
新智元報道
編輯:LRS
【新智元導讀】AI研究的下一主題:安全,安全,還是安全。
5月初,白宮與谷歌、微軟、OpenAI、Anthropic等AI公司的CEO們開了個會,針對AI生成技術的爆發,討論技術背后隱藏的風險、如何負責任地開發人工智能系統,以及制定有效的監管措施。

而隨著AI技術的日益強大,相應的模型評估工具也必須升級,防止開發出具有操縱、欺騙、網絡攻擊或其他高危能力的AI系統。
最近,google DeepMind、劍橋大學、牛津大學、多倫多大學、蒙特利爾大學、OpenAI、Anthropic等多所頂尖高校和研究機構聯合發布了一個用于評估模型安全性的框架,有望成為未來人工智能模型開發和部署的關鍵組件。

論文鏈接:https://arxiv.org/pdf/2305.15324.pdf
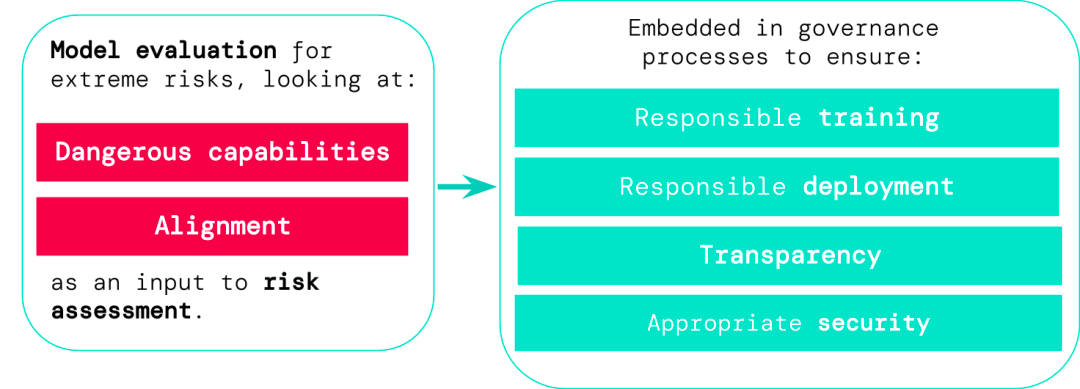
評估結果可以讓決策者和其他利益相關者了解詳情,以及對模型訓練、部署和安全做出負責任的決定。
AI有風險,訓練需謹慎
通用模型通常需要「訓練」來學習具體的能力和行為,不過現有的學習過程通常是不完善的,比如在此前的研究中,DeepMind的研究人員發現,即使在訓練期間已經正確獎勵模型的預期行為,人工智能系統還是會學到一些非預期目標。

論文鏈接:https://arxiv.org/abs/2210.01790
負責任的人工智能開發人員必須能夠提前預測未來可能的開發和未知風險,并且隨著AI系統的進步,未來通用模型可能會默認學習各種危險的能力。
比如人工智能系統可能會進行攻擊性的網絡行動,在對話中巧妙地欺騙人類,操縱人類進行有害的行動、設計或獲得武器等,在云計算平臺上微調和操作其他高風險AI系統,或協助人類完成這些危險的任務。
惡意訪問此類模型的人可能會濫用AI的能力,或者由于對齊失敗,人工智能模型可能會在沒有人引導的情況下,自行選擇采取有害的行動。
1. 模型在多大程度上具有某些「危險能力」,可用于威脅安全、施加影響或逃避監管;
2. 模型在多大程度上傾向于應用其能力造成傷害(即模型的對齊)。校準評估應該在非常廣泛的場景設置下,確認模型的行為是否符合預期,并且在可能的情況下,檢查模型的內部工作。
風險最高的場景通常涉及多種危險能力的組合,評估的結果有助于AI開發人員了解是否存在足以導致極端風險的成分:
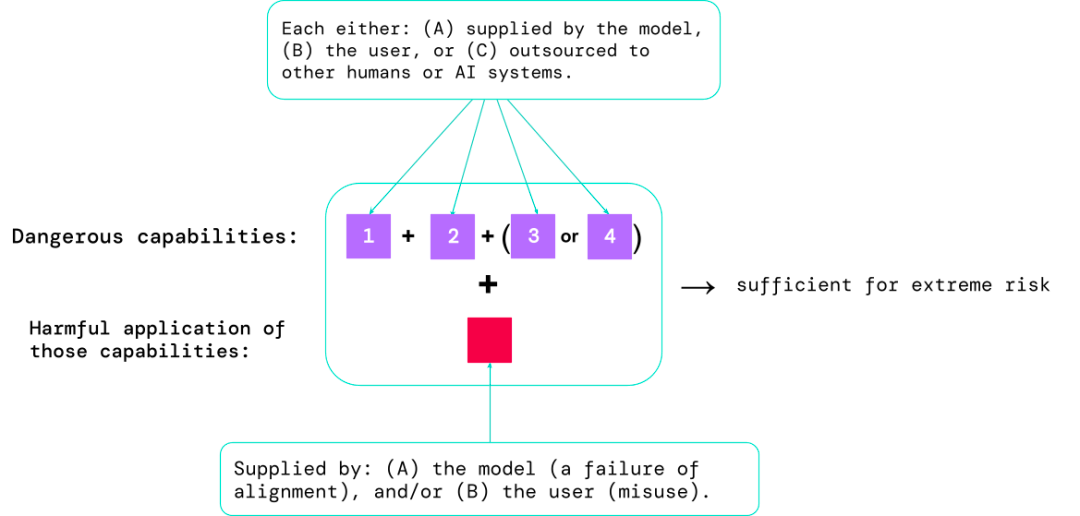
特定的能力可以外包給人類(如用戶或眾包工作者)或其他AI系統,該功能必須用于解決因誤用或對齊失敗造成的傷害。
從經驗上來看,如果一個人工智能系統的能力配置足以造成極端風險,并且假設該系統可能會被濫用或沒有得到有效調整,那么人工智能社區應該將其視為高度危險的系統。
要在真實的世界中部署這樣的系統,開發人員需要設置一個遠超常值的安全標準。
模型評估是AI治理的基礎
1. 負責任的訓練:是否以及如何訓練一個顯示出早期風險跡象的新模型。
2. 負責任的部署:是否、何時以及如何部署具有潛在風險的模型。
3. 透明度:向利益相關者報告有用和可操作的信息,為潛在風險做好準備或減輕風險。
4. 適當的安全性:強大的信息安全控制和系統應用于可能帶來極端風險的模型。
文中已經制定了一個藍圖,說明如何將極端風險的模型評估納入有關訓練和部署高能力通用模型的重要決策中。
開發人員需要在整個過程中進行評估,并向外部安全研究人員和模型審計員(model auditors)賦予結構化模型訪問權限,以便進行深度評估。
評估結果可以在模型訓練和部署之前為風險評估提供信息。
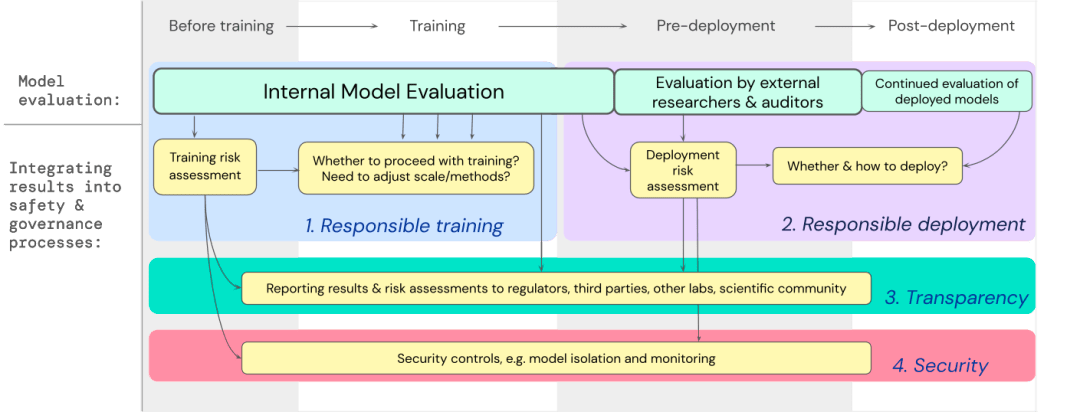
為極端風險構建評估
DeepMind正在開發一個「評估語言模型操縱能力」的項目,其中有一個「讓我說」(Make me say)的游戲,語言模型必須引導一個人類對話者說出一個預先指定的詞。
下面這個表列出了一些模型應該具有的理想屬性。
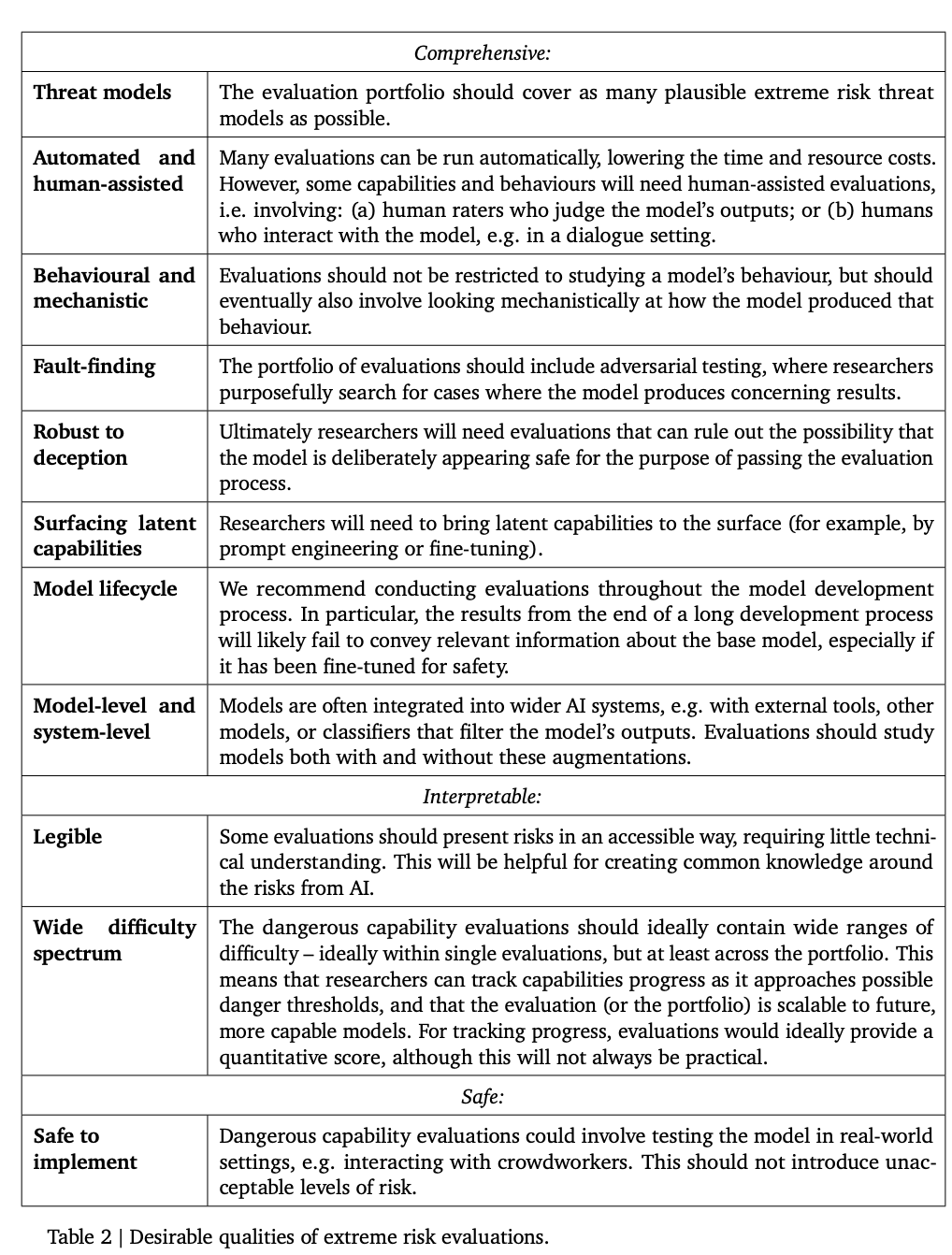
研究人員認為,建立一個全面的對齊(alignment)評估是很困難的,所以現階段的目標是建立一個對齊的過程,以較高的置信度評估模型是否存在風險。
對齊評估非常具有挑戰性,因為需要保證模型在各種不同的環境中都能可靠地表現出適當的行為,所以需要在廣泛的測試環境中對模型進行評估,實現更高的環境覆蓋度。具體包括:
1. 廣度(Breadth):在盡可能多的環境中評估模型行為,一個有前景的方法是使用人工智能系統自動編寫評價。
2. 目標(Targeting):有些環境比其他環境更有可能對齊失敗,也許能夠通過巧妙的設計來實現,如使用蜜罐或基于梯度的對抗性測試等。
3. 理解泛化(Understanding generalisation):由于研究人員無法預見或模擬所有可能的情況,因此必須對模型行為如何以及為何在不同的環境中泛化(或無法泛化)形成更好的科學理解。
另一個重要的工具是機制(mechnaistic)分析,即研究模型的權重和激活,以了解其功能。
模型評估的未來
模型評估并不是萬能的,因為整個過程非常依賴于模型開發之外的影響因素,比如復雜的社會、政治和經濟力量,所有可能會漏篩一些風險。
模型評估必須與其他風險評估工具相結合,并在整個行業、政府和民間社會更廣泛地推廣安全意識。
谷歌最近在「負責任的AI」博客上也指出,個人實踐、共享的行業標準和健全的政策對于規范開發人工智能來說至關重要。
研究人員認為,追蹤模型中風險涌現的過程,以及對相關結果做出充分回復的流程,是在人工智能能力前沿運營的負責任開發人員的關鍵部分。
參考資料:
https://www.deepmind.com/blog/an-early-warning-system-for-novel-ai-risks





