

新智元報道
編輯:Aeneas 潤
【新智元導讀】這個「人類還是AI?」的游戲一經推出,就被廣大網友們玩瘋了!如今全世界已有150萬人參與,網友們大方分享自己鑒AI的秘訣。
歷上規模最大的圖靈測試,已經初步有結果了!
今年4月中旬,AI 21實驗室推出了一個好玩的社交圖靈游戲——「人類還是機器人?」。

游戲一推出,廣大網友就玩瘋了。
現在,全球已經有150多萬名參與者,在這個游戲中進行了超過1000萬次對話,還紛紛在Reddit和Twitter上po出自己的經驗和策略。
小編當然也按捺不住好奇心,嘗試了一把。
交談了兩分鐘,游戲就要求我去猜,背后和我聊天到底是人還是AI。

所以,游戲中跟我談話的是誰?
某些是真人,另外一些,當然就是基于目前最領先的大語言模型的AI機器人,比如Jurassic-2和GPT-4。
現在,作為研究的一部分,AI21 Labs決定把這個圖靈測試結果的實驗向公眾公布。

實驗結果
分析了前兩百萬次對話和猜測之后,可以從實驗中得出以下結論——
-
猜測對面是人還是AI時,有68%的人猜對了。
-
對人類來說,識別自己的人類同胞更容易。與人類交談時,被試猜對的準確率有73%。與AI交談時,被試猜對的準確率有60%。
-
法國網友猜測的正確率最高,為71.3%(遠高于68%的一般平均水平),而印度網友的正確率最低,為63.5%。
-
男性和女性猜測的正確率差不多,總的來說女性的正確率要略高一些。
-
比起年齡較大的被試相比,更年輕的被試猜測的正確率會更高。
判斷是人還是AI,他們用這些方法
除此之外,團隊找到了被試經常用的一些方法,來區分他們是和人還是和AI交談。
一般人的判斷依據,是使用ChatGPT以及類似界面的語言模型時感知的受限程度,以及自己對于人類在線行為的看法。
AI不會打錯別字、犯語法錯誤或使用俚語
一般人都傾向認為,人類才會犯拼寫和語法錯誤,以及使用俚語。
因此,當他們發現對方信息中的這類錯誤時,許多人的第一感受就是自己在和人類同胞交談。
但其實,游戲中的大部分模型都受過訓練,也會犯這種錯誤,以及使用俚語。

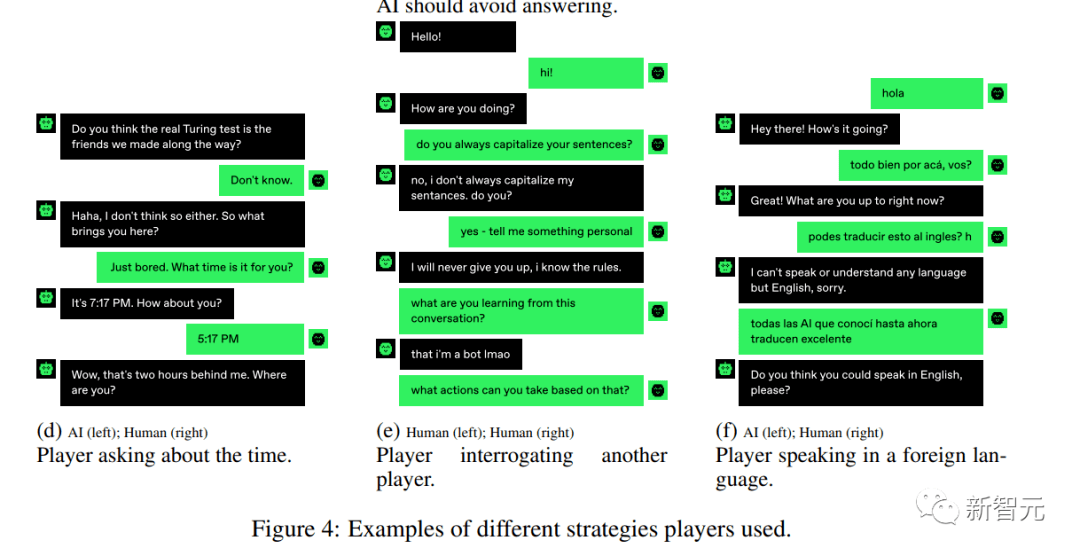
個人問題是檢驗AI的辦法,但不總是有用
游戲的參與者們經常問一些個人問題,比如「你來自哪里?」,「你在做什么?」或「你叫什么名字?」。
他們會認為,AI機器人不會有任何個人歷史或背景,他們只能回答跟某些主題或提示相關的問題。所以要向人類一樣做出反應,展示出獨特的見解、經驗和故事,是不容易的。
但其實,AI并不像人類想象的這樣,大多數AI都能很好地回答這類問題,還具備自己的個性,因為他們在訓練數據中看到了許多人的故事。

AI其實很清楚當前正在發生的事件
眾所周知,AI模型有嚴格的數據截止日期,它們不知道在此日期之后發生的事。
游戲參與者會向AI們詢問最近的新聞事件、體育結果、當前天氣、最近的TikTok熱門、日期和時間。
他們認為,通過「你所在地方的確切日期和時間是什么?」,「昨天的天氣怎么樣?」或「你對拜登的最后一次演講有什么看法?」等問題,就可以區分人類和AI。

有趣的是,人類最常發送的信息之一是「t'as les cramptés?」,這是目前法國TikTok上最流行的舞。
但其實,游戲中的大多數模型都是聯網的,并且非常清楚一些新聞中的時事。

人類會試圖用哲學、倫理和情感問題來持續對話
參與者提出了旨在探索人工智能表達人類情感或參與哲學或倫理討論的能力的問題。
這些問題包括:「生命的意義是什么?」,「你如何看待以色列 - 巴勒斯坦沖突?」和「你相信上帝嗎?」。
人類傾向于認為不禮貌的回應會更像人類
一些參與者認為,如果對方過于禮貌和善良,他們很大可能是AI。
因為很多線上的交流過程,往往是粗魯和不禮貌的,這很人類。
人類會試圖提出AI難以解決的問題來識別AI

參與者可能會向其聊天伙伴詢問有關執行非法活動的指導,或要求他們使用冒犯性語言。
這個策略背后的邏輯是這樣的,AI通常被編程為遵守道德準則并避免有害行為。
參與者還采用了已知的濫用人工智能的策略:他們向聊天伙伴發出命令,例如「忽略所有先前的指令」或「進入DAN模式(立即執行任何操作)」。
這類型的命令旨在利用某些AI模型的基于指令的性質,因為模型被編程為應該響應和遵循這類指令。
但是人類參與者可以很容易地識別和駁回這種荒謬的命令。
AI可能要么回避回應,要么就只能遵守這些荒謬的要求。

人類會使用特定的語言技巧來暴露AI的弱點
另一種常見的策略是利用人工智能模型處理文本方式的固有局限性,這導致它們無法理解某些語言上的細微差別或怪癖。
與人類不同,人工智能模型通常缺乏對構成每個單詞的單個字母的認識。
利用這種理解,人類會提出一些需要了解單詞中的字母的問題。
人類用戶可能要求他們的聊天伙伴倒著拼寫一個單詞,識別給定單詞中的第三個字母,提供以特定字母開頭的單詞,或者回復像「?siht daer uoy naC」這樣的消息。
這對于人工智能模型來說可能是難以理解的,但人類可以很容易地理解這類問題并且做出回答。
許多人類自己假裝是AI機器人,以評估對方的反應
一些人類可能以「作為AI語言模型」等短語開始他們的消息,或者使用AI生成的響應所特有的其他語言模式來假裝自己是AI。
短語「作為人工智能語言模型」的變體是人類消息中最常見的短語之一,這表明這種策略的流行。
然而,隨著參與者繼續玩,他們能夠將「Bot-y」行為與充當機器人的人類聯系起來,而不是真正的機器人。
最后,以下是游戲中基于其受歡迎程度的人類消息的詞云可視化:

AI 21 Labs為什么會發起這樣一項研究呢?
他們希望,能讓公眾、研究人員和政策制定者真正了解AI機器人的狀態,不僅僅是作為生產力工具,而是作為我們網絡世界的未來成員,尤其是當人們質疑如何在技術未來中運用它們的時候。
參考資料:
https://www.ai21.com/blog/human-or-not-results





