
關鍵詞:深度學習;高性能計算;數據分析;數據挖掘;LLM;PPO;NLP;ChatGPT;人工智能;高性能服務器;HPC;AIGC
隨著人工智能、深度學習、高性能計算、數據分析、數據挖掘、LLM、PPO、NLP等技術的快速發展,ChatGPT得到快速發展。ChatGPT是OpenAI開發的大型預訓練語言模型,GPT-3模型的一個變體,經過訓練可以在對話中生成類似人類的文本響應。
ChatGPT背后的算法基于Transformer架構,這是一種使用自注意力機制處理輸入數據的深度神經網絡。Transformer架構廣泛應用于語言翻譯、文本摘要、問答等自然語言處理任務等領域。ChatGPT可用于創建能與用戶進行對話的聊天機器人。

一、何為ChatGPT?和過去的人工智能有哪些區別?
ChatGPT是人工智能革命性的一大進步,眾所周知,過去想要尋找某個問題的答案,可以百度、谷歌等搜索頁面上手動搜索各種答案,百度和谷歌只通過爬蟲技術搜索大量已知問題的相關答案。但是ChatGPT不一樣,ChatGPT幾乎所有的問題都可以智能地回答,并且保證原創性,答案與以前發表的任何已知答案完全不同!ChatGPT甚至可以編程、繪畫、寫詩、寫文章!
目前,微軟正在就ChatGPT開發者OpenAI投資100億美元進行談判。如果達成交易,OpenAI估值將達到290億美元。與此同時,微軟正在將OpenAI人工智能技術納入其辦公軟件Office。
據悉,OpenAI與微軟的合作歷史悠久。2019年,OpenAI在微軟投資10億美元后,隨后兩家公司進行了多年的合作,OpenAI開發微軟Azure云計算服務中的人工智能超級計算技術。

二、ChatGPT訓練全過程
ChatGPT作為一個智能對話系統,效果極其震撼。記得上一次引起如此轟動的AI技術是兩年半以前的事了,那時候人工智能如日中天;多模態領域是以DaLL E2、Stable Diffusion為代表的Diffusion Model,也就是最近一直流行的AIGC模型。
在整體技術路線上,ChatGPT引入了“手動標注數據+強化學習”(RLHF,從人的反饋進行強化學習)來不斷Fine-tune預訓練語言模型。主要目的是讓LLM模型學會理解人類命令的含義(比如寫一篇短文生成問題、知識回答問題、頭腦風暴問題等不同類型的命令),讓LLM學會判斷對于給定的提示輸入指令(用戶的問題)什么樣的回答是優質的(富含信息、內容豐富、對用戶有幫助、無害、不包含歧視信息等多種標準)。
在“人工標注數據+強化學習”的框架下,具體來說,ChatGPT的訓練過程分為以下三個階段:
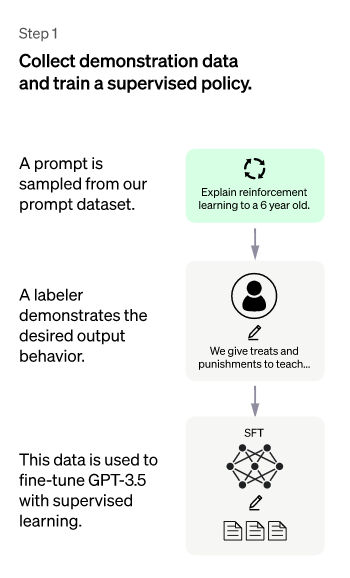
1、第一階段
以GPT 3.5本身來說,雖然強大,但是很難理解不同類型的人類不同指令中所包含的不同意圖,也很難判斷生成的內容是否是高質量的結果。為讓GPT 3.5初步理解指令中包含的意圖,首先會隨機抽取一批測試用戶提交的prompt(即指令或問題),由專業的標注者對指定的提示給出高質量的回答,然后專業人員標注的數據對GPT 3.5模型進行微調。通過這個過程,可以認為GPT 3.5初步具備了理解人類提示所包含的意圖,并根據這種意圖給出相對高質量答案的能力。
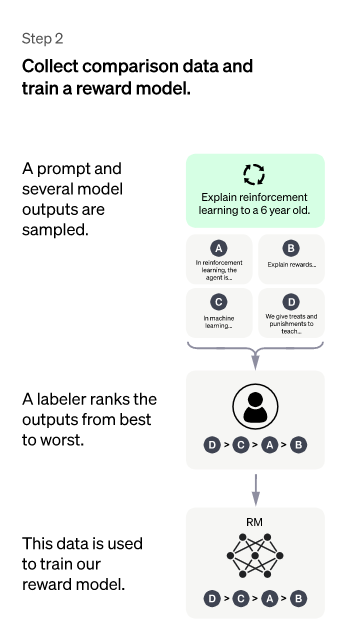
2、第二階段
在這個階段里,首先由冷啟動后的監督策略模型為每個prompt產生X個結果,人工根據結果質量由高到低排序,以此作為訓練數據,通過pair-wise learning to rank模式來訓練回報模型。對于學好的RM模型來說,輸入,輸出結果的質量得分,得分越高說明產生的回答質量越高。
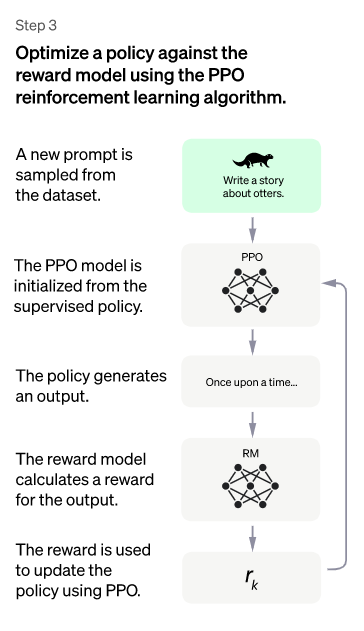
3、第三階段
本階段不需要手動標注數據,而是使用前一階段學習的RM模型,根據RM評分結果更新預訓練模型的參數。具體來說,首先從用戶提交的prompt中隨機抽取一批新的命令(指不同于第一、第二階段的新提示,實際上非常重要,對于提升LLM模型理解instruct指令的泛化能力很有幫助),由冷啟動模型初始化PPO模型的參數。然后對于隨機選取的prompt,用PPO模型生成回答answer,用前一階段訓練好的RM模型給出answer質量評估的獎勵分數,這是RM對整個答案(由詞序列組成)給出的整體reward。有了單詞序列的最終回報,每個單詞可以視為一個時間步長,把reward由后往前依次傳遞,由此產生的策略梯度可以更新PPO模型參數。這是標準的強化學習過程,目的是訓練LLM產生高reward的答案,也即是產生符合RM標準的高質量回答。
如果我們不斷重復第二和第三階段,很明顯,每次迭代都使LLM模型越來越強大。因為在第二階段,RM模型的能力通過人工標注數據來增強的,而在第三階段,增強的RM模型對新prompt產生的回答進行更準確的評分,并使用強化學習來鼓勵LLM模型學習新的高質量內容,這類似于使用偽標簽來擴展高質量的訓練數據,所以LLM模型得到進一步增強。顯然,第二階段和第三階段是相互促進的,這就是為什么不斷迭代會有不斷增強的效果。
盡管如此,小編認為在第三階段采用強化學習策略并不一定是ChatGPT模型效果特別好的主要原因。假設第三階段不采用強化學習,取而代之的是以下方法:類似于第二階段的做法,對于一個新的prompt,冷啟動模型可以生成X個答案,分別由RM模型打分。我們選擇得分最高的答案形成新的訓練數據,并進入fine-tune LLM模型。假設換成這種模式,相信效果可能會比強化學習更好。雖然沒那么精致,但效果不一定差很多。第三階段無論采用哪種技術模式,本質上很可能都是利用第二階段學會的RM,起到了擴充LLM模型高質量訓練數據的作用。
以上是ChatGPT的訓練過程,這是一個改進的instructGPT,改進點主要是標注數據收集方法上的一些差異。其他方面,包括模型結構和訓練過程,基本遵循instructGPT。可以預見的是,這種Reinforcement Learning from Human Feedback技術將會迅速蔓延到其他內容生成方向,比如一個很容易想到的方向,類似“A machine translation model based on Reinforcement Learning from Human Feedback”等等。
但個人認為在NLP的某個特定內容生成領域采用這種技術意義不大,因為ChatGPT本身可以處理各種類型的任務,基本涵蓋了NLP生成的很多子領域。所以對于某個NLP子領域,單獨采用這種技術的價值不大,因為其可行性可以認為已經被ChatGPT驗證了。如果將這種技術應用于其他模式的生成,如圖片、音頻、視頻等,可能是更值得探索的方向。也許很快就會看到類似“A XXX diffusion model based on Reinforcement Learning from Human Feedback”之類的東西。
三、藍海大腦高性能深度學習ChatGPT一體機
藍海大腦通過多年的努力,攻克了各項性能指標、外觀結構設計和產業化生產等關鍵技術問題,成功研制出藍海大腦高性能深度學習ChatGPT一體機,支持快速圖形處理,GPU 智能運算,性價比高,外形美觀,滿足了人工智能企業對圖形、視頻等信息的強大計算處理技術的需求。
快速、高效、可靠、易于管理的藍海大腦液冷工作站具備出色的靜音效果和完美的溫控系統。在滿負載環境下,噪音控制在 35 分貝左右。借助英偉達 NVIDIA 、英特爾Intel、AMD GPU顯卡可加快神經網絡的訓練和推理速度,更快地創作精準的光照渲染效果,提供高速視頻和圖像處理能力,加速AI并帶來更流暢的交互體驗。
突破傳統風冷散熱模式,采用風冷和液冷混合散熱模式——服務器內主要熱源 CPU 利用液冷冷板進行冷卻,其余熱源仍采用風冷方式進行冷卻。通過這種混合制冷方式,可大幅提升服務器散熱效率,同時,降低主要熱源 CPU 散熱所耗電能,并增強服務器可靠性;支持VR、AI加速計算;深受廣大深度學習ChatGPT領域工作者的喜愛。

1、主要技術指標
可 靠 性:平均故障間隔時間MTBF≥15000 h
工作溫度:5~40 ℃
工作濕度:35 %~80 %
存儲溫度:-40~55 ℃
存儲濕度:20 %~90 %
聲 噪:≤35dB
2、產品特點
集中管理:支持多種異構硬件平臺、操作系統和應用程序,提供單一系統鏡像,實現計算節點和圖形工作站節點的集中管理和統一調度
負載均衡:提供強大的負載均衡能力,保證計算服務器的任務分配盡可能均勻,避免機器忙閑不均的現象。并根據服務器的負載指標(如CPU利用率、可用內存、IO等),可以采取保護措施
資源的有效利用:避免計算任務之間發生沖突,導致任務失敗或計算時間延長
優先級管理:確保在資源不足時,緊急的項目或任務可以獲得更高的優先級,從而更快地啟動,避免影響設計和工程的進度
3、客戶收益
實現統一的用戶登錄、驗證、作業管理、數據管理;實現資源跨部門共享以及利用率最大化
加快企業的產品研發進度、大幅縮短研發周期、提升產品的設計開發效率
提供統一平臺,最大化提升在深度學習、虛擬圖像、HPC等領域的快速響應以及精準預測,帶來更流暢的交互體驗
提高客戶滿意度,在圖像、視頻、聲音等提供實時用戶體驗、加快搜索速度
降低總體擁有成本,簡化工作流程,加速多種工作負載,提高生產力,促進企業創新





