
近年來,新一代硬件產品不斷蓬勃發展,如多核CPU、GPU、FPGA,以及XPU,如TPU(Tensor Processing Unit,張量處理單元)等。以TPU為例,它可以在硬件層面上處理人工智能和機器學習經常涉及的張量數據結構和張量相關的計算,這大大提高了數據處理和計算的效率。
此外,新一代硬件的革新也在推動數據庫系統和架構發生變化,數據庫系統作為硬件和企業需求之間的紐帶,需要通過巧妙精細的架構把硬件的能力和特性充分發揮出來,更好地滿足企業存儲和分析數據的需求。

因此,在新一代硬件的基礎上,柏睿數據從數據庫系統層面優化,囊括新一代計算平臺和引擎,如內存計算、分布式計算、人工智能和機器學習計算、流計算等,構建業界領先的數據智能分析處理平臺——RapidsDB,以完全自研的分布式全內存數據庫、實時流數據庫、數據庫人工智能、跨源異構查詢連接器、數據庫安全&加速卡等為核心,針對海量、高吞吐、高并發、多源異構數據進行實時分析處理,充分利用和發揮新一代硬件的性能,落地數據治理、數據模型分析、數據資產管理、數據追溯等場景應用,攜手政府部門和千行百業的企業開展數智化轉型。

柏睿數據是如何將內存計算和分布式計算珠聯璧合,構建出一個更快、更簡單、性價比更高的數據智能分析處理平臺?柏睿數據聯合創始人、全球副總裁、首席技術官馬珺表示,柏睿數據專家團隊擁有國際領先的智能數據算力技術,完成了從解析層、優化層、執行層到存儲層等全面自主可控的數據庫產品體系。柏睿數據完全自主研發的數據智能分析處理平臺RapidsDB,從內存計算出發,革新存儲介質;通過分布式計算,對架構進行橫向擴展,為數據平臺帶來數據存儲與數據處理方面的革新。
內存VS磁盤,從儲存到計算、實時分析的巔峰對決
柏睿數據RapidsDB是基于分布式架構的內存數據庫。相較于傳統數據庫用磁盤存儲數據,內存數據庫直接在內存上進行數據存儲和計算。
一、內存數據庫避開了數據訪問時磁盤的I/O瓶頸,存取速度更快。將內存與磁盤的訪問速度對比可知,內存訪問速度是納秒級,而磁盤訪問速度是毫秒級,數據處理速度差異高達百萬倍。
二、內存數據庫能夠用壓縮和優化的格式來存儲數據,從而更好地發揮CPU、GPU等現代硬件,而傳統的磁盤數據存儲則無法實現。
三、內存數據庫中從內存訪問數據所使用的內存更少。這是因為從磁盤上讀取數據時會涉及諸多復雜操作和過程,而從內存訪問數據的過程指令集較少,所使用的內存也較少。
四、除了性能優勢外,內存數據庫還在一些有趣的領域具有磁盤存儲和索引難以實現的優勢。例如,列式存儲和行式存儲,內存數據庫能夠很容易地在兩者之間靈活切換,且可以很容易地實現分層數據模型,甚至矩陣張量數據模型。而對于基于磁盤的存儲來說,實現這樣復雜的模型是難以想象的。
正因如此,柏睿數據RapidsDB選擇基于內存存儲架構進行設計和優化,具有無磁盤IO、高可擴展、高吞吐、高并發、低時延、節省內存等特性,比傳統數據庫性能提高近百倍,分布式架構支持按需動態在線擴展,支持日增20TB數據量實時采集與分析,滿足100TB全內存數據量分析500/秒并發,TB級數據毫秒級響,且數據與內存空間的占用比例少于1:2,相較于傳統數據庫節省內存采購成本60%以上,充分滿足企業對海量高并發大數據進行快速、精準智能分析和決策支持的需求。

相較于基于磁盤架構的傳統數據庫,RapidsDB在內存優化方面有四大顯著特性:一、RapidsDB是一個分布式橫向擴展系統,可以在普通硬件上擴展到數千臺機器;二、沒有緩沖池,不易造成資源爭用;三、無鎖數據結構,使用內存優化的無鎖跳過列表作為其索引,允許高吞吐量的高度并發讀寫,且讀取永遠不會被阻止;四、代碼生成,無鎖的數據結構很快導致動態SQL解釋成為限制查詢執行的瓶頸, RapidsDB可將SQL向下編譯為本機代碼,以獲得最高性能。
此外,RapidsDB雖然使用內存作為數據的主要存儲模塊,但會通過事務日志和定期快照不斷地將數據備份到磁盤,這些特性可以從同步持久性(每個事務在完成之前都記錄在磁盤上)一直調整到純內存持久性(最大持續吞吐量)。同時,RapidsDB提供選項來控制性能和持久性之間的權衡,在其最持久的狀態下,RapidsDB不會丟失任何一個已確認的事務。
重塑JOIN,實現更強大的分布式數據庫
現代社會日新月異,萬事萬物數據化生成海量大數據,并在多維時空高速傳播。為高效存儲、處理、利用好海量大數據,分布式計算逐漸成為眾多大數據平臺采用的計算方式。原因在于,分布式數據庫解決了傳統集中式單機數據庫面臨的存儲、處理等性能瓶頸。首先,分布式數據庫能夠簡便的實現橫向擴展集群,即通過增加更多的節點綜合提升數據處理能力;其次,它能實現成本優化,部署的節點可以根據應用場景需求進行靈活設計;再次,具備高容錯率,保證不會因為單點故障而影響整體的可用性。
但是,由于現實世界中數據處理繁雜多樣,分布式數據庫不能只是簡單劃分并分配計算任務給每個節點;尤其是作為數據庫中最基本、最廣泛使用的算子之一的JOIN(表連接),在分布式計算中實現系統節點間的數據交互,而隨著分布式集群規模增大,網絡數據傳輸量大增,節點之間的數據交互效率降低,從而導致分布式數據庫擴容帶來的性價比愈發降低,此時分布式數據庫往往需要重新設計JOIN,以實現更優性能,降低部署成本。
面對這一問題,柏睿數據RapidsDB基于BLOOM JOIN(布隆連接)和BLOOM FILTER(布隆過濾器)提出了解決方案。BLOOM JOIN通過在節點集群中連接BLOOM FILTER,能夠完成數據篩選、處理、連接工作;借助BLOOM JOIN,分布式數據庫能夠排除不使用、不必要的大量數據,保留具有查詢意義的數據,以達到高效數據交互的目的。
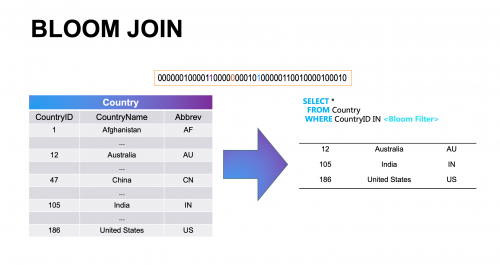
由BLOOM JOIN連接的BLOOM FILTER也被稱為概率數據結構,它能夠將大型數據壓縮進一個非常復雜的數據結構,例如將原本幾百個二進制位數據,變成只有一個或幾個二進制位數據。因此,BLOOM FILTER比其他數據結構更節省空間,盡管它存在一定的誤判,但這并不影響其性能優化目標的實現。

事實上,RapidsDB很早就已經開始部署BLOOM JOIN,然而當前許多數據庫系統都還沒有部署;即使已經部署了BLOOM JOIN的數據庫,其使用方式也比較復雜,會對工作效率造成一定影響。不僅如此,柏睿數據的數據庫產品還會智能地使用BLOOM JOIN,即數據庫系統會動態探測和優化連接,根據不同的數據需求,自主選擇BLOCK JOIN或 HASH JOIN,這也是RapidsDB的智能之處。
知之愈明,則行之愈篤。柏睿數據專家團隊厚植數據庫“卡脖子”技術,以“做中國的國際智能數據算力公司”為己任,堅持自主創新,以“DATA+AI”技術為核心,致力于打造更快、更簡單、更低成本的領先數據智能分析處理平臺,助力政企全面釋放數據生產力,在數字化轉型的道路上行穩致遠,加快數字經濟時代的到來。





