了非零值,與下面數組中突出顯示值相對應(忽略數組維度):
{1,””,1,””,6,6;1,5,””,””,””,6;””,””,2,2,2,””;4,4,””,””,””,2;””,3,””,4,””,””;5,5,5,5,5,2}
也就是說,第一個數組中的非零值與每個不同的值在第二個數組中第一次出現相對應,對于空字符串也是如此。
可以看到,這種情形下使用FREQUENCY函數,從而將數組簡化為每個值在該數組中出現次數的數組。公式中之所以在區域后添加0,是為了將空單元格轉換為0。
現在,將FREQUENCY函數生成的數組傳遞給IF函數,以使結果數組僅包含不同的數值:
IF(FREQUENCY(0+(Range1&0),0+(Range1&0)),IF(Range1<>””,COUNTIF(Range1,Range1)+1/(Range1*10^6)))
轉換為:
IF({3;15;0;0;3;0;0;6;0;0;0;0;0;0;5;0;0;0;3;0;0;0;0;0;0;1;0;0;0;0;0;0;0;0;0;0;0},{3.000001,FALSE,3.000001,FALSE,3.00000016666667,3.00000016666667;3.000001,6.0000002,FALSE,FALSE,FALSE,3.00000016666667;FALSE,FALSE,5.0000005,5.0000005,5.0000005,FALSE;3.00000025,3.00000025,FALSE,FALSE,FALSE,5.0000005;FALSE,1.00000033333333,FALSE,3.00000025,FALSE,FALSE;6.0000002,6.0000002,6.0000002,6.0000002,6.0000002,5.0000005})
結果是:
{3.000001,FALSE,3.000001,FALSE,3.00000016666667,3.00000016666667;3.000001,6.0000002,FALSE,FALSE,FALSE,3.00000016666667;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,1.00000033333333,FALSE,3.00000025,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;#N/A,#N/A,#N/A,#N/A,#N/A,#N/A;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;#N/A,#N/A,#N/A,#N/A,#N/A,#N/A;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;#N/A,#N/A,#N/A,#N/A,#N/A,#N/A;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;#N/A,#N/A,#N/A,#N/A,#N/A,#N/A;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE}
這并不是我們想要的含有36個元素的數組。其原因是,傳遞給IF函數的兩個數組維度不同,一個是37行1列數組,一個是6行6列的數組
因此,要執行我們想要的比較,必須首先重新將其維度調整為與另一個區域的維度相同。也就是說,這里要將37行1列數組調整為6行6列的數組。
簡單地使用INDEX函數處理由FREQUENCY函數生成的數組,使用合適大小和值的數組傳遞給其row_num參數,結果數組將是一個由6行6列組成的數組。
這里由FREQUENCY函數生成的37行1列數組:
{3;15;0;0;3;0;0;6;0;0;0;0;0;0;5;0;0;0;3;0;0;0;0;0;0;1;0;0;0;0;0;0;0;0;0;0;0}
要轉換成下面的6行6列數組:
{3,15,0,0,3,0;0,6,0,0,0,0;0,0,5,0,0,0;3,0,0,0,0,0;0,1,0,0,0,0;0,0,0,0,0,0}
這將通過將一個數組傳遞給INDEX函數的參數row_num來實現,這個作為參數值的數組為:
{1,2,3,4,5,6;7,8,9,10,11,12;13,14,15,16,17,18;19,20,21,22,23,24;25,26,27,28,29,30;31,32,33,34,35,36}
那么,如何生成這個數組呢?
有許多方法,下面是其中的一種:
COLUMNS(Range1)*Arry2-TRANSPOSE(COLUMNS(Range1)-Arry1)
其中,名稱Arry1:
=ROW(INDIRECT(“1:”&COLUMNS(Range1)))
轉換為:
{1;2;3;4;5;6}
名稱:Arry2:
=ROW(INDIRECT(“1:”&ROWS(Range1)))
轉換為:
{1;2;3;4;5;6}
將其代入上面的公式中:
COLUMNS(Range1)*{1;2;3;4;5;6}-TRANSPOSE(COLUMNS(Range1)-{1;2;3;4;5;6})
由于示例中Range1的列數為6,故公式轉換為:
6*{1;2;3;4;5;6}-TRANSPOSE(6-{1;2;3;4;5;6})
轉換為:
6*{1;2;3;4;5;6}-TRANSPOSE({5;4;3;2;1;0})
轉換為:
6*{1;2;3;4;5;6}-{5,4,3,2,1,0}
轉換為:
{6;12;18;24;30;36}-{5,4,3,2,1,0}
正交的兩個數組相減,得到:
{1,2,3,4,5,6;7,8,9,10,11,12;13,14,15,16,17,18;19,20,21,22,23,24;25,26,27,28,29,30;31,32,33,34,35,36}
這正是我們需要的。
現在,如上所述,我們將此數組作為參數row_num的值傳遞給INDEX函數。這里,確保我采用了必要的技術來強制INDEX對一組值進行操作(更多信息,請參見《Excel公式技巧03:INDEX函數,給公式提供數組》),因此:
INDEX(FREQUENCY(0+(Range1&0),0+(Range1&0)),N(IF(1,COLUMNS(Range1)*Arry2-TRANSPOSE(COLUMNS(Range1)-Arry1))))
轉換為:
INDEX({3;15;0;0;3;0;0;6;0;0;0;0;0;0;5;0;0;0;3;0;0;0;0;0;0;1;0;0;0;0;0;0;0;0;0;0;0},{1,2,3,4,5,6;7,8,9,10,11,12;13,14,15,16,17,18;19,20,21,22,23,24;25,26,27,28,29,30;31,32,33,34,35,36})
得到:
{3,15,0,0,3,0;0,6,0,0,0,0;0,0,5,0,0,0;3,0,0,0,0,0;0,1,0,0,0,0;0,0,0,0,0,0}
再回到公式的主要構造:
MIN(IF(IF(Range1<>””,COUNTIF(Range1,Range1)+1/(Range1*10^6))=LARGE(IF(INDEX(FREQUENCY(0+(Range1&0),0+(Range1&0)),N(IF(1,COLUMNS(Range1)*Arry2-TRANSPOSE(COLUMNS(Range1)-Arry1)))),IF(Range1<>””,COUNTIF(Range1,Range1)+1/(Range1*10^6))),ROWS($1:1)),Range1))
將上面生成的中間結果代入:
MIN(IF({3.000001,FALSE,3.000001,FALSE,3.00000016666667,3.00000016666667;3.000001,6.0000002,FALSE,FALSE,FALSE,3.00000016666667;FALSE,FALSE,5.0000005,5.0000005,5.0000005,FALSE;3.00000025,3.00000025,FALSE,FALSE,FALSE,5.0000005;FALSE,1.00000033333333,FALSE,3.00000025,FALSE,FALSE;6.0000002,6.0000002,6.0000002,6.0000002,6.0000002,5.0000005}=LARGE(IF({3,15,0,0,3,0;0,6,0,0,0,0;0,0,5,0,0,0;3,0,0,0,0,0;0,1,0,0,0,0;0,0,0,0,0,0},{3.000001,FALSE,3.000001,FALSE,3.00000016666667,3.00000016666667;3.000001,6.0000002,FALSE,FALSE,FALSE,3.00000016666667;FALSE,FALSE,5.0000005,5.0000005,5.0000005,FALSE;3.00000025,3.00000025,FALSE,FALSE,FALSE,5.0000005;FALSE,1.00000033333333,FALSE,3.00000025,FALSE,FALSE;6.0000002,6.0000002,6.0000002,6.0000002,6.0000002,5.0000005}),ROWS($1:1)),Range1))
轉換為:
MIN(IF({3.000001,FALSE,3.000001,FALSE,3.00000016666667,3.00000016666667;3.000001,6.0000002,FALSE,FALSE,FALSE,3.00000016666667;FALSE,FALSE,5.0000005,5.0000005,5.0000005,FALSE;3.00000025,3.00000025,FALSE,FALSE,FALSE,5.0000005;FALSE,1.00000033333333,FALSE,3.00000025,FALSE,FALSE;6.0000002,6.0000002,6.0000002,6.0000002,6.0000002,5.0000005}=LARGE({3.000001,FALSE,FALSE,FALSE,3.00000016666667,FALSE;FALSE,6.0000002,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,5.0000005,FALSE,FALSE,FALSE;3.00000025,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,1.00000033333333,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE},ROWS($1:1)),Range1))
這里ROWS($1:1)=1,轉換為:
MIN(IF({3.000001,FALSE,3.000001,FALSE,3.00000016666667,3.00000016666667;3.000001,6.0000002,FALSE,FALSE,FALSE,3.00000016666667;FALSE,FALSE,5.0000005,5.0000005,5.0000005,FALSE;3.00000025,3.00000025,FALSE,FALSE,FALSE,5.0000005;FALSE,1.00000033333333,FALSE,3.00000025,FALSE,FALSE;6.0000002,6.0000002,6.0000002,6.0000002,6.0000002,5.0000005}=6.0000002,Range1))
轉換為:
MIN(IF({FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,TRUE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;TRUE,TRUE,TRUE,TRUE,TRUE,FALSE},Range1))
代入Range1:
MIN(IF({FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,TRUE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;TRUE,TRUE,TRUE,TRUE,TRUE,FALSE},{1,0,1,0,6,6;1,5,0,0,0,6;0,0,2,2,2,0;4,4,0,0,0,2;0,3,0,4,0,0;5,5,5,5,5,2}))
轉換為:
MIN({FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,5,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;FALSE,FALSE,FALSE,FALSE,FALSE,FALSE;5,5,5,5,5,FALSE})
得到:
5
小結
這里的將單列數組轉換成二維數組的技巧讓我印象深刻,對FREQUENCY函數的使用也很好。





