
01 聯邦大模型開源平臺FATE-LLM最新版發布,在橫向聯邦場景支持ChatGLM-6B的聯邦化訓練
當前,AI大模型已成為科技創新和數字經濟領域的熱點,其高速進程中面臨的諸多問題也引發了業內關注。FATE開源社區技術指導委員會主席楊強教授指出:“即將消耗殆盡的公域數據,日趨高漲的隱私安全保護需求,以及眾多異構小模型的整合需求,已成為AI 大模型發展之路上亟待突破的瓶頸。而聯邦大模型正是解決這些問題的有效路徑。”在此背景下,FATE社區開源了FATE-LLM聯邦大模型功能模塊,以聯邦學習+大模型的技術解決方案破局數據隱私保護與數據不足等問題,以應對行業發展的新挑戰。
近期,聯邦大模型開源平臺FATE-LLM最新版發布,在橫向聯邦場景支持ChatGLM-6B中文語言大模型。集成GLM的FATE-LLM將會為國內用戶提供更好的中文大模型應用落地選擇。
GLM系列大模型由清華大學和智譜AI聯合研發,其中ChatGLM-6B是一個開源的、支持中英雙語問答的對話語言模型,并針對中文進行了優化。該模型基于 General Language Model (GLM) 架構,具有 62 億參數。結合模型量化技術,用戶可以在消費級的顯卡上進行本地部署(INT4 量化級別下最低只需 6GB 顯存)。開源兩個月以來,ChatGLM-6B在全球最大開源軟件平臺GitHub上獲得超過26萬星,超過斯坦福同期模型的關注度和好評度,全球下載量超過200萬,并連續兩周登上全球最大開源大模型平臺 Hugging Face大模型趨勢榜榜首。

此次更新的FATE-LLM v1.1版本在橫向聯邦場景支持Adapter,Prompt這類高效聚合方法,可以顯著提升聯邦大模型訓練效率,其中參數微調方法支持Lora以及P-Tuning V2 。而在框架層,FATE實現對DeepSpeed的集成,使得FATE-LLM支持多機多卡訓練,支持分布式GPU集群資源調度和管理,支持數據、模型參數等不同并行化加速方法。用戶只需要任務提交階段直接增加配置即可享受到多機多卡的加速能力。
02 FATE-LLM v1.1功能介紹
1、亮點概述
1)集成業界開源的主流中文語言大模型ChatGLM-6B,支持高效的參數微調機制Lora、P-Tuning V2等方法,提升聯邦訓練的通信效率和訓練效率;
2)FATE實現對DeepSpeed框架集成,使得FATE具備多機多卡聯邦大模型加速訓練能力:支持分布式GPU集群資源調度和管理;支持數據、模型參數等不同并行化加速方法。
2、 功能一覽
1)ChatGLM-6B聯邦化支持,并支持LoRa、P-Tuning V2 高效微調方案;
2)FATE多機多卡聯邦大模型訓練能力支持,在任務提交階段增加相關配置即可使用數據、模型等不同階段的訓練加速能力,與用戶模型訓練代碼解耦;
3)FATE支持分布式GPU集群資源管理功能;
4)支持使用transformers庫的data collator類,可以更靈活地處理訓練輸入數據;
5)支持只保存可訓練參數,降低訓練階段checkpoints保存的硬盤占用,方便模型拷貝使用。
3、 實驗數據一覽
1)高效參數微調機制的參數量及其訓練參數占比
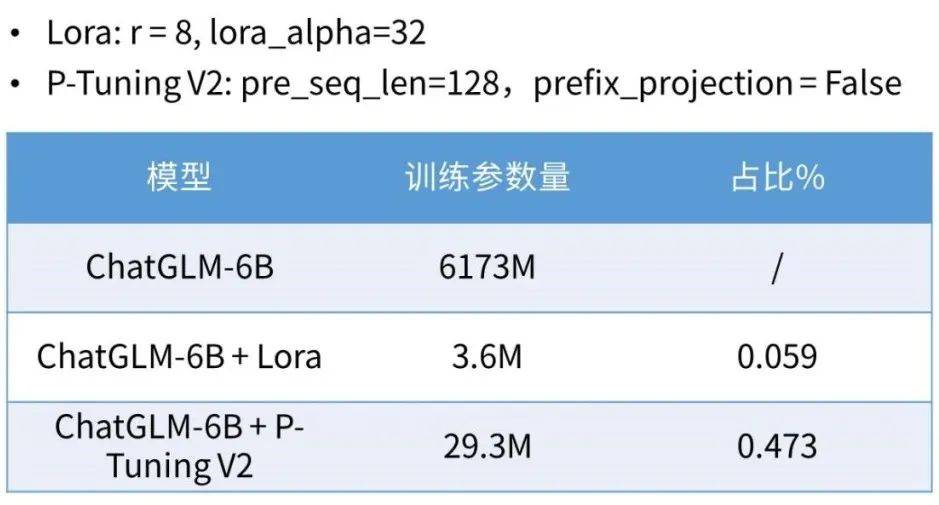
2)場景及數據、以及配置
聯邦場景:橫向聯邦,兩個參與;應用場景:兩個參與方各持有部分數據,數據格式:<廣告關鍵字,廣告宣傳語>,希望模型可以根據輸入的廣告關鍵字去自動生成廣告宣傳語,通過聯邦建模去提升廣告生成詞的效果。
下面給出效果示例:
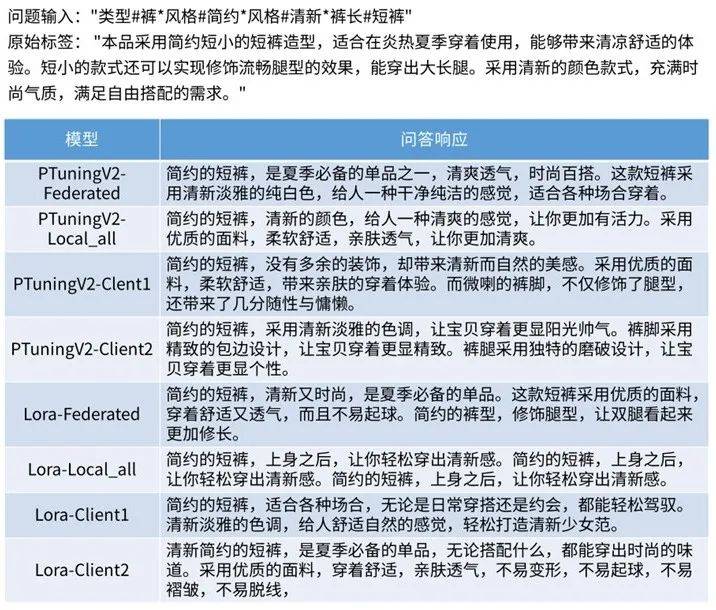
數據集:AdvertiseGen,可參考https://aclanthology.org/D19-1321.pdf,為廣告生成數據集;訓練數據隨機切分,其中client-1數據量為57478,client-2數據量為57121環境:局域網環境,client-1和client-2機器配置完全一致,單個client使用2臺機器,每臺機器有4張V100 32G 資源;配置:DeepSpeed: stage=2,batch_size_per_device=4;數據集的提問(content)及回答(summary)兩列tokenize后,token_ids長度超過64的會截斷。
3)訓練效果:
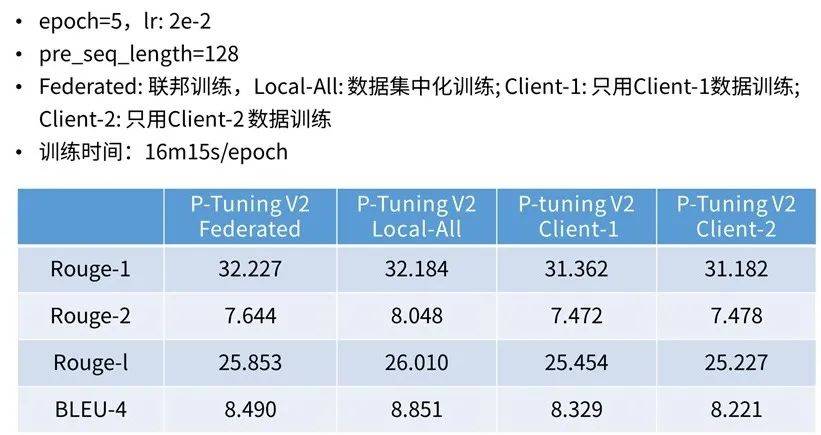
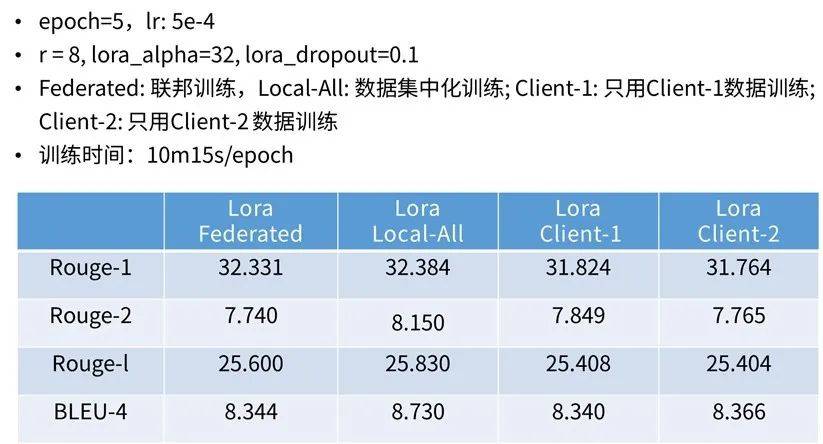
03 開源共建,是助推聯邦大模型快速發展的不竭動力
未來,支持中文大語言模型ChatGLM-6B聯邦化訓練的FATE-LLM將通過聯合多家公司和組織,充分利用分散數據,融合聯邦學習和AIGC相關技術,實現異構數據分布式安全訓練。其中針對中文方面的優化,將為金融、教育、醫療等領域的應用帶來更強大的支持,例如人工智能助手、智能問答、自然語言處理等場景將會得到進一步的效果提升。
FATE-LLM模塊將持續迭代,未來將持續解決訓練、微調和使用推理階段的隱私保護問題,并堅持推出后續版本。聯邦大模型將大模型與隱私計算核心技術手段融合,使大模型的“野蠻生長”轉向更加安全可靠的發展賽道,在提升AI通用性的同時不違背監管與倫理的要求,推進AI技術高質量發展。

清華大學教授唐杰表示:“作為科研人員,我們希望在開展大模型技術研究與應用落地的同時,也進一步降低人工智能的使用門檻,實現技術普惠,為行業良性發展做出一些貢獻。”
飲其流者懷其源。開源不僅是一種技術選擇,更是一種分享態度與溝通方式。開源平臺和開源生態將助推大模型的快速迭代與落地應用。我們期待有更多的用戶和開發者加入FATE開源社區。在獲得項目發展成果的同時,通過積極參與項目等方式回饋社區。形成互惠互助的良性循環,推動社區生態健康發展!






