
編輯:桃子 好困
【新智元導讀】最近,一位「冷門歌手」竟靠著AI替身,翻唱華語樂壇歌曲爆紅全網。
一夜之間,「AI孫燕姿」火遍全網。
B站上,AI孫燕姿翻唱的林俊杰「她說」、周董「愛在西元前」、趙雷「成都」等等,讓一眾網友深陷無法自拔。
「冷門歌手」孫燕姿新晉成為2023年度熱門歌手,掀起許多人的追星狂歡。
網友表示,「聽了一晚上AI孫燕姿,出不去了……」

這些翻唱歌曲,是由Eternity丨L、羅斯特_x等UP主通過開源項目自制后并上傳。
(作者似乎特意在「半島鐵盒」中加入了一秒空白,湊成5分20秒)
UP主:Eternity丨L
除了AI孫燕姿,還有AI周杰倫,AI王心凌、AI林志炫…

可能許多人做夢也沒有想到,2023年華語樂壇竟以這種形式復興了。
「AI孫燕姿」在線營業
前段時間,一位TikTok網友用AI創作了一首「Heart on My Sleeve」很快躥紅網絡,引來1000多萬人圍觀。
聽完這首歌的網友紛紛表示,太讓我驚訝了,簡直太瘋狂!
這首歌正是用兩位美國流行音樂人Drake和The Weeknd的聲音創作而成。先通歌手聲音訓練AI,然后再用AI來創作。

在國內,B站上AI翻唱的華語樂壇歌曲也漸漸成為許多人關注的焦點,孫燕姿、王心凌、周杰倫等明星紛紛「復出」。
而最火的莫過于孫燕姿,憑借「天后音色」的稱號,直接成為AI新寵兒。
UP主:羅斯特_x
有人還自制了AI孫燕姿粵語版《愛來的太遲》。
然而,對于AI音樂制作,在整個音樂行業并非是一個新事物了。只不過生成式AI的大火,讓AI翻唱的門檻再次被拉低。
比如,年初,谷歌還曾推出了文本到音樂模型MusicLM,通過將音樂的生成過程視為分層的序列到序列建模任務,并以24 kHz的頻率生成高保真的音樂。

對于許多歌迷來講,AI翻唱一定程度上滿足了自己的許多遐想。
還有一些歌迷,自己訓練了已故經典老歌手的AI,包括阿桑、張國榮、姚貝娜、鄧麗君等等。
這或許是一種數字永生,通過這樣一種方式讓久違的聲音再次回到人們心里。

Midjourney出圖逼真的超強能力,讓人們驚呼畫家要失業了。對于AI翻唱,難道歌手也要被去取代嗎?
一位UP主@阿張Rayzhang用自己的音色訓練出的AI唱Killer Queen后,瞬間感覺太恐怖了。
緊急錄制一個視頻后,并附上了「AI歌手會讓翻唱區集體失業嗎?我被AI版的我爆殺!」標題。
有網友稱,自己就是AI第一批受害者畫手,感覺什么職業也逃不掉。

有些人也表示,翻唱的有些地方一點也不像。
要知道,對于AI翻唱來講,也需要豐富的特定藝術家音色訓練數據,這樣AI生成的作品才更加真實。
就目前的技術,雖然歌手的唱腔、技巧和風格等還不能完全模仿,但音色已經基本能完全復刻。
但是真正的大家是不能被取代。

AI翻唱火雖火,但由AI創作音樂的另一面,是迫在眉睫的版權問題。
AI創作的「Heart on My Sleeve」在TikTok上風靡一時后,完整版被上傳到了Apple Music、Spotify、YouTube等平臺上。
就此,美國歌手Drake對此在Ins表達了不滿,「這是(壓死駱駝的)最后一根稻草了」。目前,這首歌因為侵權問題已經下架。
《金融時報》稱,擁有Taylor Swift、Bob Dylan等巨星版權的環球音樂集團,正敦促Spotify和蘋果阻止AI工具從其藝術家的版權歌曲中抓取歌詞和旋律。
但是有些藝術家卻不吝嗇自己的聲音,馬斯克前女友Grimes在網上表示,
「任何人都可以使用我的聲音AI生成歌曲。」不過,還得再付50%的版權。

而這次大火的AI翻唱背后的原始項目「so-vits-svc」的作者,據稱也是因為太多人濫用,而刪除了項目。
SoVitsSvc:唱歌聲音轉換

歌聲轉換模型使用SoftVC內容編碼器來提取源音頻語音特征,然后將向量直接送入VITS,而不是轉換為基于文本的中間格式。因此,音高和音調都可以被保留下來。
此外,項目開發者還通過采用NSF HiFiGAN作為聲碼器(vocoder),從而解決了聲音中斷的問題。

· 特征輸入改為Content Vec · 采樣率統一使用44100Hz
· 由于參數的改變,以及模型結構的精簡,推理所需的GPU顯存明顯減少。
· 增加選項1:vc模式的自動音高預測,這意味著在轉換語音時不需要手動輸入音高鍵,男聲和女聲的音高可以自動轉換。但是,這種模式在轉換歌曲時,會造成音高偏移。
· 增加選項2:通過k-means聚類方案減少音色泄漏,使音色與目標音色更相似。
· 增加選項3:增加NSF-HIFIGAN增強器,對一些訓練集少的模型有一定的音質增強效果,但對訓練好的模型有負面影響,所以默認關閉。
預訓練模型文件
將checkpoint_best_legacy_500.pt放在hubert目錄下。
將G_0.pth和D_0.pth放在logs/44k目錄下。
預處理
0. 音頻切片
利用audio-slicer-GUI或audio-slicer-CLI工具,將原始音頻切片至5秒-15秒。
長一點也沒問題,但太長(比如30秒)可能會在訓練甚至預處理時導致「torch.cuda.OutOfMemoryError」,俗稱爆顯存。
切片后,刪除過長和過短的音頻。
1. 重采樣至44100Hz和單聲道
python resample.py
2. 自動將數據集分成訓練集和驗證集,并生成配置文件
python preprocess_flist_config.py
3. 生成hubert和f0
python preprocess_hubert_f0.py
完成上述步驟后,dataset目錄將包含預處理的數據,dataset_raw文件夾可以被刪除。
現在,你可以修改生成的config.json中的一些參數——
keep_ckpts:在訓練中保留最后的keep_ckpts模型。設置為0將保留所有模型,默認是3。
all_in_mem:將所有數據集加載到RAM中。當某些平臺的磁盤IO太低,而系統內存比你的數據集大得多時,可以啟用。
訓練
python train.py -c configs/config.json -m 44k
推理
模型在需要使用「inference_main.py」。
舉個例子:
python inference_main.py -m “logs/44k/G_30400.pth” -c “configs/config.json” -s “nen” -n “君の知らない物語-src.wav” -t 0
雖然原始項目組現已停止維護,但有不少網友都進行了fork并且也做了一些更新。
比如下面這個圖形化界面:
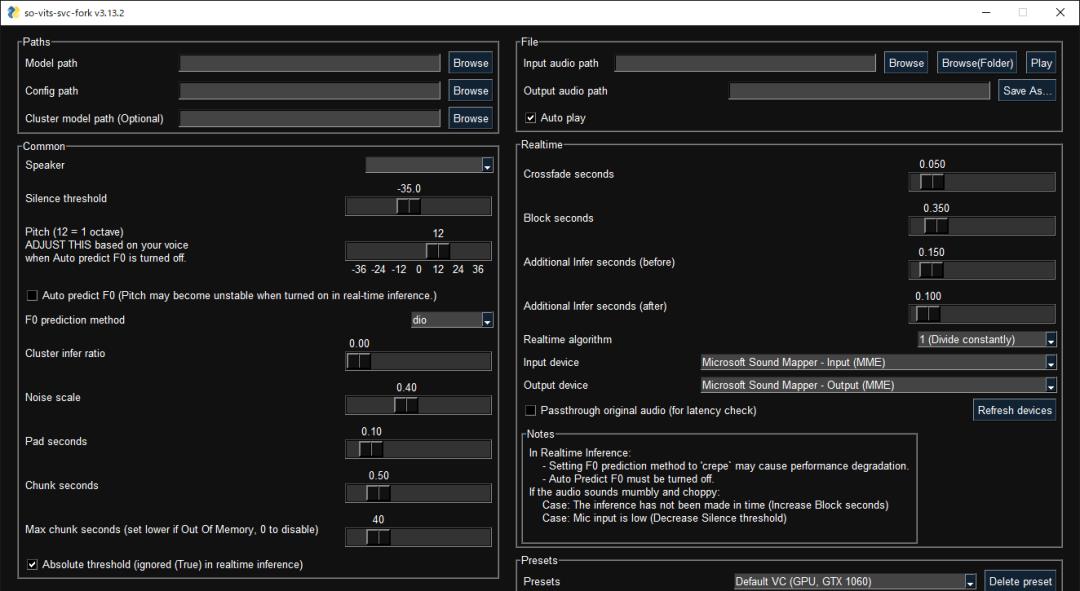
AI「復活」
AI翻唱之外,許多網友此前曾做了類似的項目,比如「AI-Talk」讓馬斯克和喬布斯進行了穿越時空的對話。
視頻中,AI不但模擬了他們的聲音,還在一定程度上模擬了其對話思路,使得交流過程十分流暢。
AI讓我們與逝者的對話成為可能。此前,B站UP主用AI還復活了老奶奶。
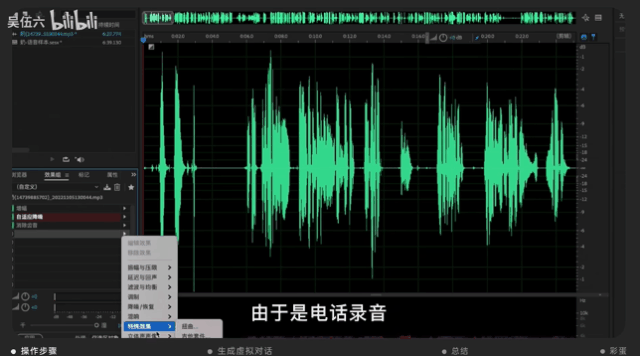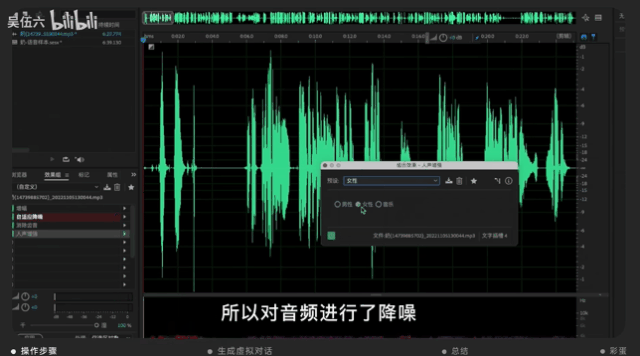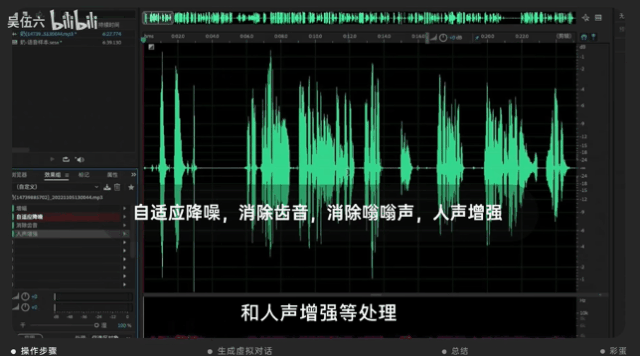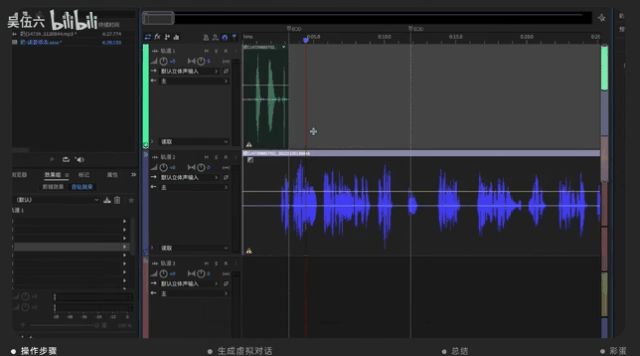
對于老奶奶的聲音制作,直接把過去已有的音頻上傳,素材基本來自于過去的電話錄音、錄像視頻或者微信語音。
并用音頻編輯軟件AU進行調整,調整的方向主要在降噪、人聲增強等等。
然后將更加清晰的音頻樣本切割成若干秒的短句,方便進行標注。最后將處理好的音頻打包放入語音合成系統中去。
利用語音合成系統,就可以嘗試輸入文本轉語音了。
網友見證科技狠活
AI孫燕姿的歌,已經唱到許多網友的心坎。

最近沉迷AI「翻唱」,上至AI侃爺唱罰酒,下至蘇小玎唱真相是真。但說句正經的,確實還是AI屆頂流孫燕姿的翻唱最好聽。

這幾天沉迷B站的AI孫燕姿,剛剛聽了一首《一場游戲一場夢》,太好聽了,唱到心坎里

不少網友聽過AI翻唱的歌曲后,感受到AI歌手的可怕之處:
科技的力量真是讓人細思極恐。

深深感受到了什么叫做科技的力量……

這就是AI生命,數字飛升!

還有網友對逝去歌手的懷念。

參考資料:





