
ECUG(Effective Cloud User Group,實效云計算用戶組)主辦的 2021 ECUG Con 今日在上海舉辦,會上,七牛云 CEO 許式偉以“ Go+ 與數據科學”為主題發表了主題分享,講述了對數據科學變遷的理解,對新語言 Go+ 的設想和規劃,并大膽指出數據科學正迎來爆發期,像字節跳動一樣的新型公司只會越來越多。以下為演講內容整理,Enjoy~
剛才在閑聊說 ECUG 變得越來越高大上,其實我也變得越來越像一個單純的講師。今年是 ECUG 社區的第 14 個年頭,這場活動也是第 14 屆 ECUG Con。其實這一屆本來應該在去年辦,但因為疫情延后了。
其實,我在 ECUG 一直貫徹的理念有兩個:
第一,讓自己持續地寫代碼。因為每一次來 ECUG 我都很緊張,不能什么都沒有呀。所以這也是挺好的機會,能讓自己持續留在技術一線;
另外,我每年分享的主題都有一定的延續性,呈現了我自己對未來思考的脈絡。
去年開始,我在聊數據科學,前面有三年是聊在端上的一些實踐。原因是我認為云計算的第一個時代應該是屬于機器計算,也就是虛擬機;第二代就是云原生,我認為這是一場被稱為“基礎架構”的革命。也就是說,第一階段是資源,第二階段是基礎架構。 第三個階段,我的判斷為應用計算,這會涉及前端和后端的協同。
從去年開始,我的分享轉向了數據科學,一個很重要的因素和趨勢是,數據時代的到來。尤其是 2017 年之后,數據大量地被數字化以后,在各行各業都會有涉及數據科學的廣泛應用。
去年也是蠻巧的,我腦子一熱就搞了一個語言出來。我以前搞過蠻多語言,受眾也有一些。但是那個都很明確,從來沒有想過有一天能夠商業化。也許碰巧有一些公司用它來做商業化,但是基本上從出生那一刻開始,就不是沖著商業化去的。
2012 年我花了很多精力在布道 Go,因為當時作為一個初創公司,招人太難。一個比較好的招人邏輯就是讓別人覺得你有趣,公司技術氛圍很不錯。Go+ 是我第一個認認真真希望能夠把它商業化的語言,但目前宣傳得還不多,1.0 還沒發布。我想講講我自己對 Go+ 和數據科學的一個思考,為什么認為 Go+ 有商業化的機會。
我今天聊的話題大概有四個方面:
語言的發展
數據科學的發展
Go+ 的設計理念
Go+ 實現的迭代
語言的發展
首先,我們講講語言的發展,程序員對這個話題非常感興趣。我把語言的發展史分為三個部分來說。
第一,靜態語言的發展史。我選的是 TOP20 的語言,這個是根據現在最火的語言排行榜排名選的,前 20 名的語言我排了一下大概是這樣的,最早發布的是 C,到現在其實還在排行榜前三的位置。第二是 C++,Objective-C、Java、C#、Go、Swift、Go+。我們可以看到一個比較有趣的現象,差不多每 6-8 年會出現一輪新的、具備影響力的靜態語言,這是生產力迭代的表征。

第二,腳本語言的發展。你會發現它們非常不一樣。最早是 Visual Basic,然后是 Python、PHP、JavaScript、Ruby,腳本語言是集中大爆發的,差不多全在 Java 出現的前后,來自 90 年代的前 5 個年頭。這是非常有趣的一件事情,也是非常值得思考的,背后一定有一些內在的原因。

第三,數據科學相關語言的發展。但數據科學我選的是 TOP50,因為 TOP20 實在太少了。也蠻有意思的,最早的是 SQL,第二個 SAS,MATLAB、Python、R、Julia。Python 最早從來沒想過自己會是數據科學語言,但最終變成了人工智能領域最火的語言。

這里又存在一個很明顯的特征:它的跨度跟靜態語言一樣大,所以數據科學發展其實是古老而漫長的,但發展得沒有那么快。靜態語言差不多每 6-8 年有一個迭代,但數據科學語言不是,中間跨度特別大。但我覺得現在正進入數據科學的加速期。
你可能會想,為什么我要分析語言發展史呢?有幾個結論是關鍵。
首先,我認為腳本語言是特定歷史階段下的產物,長期來看,靜態語言更有生命力。
第二,數據科學是計算機的最初需求,最早計算機就是用來做計算的。它歷史悠久但進步緩慢,因為數據大爆發的時代一直沒有到來。

數據科學的發展
聊完語言的發展,接下來我們談談數據科學的發展。數據科學也可以分為幾個階段,第一個階段我叫做“原始時期”,也可以叫“數學軟件時代”,這個時期基本上可歸納為兩個特征,第一個是在有限領域里,最典型的是 BI(商業智能);第二個有限數據規模,典型就像 Excel,行列數都是非常有限的,其他的軟件也基本上是這樣的。
這個時期的數據科學特點是什么?首先它不是一個基礎設施,實際上是數學應用軟件,但能力非常全,很強大,包括了統計、預測、洞察、規劃、決策等等。

第二個時期我叫做“數據科學的基建時期”,真正讓數據科學成為了基礎設施,最典型的代表是大數據的興起。Map/Reduce 是 Google 2004 年發布的一篇論文,2006 年就出現了 Hadoop,2009 年出現了 Spark。我認為這算是大數據興起的一個階段,也是數據科學基礎設施化的開始。這個時期跟剛才的數學軟件不一樣,是以大規模處理能力為先,并不是以功能強大為先,它的功能相對局限。

深度學習的興起和大數據的興起間隔時間比較長,深度學習 2015 年開始有 TensorFlow,2017 年開始有 Torch,這是兩個知名度最高的深度學習框架,深度學習本質就是通過數據自動推導 y=F(x)中的 F 函數。我們平常通常都是程序員實現這個 F,但深度學習最核心的概念是如何讓機器自動產生這個 F,來達成最佳曲線擬合。它其實是基于測量結果的自動計算。

假設今天沒有牛頓三大定理,但我有一堆測量數據,理論上應該能夠發現牛頓三大定理,這就是深度學習的核心邏輯。它跟大數據并不是相互取代的關系,而是一種能力的加強,更多其實是如何讓大數據的能力更進一步,更強悍。
有種看法認為,今天經濟發展背后科技的驅動因子其實核心就只有兩個,一個是計算,另外一個是數據。
數據核心就是我們今天聊的數據科學,數據科學其實是到了一個新的范式,有一個詞叫“第四范式”,中國有一個公司也叫第四范式,我們認為數據是更高階的一種生產能力,它跟計算相比的話站在更高層次的維度。
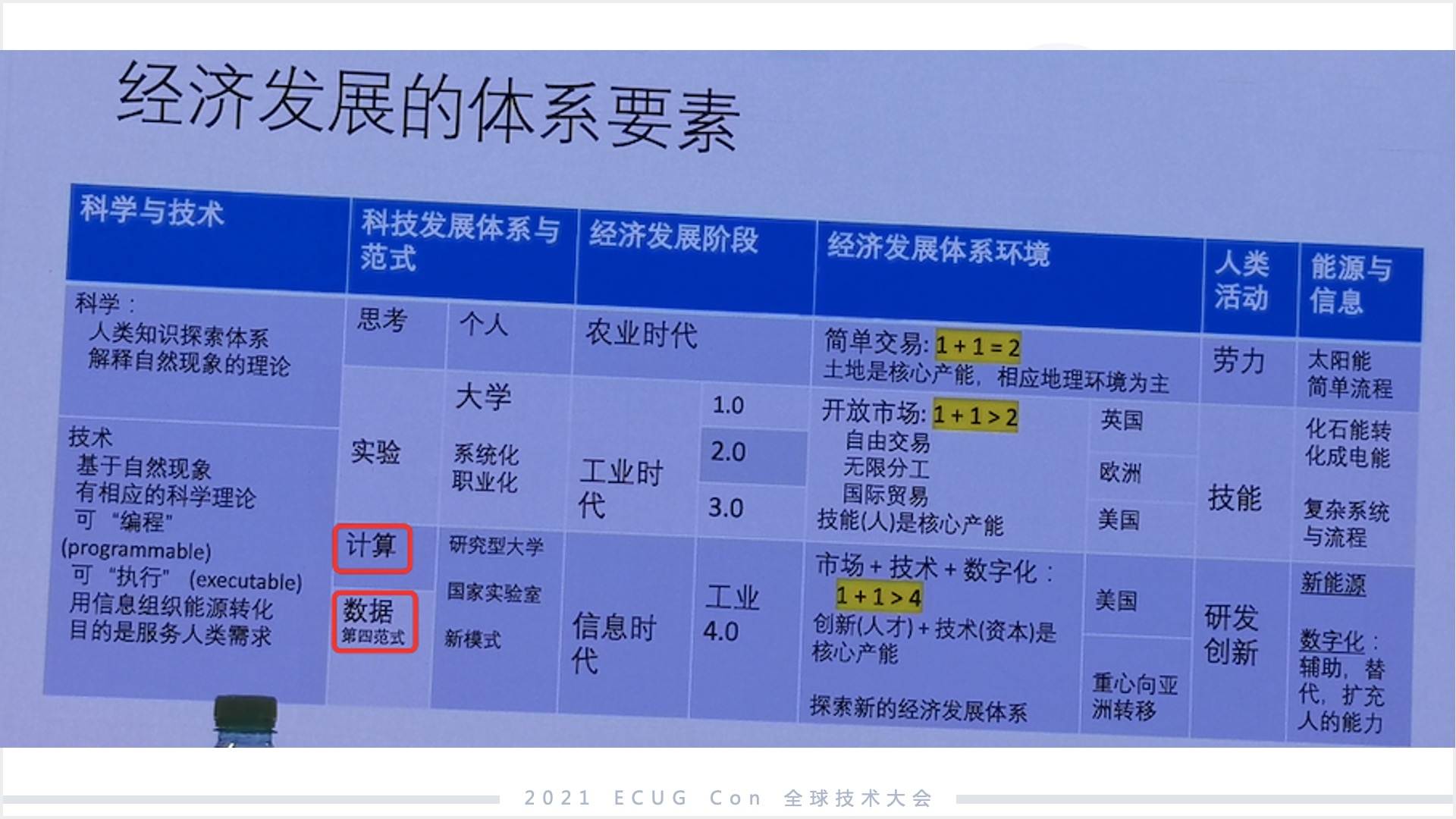
前面是數據科學的兩個階段,那么第三個階段是什么?我覺得是數據科學的大爆發時期,也就是今天,用馬云的話說是“DT 時代”。原始時期是在有限的領域,有限的數據規模下去做的一種能力。未來首先是全領域的,首先領域不局限于的商業智能( BI )這樣的范疇,第二個是大規模的數據,第三個是隨處可見,隨處可見包括云、智能手機、嵌入式設備等,這些都會植入我們所謂的數據智能。

這就意味著,今天移動互聯網的興起已經讓很多公司非常牛,互聯網的平民化或互聯網應用的誕生,催生了 BAT。但是我們知道,現在新興的、比較牛的公司,像字節跳動這種,其實不是互聯網的成功,而是數據科學的成功。今天仍然不能說,數據科學是平民化的,它的門檻非常高。
但是我們看到,智能應用已經產生了,智能應用不會只局限于抖音這樣一個局部領域的生產力放大,各行各業都會被數據智能,也就是剛剛我們提到的第四范式所影響。
數據和數據科學,一定會成為下一代生產力的支撐,今天產生了字節跳動、快手這樣的新興的公司,但他們只是一個開始,絕對不是結局。
在數據科學的原始時期,數據只是副產品。大家想象一下,在 BI 領域,數據只是一個副產品,只是用于后期的運營決策。
但是今天我們看到在大量的應用里,數據就是原材料。這是非常不一樣的狀態,這也是為什么,我把它叫做數據科學大爆發時期,這是我覺得今天為什么需要 Go+ 的原因,也是其背后的歷史背景。

數據科學的未來一定是通用語言和數學軟件的融合,從而完成真正意義上的數據科學的基礎設施化。但在今天,數據科學的基礎設施化還遠沒有完全完成,這是我自己的判斷。

今天的 Python 已經很好了,為何需要 Go+?
當然很多人會有疑問:今天的 Python 已經很好了,在深度學習領域已經被非常廣泛地使用,為什么 Python 還不夠,需要 Go+?其實我是認為,Python 是成不了基礎設施的,它是一個腳本語言,我認為僅僅是特定歷史階段的需要。
數據科學本身是一種算力革命,哪怕在芯片領域,數據也能干翻計算,這是 Nvidia 干翻 Intel 的核心原因。上層軟件領域就更加如此,一定會有一個新的基礎設施承載者需要出現。
算力本質上是一種計算密集型業務,Python 的背后是 C,只靠 Python 還是不行。今天是 C 和 Python 支撐了整個深度學習,但數據科學一定還要進一步下沉,下沉的結果是什么?

這是我們今天需要 Go+ 的原因!前面主要講我自己為什么認為 Go+有商業化的機會。當然我所說的商業化不一定是賺錢,大家不要誤會這一點,語言可能在大多數人心目中是一個不賺錢的東西,但是這不代表它不重要,它非常重要。
Go+ 的設計理念
聊完數據科學的發展,接下來我們聊聊 Go+ 的設計理念。Go+為什么是今天這個樣子?計算背后要的是程序員,而數據科學背后要的是數據科學家或者叫分析師。這兩個角色其實還是不一樣的,雖然都是技術工作。我認為培養程序員是相對容易的,今天程序員的數量是非常龐大的,但數據科學家的數量相對較少,這也是為什么前幾年深度學習興起以后,所謂的 AI 工程師薪資被炒翻了,比程序員貴很多。其實就是因為數據科學家不容易找。
這個角色承載著技術和商業的連接,要找到同時具備兩種能力的人是很難的。數據科學首先是一個技術工作,要的是技術能力,又要懂商業。今天仍然沒有非常體系化的培養數據科學家的能力,沒有這樣一個體系方法論。
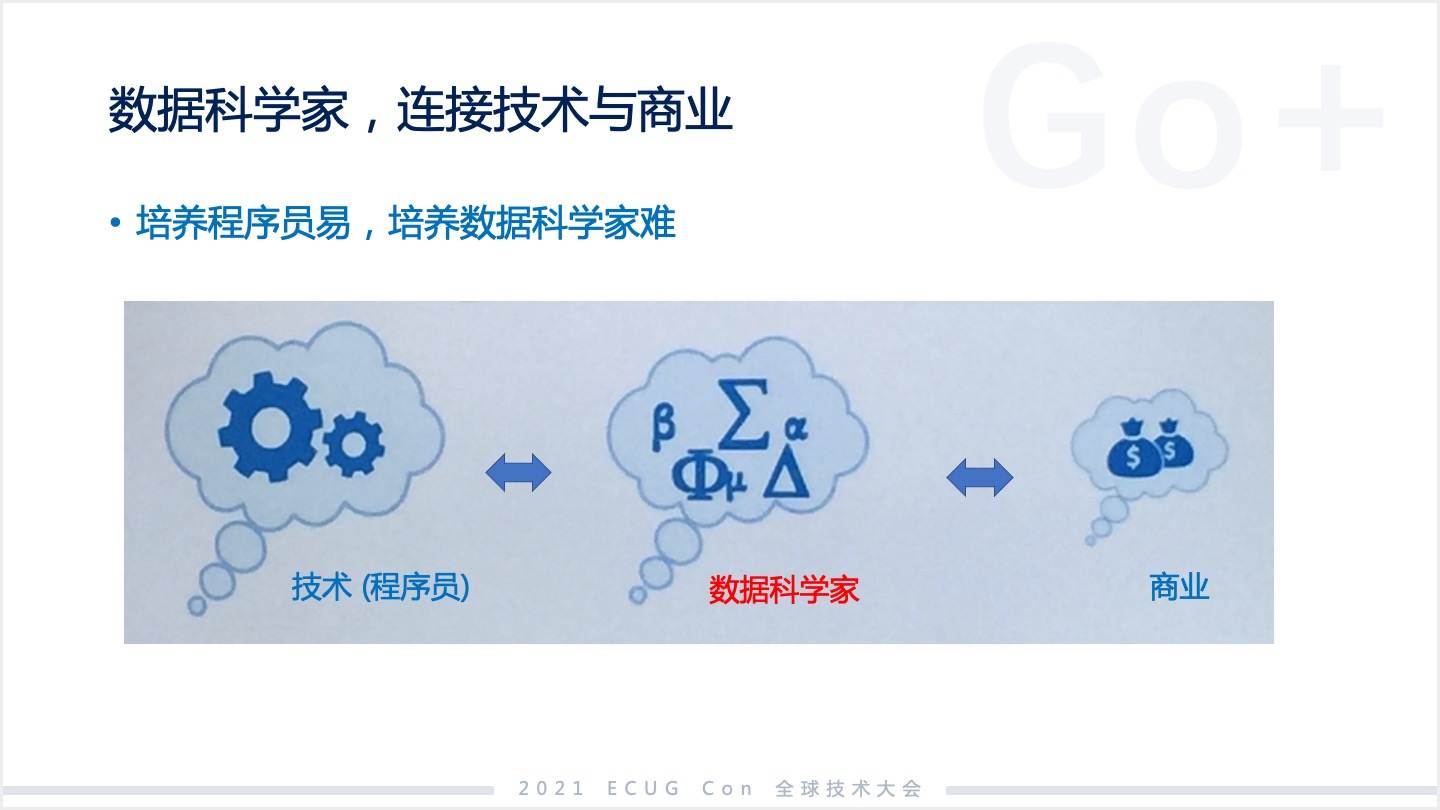
那么 Go+ 的核心理念又是什么呢?
第一個,我們試圖用 Go+ 來統一程序員和數據科學家,讓他們之間有共同話語,讓雙方能自然對話,我覺得這是 Go+ 最核心的一個思考點。Go+ 很重要的一個核心邏輯,是用一門語言讓兩個角色進行對話。

在這個基礎上,我們延伸了一些設計邏輯。首先,Go+ 是一個靜態語言,語法是完全兼容 Go 的;第二,形式上要比 Go 更像腳本,有更低的學習門檻。Go 雖然在靜態語言里,可能學習門檻是低的,但還不夠低,沒有 Python 那么低;第三,很自然的,我們要做一個數據科學的語言,所以它必然要有更簡潔的、數學運算上的語言文法支持;第四是雙引擎,同時支持靜態編譯為可執行文件,也支持編譯成字節碼來解釋執行。

為什么我們會選擇語法完全兼容 Go 呢?首先我個人很堅定地認為,靜態語言擁有更強的生命力,更能跨越歷史的周期。大家也都很容易理解,語言是需要跨越周期的,語言的生命周期通常都非常長。我們不能很局限地說,當前在流行些什么東西,我就如何決定語言的設計,實際上我們要找到那些能夠跨越周期的元素。

第二,為什么是 Go?我個人認為,在靜態語言里,Go 的語法設計最為精簡,學習門檻也是最低的,哪怕你以前沒有學過靜態語言,也很容易學會 Go。我們公司是最早招聘 Go 程序員的,但大部分招進來的人都不會 Go。我們用 Go 的時候,世界上真沒多少人認為 Go 是未來的流行語言。我們自己實踐的經驗表明,Go 語言兩周的學習基本上夠了,是門檻非常低的一門靜態語言。
但從數據科學語言來講,Go 的門檻還不夠低,Go+ 雖然完全兼容 Go,但我們希望它比 Go 的門檻還要有更低。所以它形式上要比 Go 更像腳本,因為腳本往往更容易理解。我們希望 Go+ 學習門檻和 Python 處于同一個層次。
去年 5、6 月份 Go+ 剛誕生,差不多 10 月份左右,我就開始讓 13-14 歲,六年級到初一這個階段的三個小孩嘗試學習 Go+。這個實踐證明,這個事情是可行的。他們能理解 Go+的設計,能夠自如地使用 Go+ 寫代碼。這也證明了我們在 Go 的基礎上做的所有簡化的努力是非常劃算的。

我這里簡單列了一些 Go+ 的語法,當然不是全部,只是一些我認為還是相對比較簡潔的表達。有理數 Python 里面沒有,我們認為有理數在數據科學里,尤其在無損數值運算里,還是會非常常見。Go+ 內置了有理數的支持。當然 Map、Slice 基本上 Python 都有。
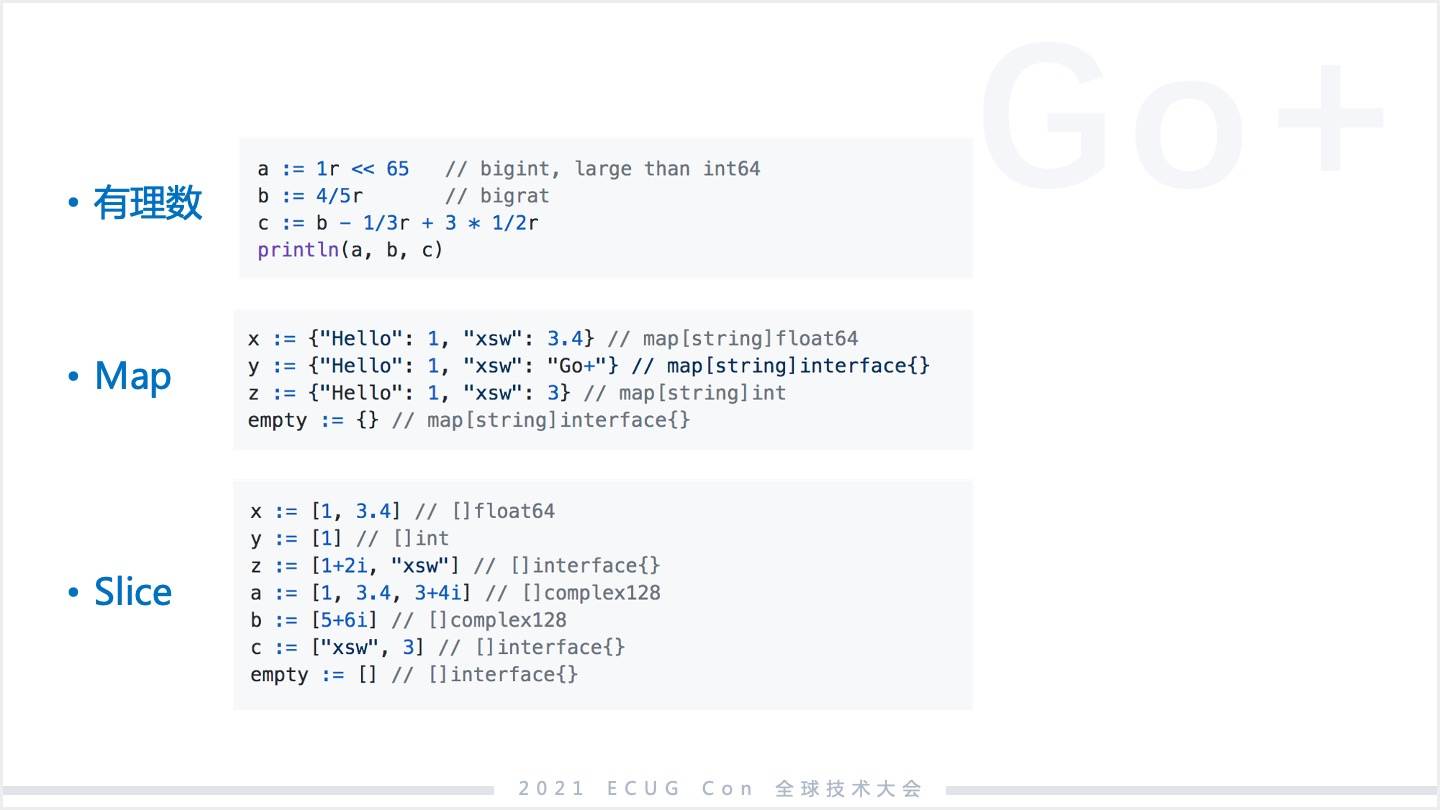
列表理解(List comprehesion)其實也是 Python 有的,但我們對列表理解的支持非常的完整,基本上理解了 Go+ 中 for 循環怎么寫也就理解了列表理解。更多的還是數據科學的一些常規操作的簡潔表達。以上是一個大概語法示意,如果有朋友沒看過 Go+,希望可以大概對 Go+ 有個理解。

Go+ 非常有意思的一點,它是唯一一個選擇了雙引擎的語言,既支持靜態編譯,也支持可解析執行。
為什么要做雙引擎呢?因為我認為程序員和數據科學家的訴求是不一樣的,數據科學家喜歡單步執行,大家可以在心中回想一下你見過的數學軟件,包括 SAS、MATLAB,數學軟件交互都是單步執行的方式。
這并不是因為數據科學家懶。程序員理解程序邏輯是可以放在腦子里的,我們腦子里知道程序邏輯寫得對不對。但數據科學家做計算的時候,不能知道計算結果對不對,因為人的計算能力比計算機弱太多了,所以一定要單步執行看到計算結果,才能知道自己下一步應該怎么辦,這是數據科學家和程序員工作模式完全不同的一個點。
因為他是在做計算而不是在做一種程序邏輯,所以他很難不去做單步執行。
但當數據科學家建了一種模型,最終要使用了,這時他仍然希望最終交付的是最大化的執行效率,他一定不希望代碼運行很慢,所以這個時候他就又需要靜態編譯執行,這也是為什么 Go+ 希望設計成雙引擎,因為調試階段和生產使用階段,工作模式完全不一樣。

Go+ 實現上的迭代
聊完 Go+ 的設計理念,我們進入最后一個 session,Go+ 實現上的迭代。當前 Go+ 做到了什么份上?Go+ 雖然還沒有推出 1.0 版本,但是語法目前支持百分之六七十肯定有了,語法完成度還是不錯的。
Go+ 的源代碼,通過掃描器轉成一個 Go+ 的 Token,再通過一個 parser 變成 Go+ 的抽象的語法數,常見語言都是這么干的。Go+ 的抽象語法樹轉化后有兩個分支,一個生成 Go 的代碼從而使其可以靜態編譯,另外一個分支生成字節碼解析執行,分支的多態是通過引入了一個叫執行規范(exec.spec)的東西,其實就是一個抽象的接口。
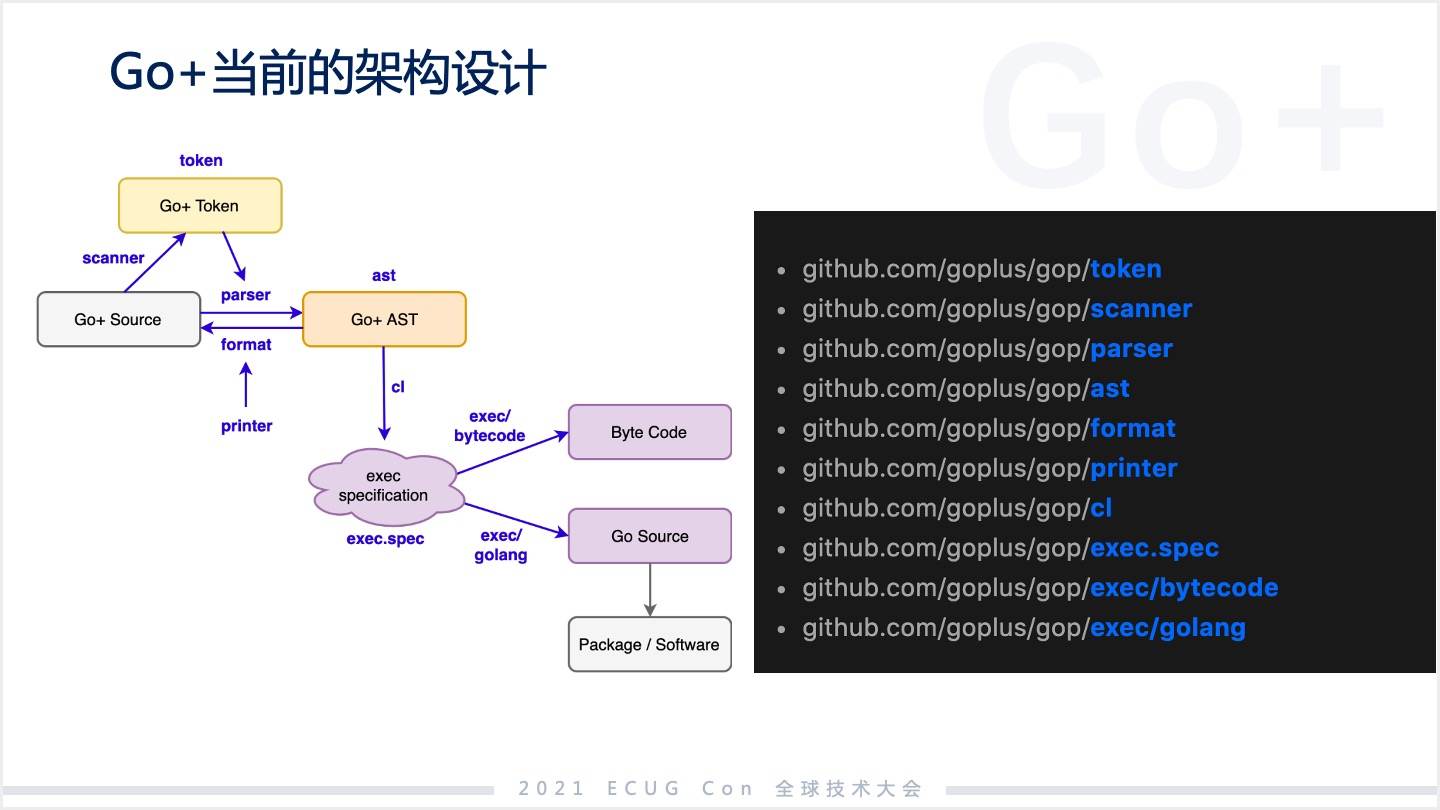
當前,我個人在迭代的過程中發現了一個問題,對一個初步加入 Go+ 團隊的人來說,是需要一段時間熟悉整個業務的。Go+ 執行規范的部分,其實是一種抽象的 SAX 接口,也就是基于事件驅動,我有一個事件發送給接受方,接受方按自己的需要處理這個事件,這在文本處理里面比較常見。
我們之前設計的接口基本上是用事件驅動的模式來把不同組件連接起來。編譯器把抽象語法數解析完發出一些事件,這些事件被兩個代碼生成的模塊接收,按照自己的需求去干活。這個模式代碼還是有點難理解,尤其是編譯器里面又做一些復雜的事情,讓代碼比較難理解。大家如果了解過 Go 背后的實現邏輯,類型推導在 Go 里面比較復雜,其實我們編譯器的復雜性大部分是由類型推導導致的。
我當前在試圖重構這個邏輯,想把執行規范部分變得不再是一個抽象的接口,而是一個標準實現的 DOM,這個 DOM 本身包含了類型推導的能力,從而使得編譯器相對比較簡單。講實現我今天沒法講的特別細,后面有機會再展開。

下面我想講一下 Go+ 下一步做的重心是什么。
首先,最核心的邏輯,還是希望今年能夠發布 1.0 版本,而 1.0 版本最重要的事情是把用戶的使用范式做最大化的確認,1.0 以后我希望和 Go 差不多,后面的語法變更是比較少的。當前最重要的工作,是明確 Go+ 需要哪些最核心的語法,并且在 1.0 版本就盡量去支持,除非有一些特定的考量比如說像 Go 的范型這種特別復雜的語法特性,留到后續的版本去支持。Go+ 也是類似的,我們可能會放棄一些特別復雜的語法特性,但是基本上盡可能把大部分我們需要的語法特性在 1.0 版本里確定下來。
Go+ 1.0 我們會先進行單引擎的迭代,先做好靜態編譯的引擎,等 1.0 發布以后再迭代腳本的引擎。這也是基于上面我們說的用戶的使用范式優先的理念下的一個決策。

最后,我們希望用商業化的方式來運作 Go+,也會招聘 Go+ 的團隊成員,歡迎大家加入 Go+ 團隊!
我認為 Go+的核心是首先統一了程序員和數據科學家的語言,讓雙方能夠自然對話。另外我非常堅定地相信 Go+ 會是數據科學的下一個變革,我自己非常興奮能夠做這樣一件事情,也非常歡迎認可這件事的人加入我們。






