
10月20日,由嘉為科技攜手騰訊藍鯨智云聯合主辦的智慧生長·研運未來暨2021年研運治理實踐大會在北京成功召開。
在20日下午進行的智能化運維分論壇上,來自中山大學陳鵬飛副教授同與會嘉賓探討了云原生大勢下,智能運維的發展背景、技術以及未來展望,共同探尋云原生時代的AIOps前沿體系,并帶來了《面向云原生系統的智能運維》的專題演講。
云原生與智能運維的背景
云原生技術近年來愈加受到IT界的廣泛關注,在權威機構Gartner發布的報告中,云原生已經位在未來十項趨勢性技術之中。云原生來自于早期的云計算平臺,而云原生與智能運維相結合也是近幾年提出的一個新理念,目前發展正處在化繭成蝶的過程。但當前云原生系統智能運維領域的實踐,還遠遠沒有達到我們所期望的狀態。
云原生技術發展
回顧云原生技術的發展軌跡,云計算從Dev+Ops時代開始,就一直朝著粒度更小的方向在發展,從裸機Bare metal、到虛擬機Virtual Machines、到容器Containers、到人工智能AI,到函數功能Function、再到未來更加細粒度的計算,云計算也在經歷著DevOps-AIOps-NoOps的時代演進。溯其根源,新技術新能力的誕生,都是為了實現開發速度越來越快,交付速度越來越快,業務響應越來越快的目標,真正提升運營的敏捷性。
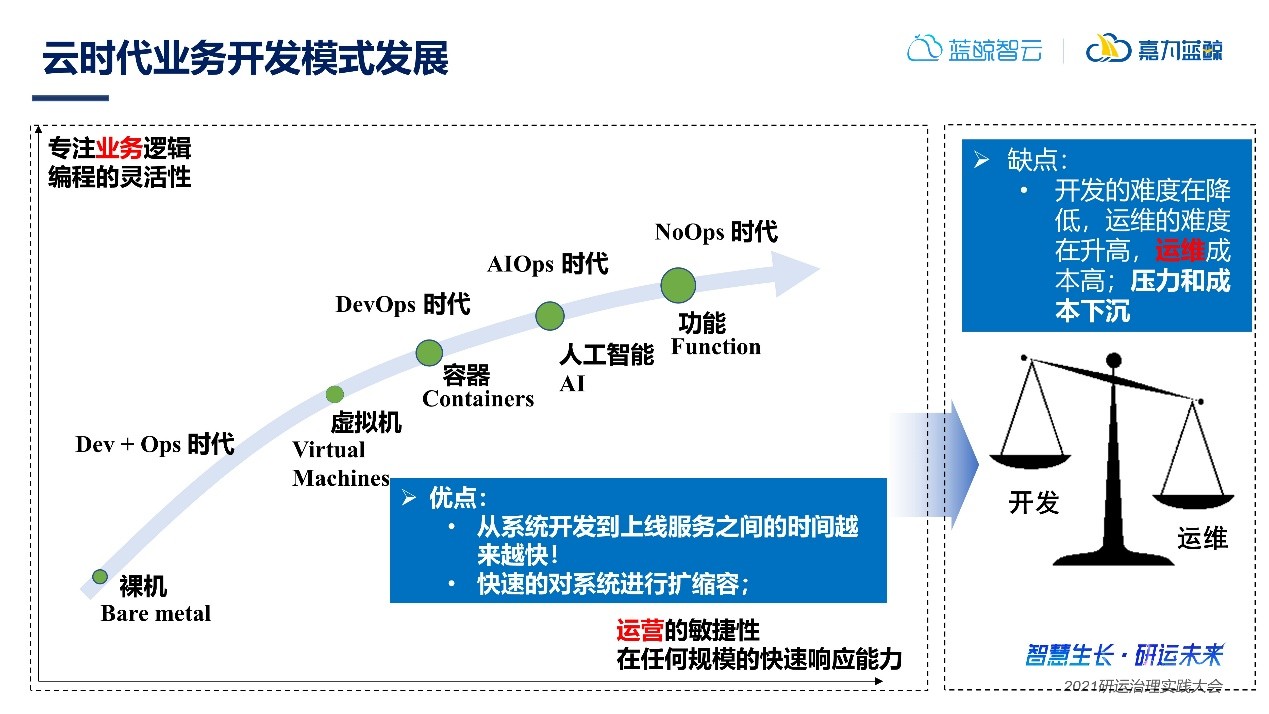
但與此同時,云計算發展帶來了一些問題:開發與運維的壓力不平衡。
運維在云原生快速發展下壓力越來越大,如何平衡運維與開發?如何在運維端加強云相關能力?如何保證二者共同發展?這是智能運維亟需解決的問題。
云原生面臨的挑戰
現階段的云原生面臨著什么挑戰呢?在此之前,我們首先了解一下云原生有什么樣的特征。在云原生系統中,存在著幾個比較關鍵的技術:
DevOps
開發運維一體化。
連續交付
主要是為了從軟件、代碼,到產品、軟件服務市場等的速度實現顯著的提升。
容器技術
加速開發和部署軟件系統的速度。
微服務
使得軟件易于開發、交互和維護。
簡言之,云原生的特征核心在于:唯快不破,唯快不贏!對效率的極致優化和追求,使得云原生系統在基于以上技術進行構建的過程中,呈現出以下顯著的應用特點:
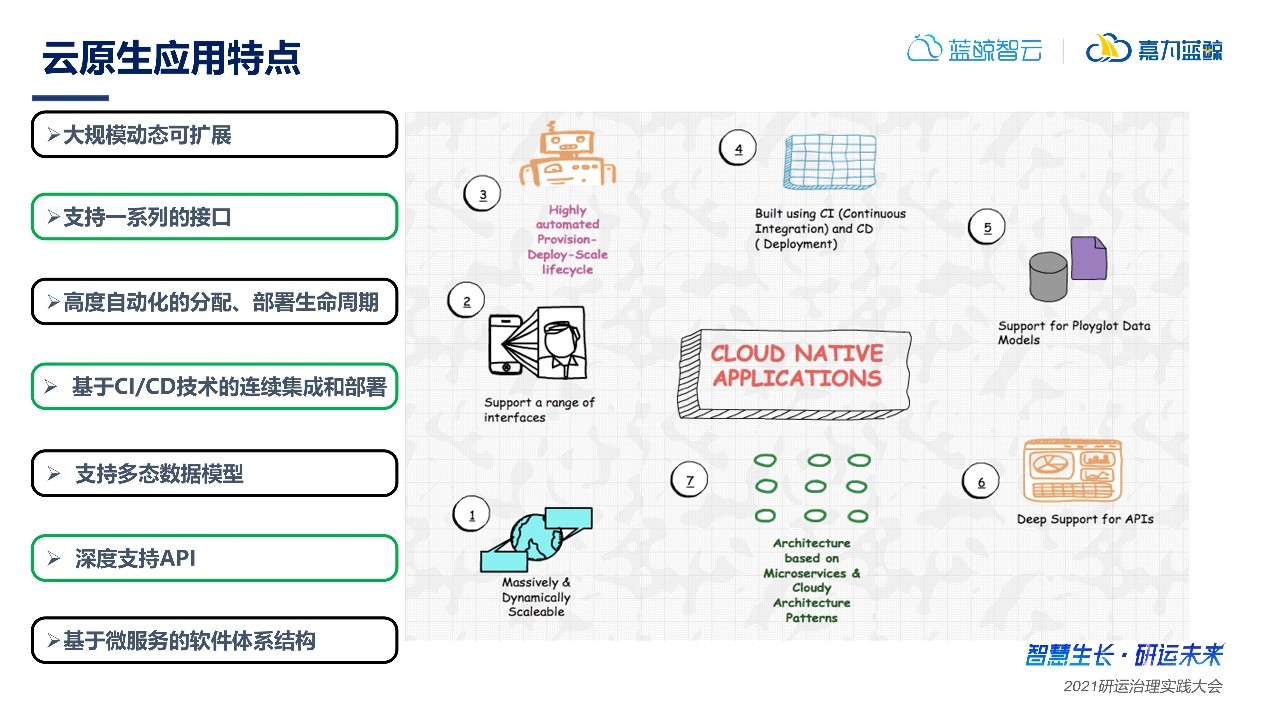
在多種應用特點下,云原生所面臨的難點:
1、系統復雜度高
舉一個例子,在某軟件中可能有3000多個微服務,但是實例的數量遠遠不止這些,如果每個微服務對應5個實例,那么將大約有15000個實例,在如此海量的實例中,如何去理清其中的相互依賴關系、精確地捕捉微服務、查看某系統運維狀態,管理各個微服務之間的關系等等,都將面臨著巨大的挑戰。同時對于一些巨型企業,微服務成千上萬,帶來的系統復雜度和運維難度也遠超想象。
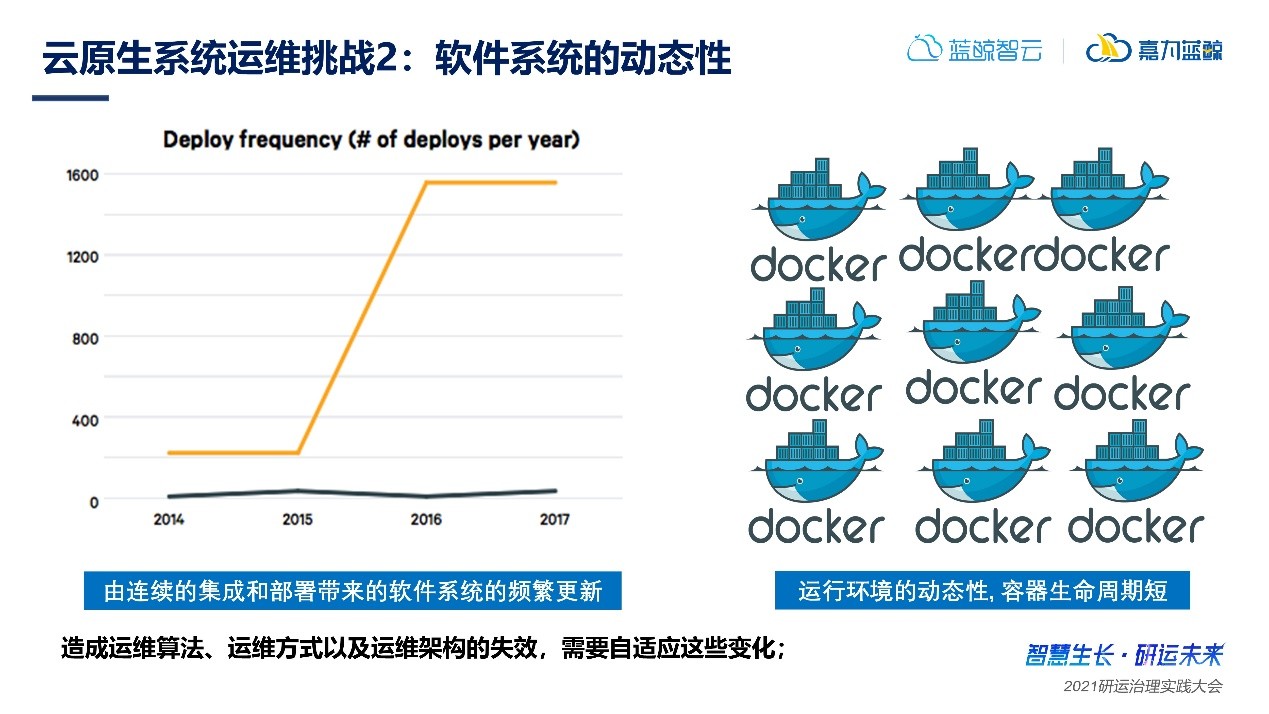
2、軟件系統的動態性
在DevOps提出以后,軟件交付的周期越來越短,與此同時,軟件逐步采用容器微服務架構,這兩種技術的結合使得系統難以找到一個穩態,這對于傳統的運維方案是一個巨大的挑戰。我們無法通過訓練一個常規的靜態模型來進行異常檢測、根因定位等工作。另外,容器本身生命周期從創建申請、擴展、銷毀等都是一個動態的過程,頻繁的動態變化使得智能運維難度急劇加大。
3、軟件多樣的增加
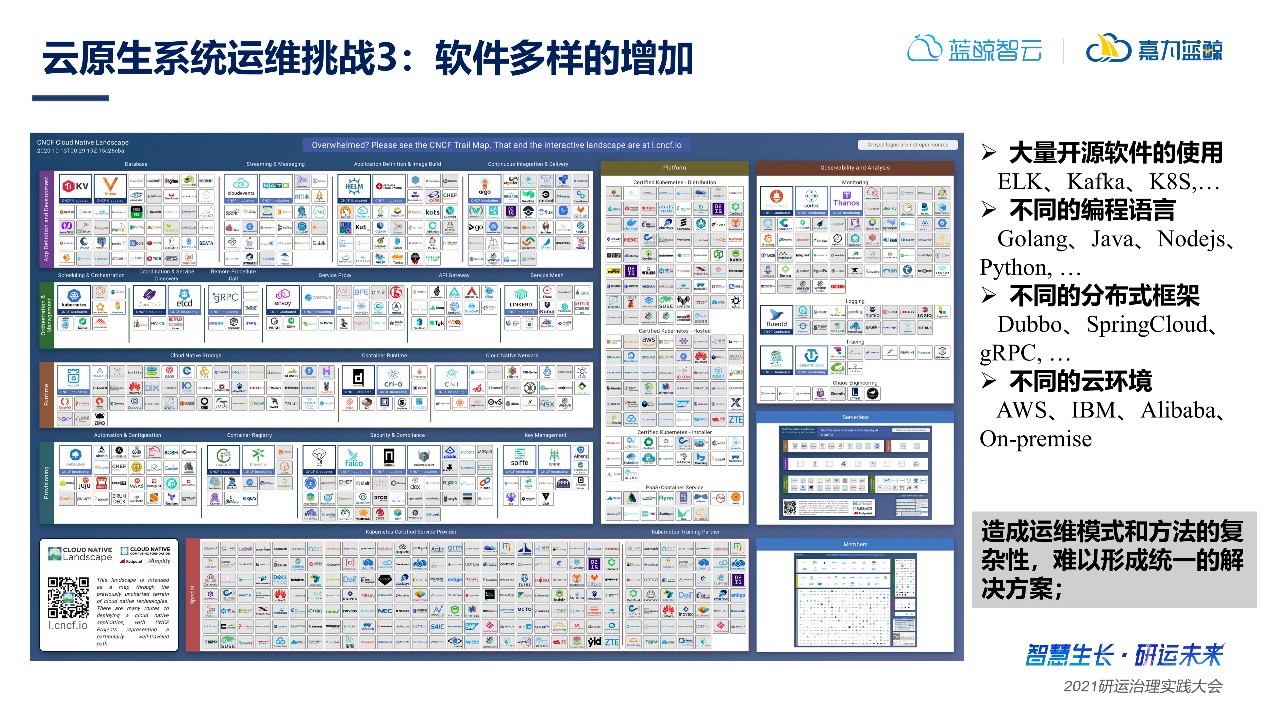
如上圖,在云原生知名社區CNCF上,開源軟件的數量是十分龐大的,面對如此海量多類型的軟件,運維又該如何統籌管理,如何精確捕捉其性能和狀態呢?軟件多樣性增加環境下,運維模式和方式的復雜度呈指數級增加,難以形成統一解決方案。
4、軟件故障的增加
系統規模小的時候,可能只有幾十臺服務器,由此帶來的故障依舊人為可控,但隨著系統規模的不斷擴大,故障發生的概率也在并不斷的增加,造成的影響也逐漸難以控制。在此之前,我們也能在各種場景中見到各種類型的宕機、各種類型的故障,某社交巨頭企業曾經發生過罕見的長達6小時的故障的宕機時間,這對于業務系統的影響幾乎是毀滅性的。因為這6小時的故障宕機,該企業可能丟失了幾十億美金。
5、運維數據復雜
與軟件規模擴大同步帶來的問題,就是數據的復雜度,實際上運維數據的種類恰好符合大數據的定義標準:種類多、體量大、速度快。如何從多種類的運維數據中發現問題,快速的解決問題,讓運維工作變得更加棘手。
解決思路
新技術必然帶來新的困難,為了克服這些難題,又會衍生出相應的技術手段。早期在面臨故障時,我們考慮的是如何減少平均失效時間MTTF,再降低MTBF、MTMF平均失效間隔時間,這也是智能運維的基礎解決思路。在應對云原生系統時,AIOps作為算法驅動的運維,就成為了解決這類問題的高級手段。
AIOps可以從算法、數據、場景三個維度去分析處理,通過數據驅動運維,最終實現從數據中發現信息,從信息中挖掘知識,形成解決問題的知識庫,最終實現數據融合分析,也即是AIOps的發展路徑。
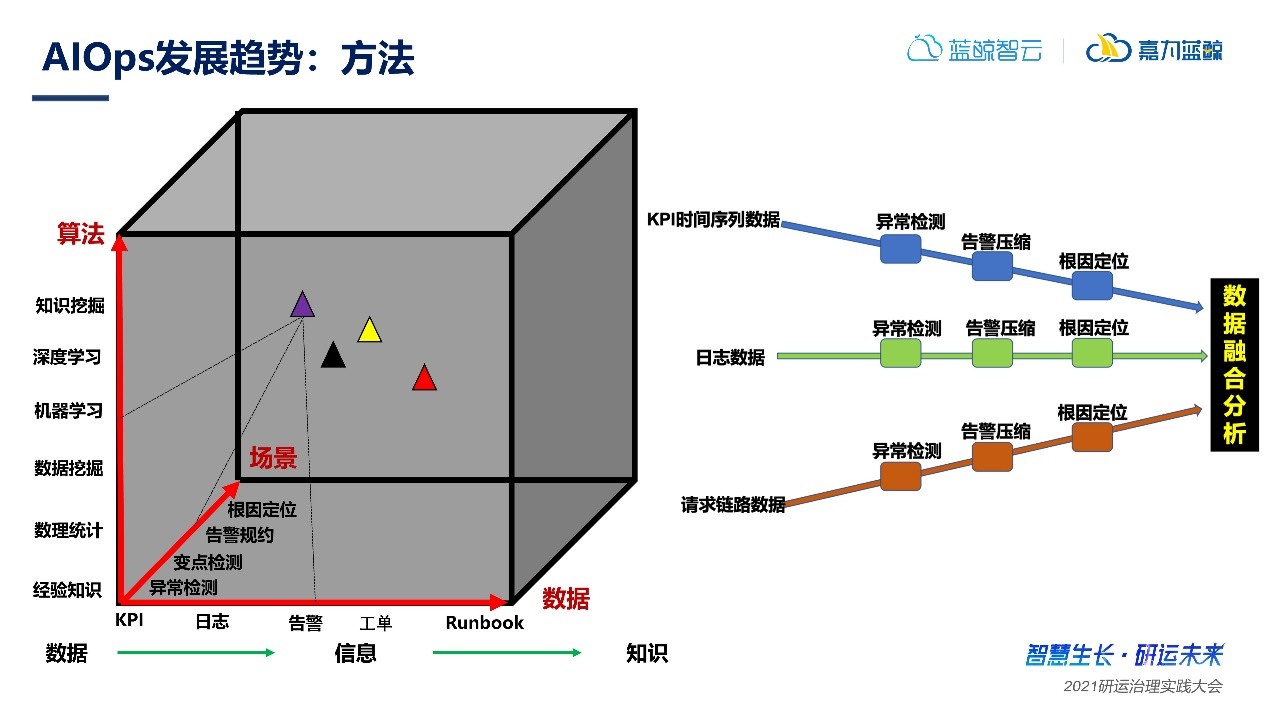
面向云原生系統的智能運維技術
1、可觀測性
可觀測性通常在企業運維中也叫做監控。也是智能運維的首要目標,對現有的資源,實現統一的監管、控制,并且能夠根據實時變更進行動態響應。但傳統的運維缺少了廣度、寬度上的監控,我們希望能夠更深層次的觀測,包括系統真實狀態活動,數據源之間的關聯,多數據的統一接入等等。
在此方面,基于eBPF的性能監控以及全鏈路的上下文監控通過多種新技術手段的融合,能夠匯聚更細粒度的監控數據,同時形成指標,便于其他運維工作的快速開展。
2、異常檢測
在異常檢測方面,目前很多場景都有各種各樣的方法,可能有成千上萬種方法,本文僅根據個人總結,對異常檢測方法進行分類,如:通過數據是否具有數據標簽,選擇有監督、無監督或半監督的方式進行處理。同樣的,在數據類型、數據維度、數據模式上,也可以進行相應的處理,從而選擇更為合適的方法進行處理。
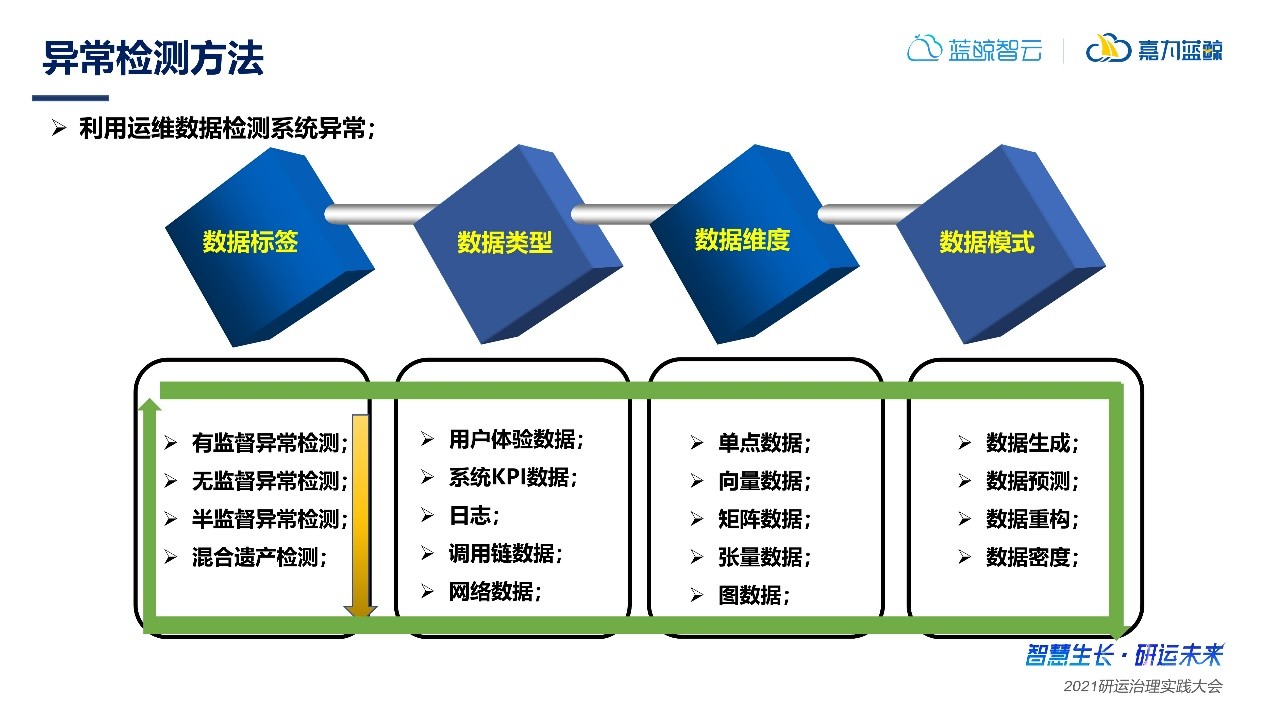
3、根因定位
作為AIOps的核心工作難點,根因定位在運維工作中是最為常見的場景,但也是最耗時,最復雜的一個階段,如何追蹤微服務的請求信息,如何合理利用trace提供有價值的信息,如何根據分析數據、圖譜找到故障真正的源頭,這也是我們正在努力研究的一個方向。目前我們已經在基于調用鏈、因果關系、云原生知識圖譜的根因定位中獲得了顯著的成效。
未來技術展望
以上的各類研究方法或處理手段,依然還有很大的優化和進步空間。關于可觀測性,基于eBPF的細粒度行為監控,我們可以減少一些可以直接觀測到的過程,例如文件的讀寫、網絡狀態等,不需要基于算法去處理,對監控進行更進一步的優化。
在全鏈路上下文關聯方面,已經有一些走在前列企業實在實踐了,但并不夠完善,例如Metric這類指標并沒有做細粒度的關聯,數據分析上,僅僅提供了可視化么能力,缺少關聯數據的分析。
最后是基于交互式、主動式的智能運維,學術界與企業界都在進行不斷地探索著智能運維算法未來的發展。許多團隊都在這方面進行著大量的投入,同時我們也能看到智能運維也在隨著底層架構的調整而不斷的發展和調整。谷歌最早提出的SRE的理念如今也在不斷的被各類“后起之秀”實踐并改進著。
面向云原生系統的智能運維過程,我們可以總結為:在運維的數據中找到知識,在這一過程中,如何獲取數據,如何分析處理數據,如何總結出可用的知識經驗,例如故障種類,發生時間,規律,修復方式,解決過程等,如何沉淀統一知識庫、形成解決方案等等,實際上就是我們通常在寫的Postmortem,也是智能運維發展中正在不斷探索內容,如何推進Postmortem的文化,在未來也將會有一席之地!





