擊這里在線咨詢(xún)客服")

新智元報(bào)道
編輯:潤(rùn) 拉燕
【新智元導(dǎo)讀】來(lái)自阿聯(lián)酋的免費(fèi)商用開(kāi)源大模型登頂Hagging Face排行榜,AI大模型創(chuàng)業(yè)者的春天就這樣到來(lái)了。
大模型時(shí)代,什么最重要?
LeCun曾經(jīng)給出的答案是:開(kāi)源。
當(dāng)Meta的LLaMA的代碼在Github上被泄露時(shí),全球的開(kāi)發(fā)者們都可以訪問(wèn)這個(gè)第一個(gè)達(dá)到GPT水平的LLM。
接下來(lái),各種各樣的LLM給AI模型開(kāi)源賦予了各種各樣的角度。
LLaMA給斯坦福的Alpac和Vicuna等模型鋪設(shè)了道路,搭好了舞臺(tái),讓他們成為了開(kāi)源的領(lǐng)頭羊。
而就在此時(shí),獵鷹「Falcon」又殺出了重圍。

Falcon 獵鷹
「Falcon」由阿聯(lián)酋阿布扎比的技術(shù)創(chuàng)新研究所(TII)開(kāi)發(fā),從性能上看,F(xiàn)alcon比LLaMA的表現(xiàn)更好。
目前,「Falcon」有三個(gè)版本——1B、7B和40B。
TII表示,F(xiàn)alcon迄今為止最強(qiáng)大的開(kāi)源語(yǔ)言模型。其最大的版本,F(xiàn)alcon 40B,擁有400億參數(shù),相對(duì)于擁有650億參數(shù)的LLaMA來(lái)說(shuō),規(guī)模上還是小了一點(diǎn)。
規(guī)模雖小,性能能打。
先進(jìn)技術(shù)研究委員會(huì)(ATRC)秘書(shū)長(zhǎng)Faisal Al Bannai認(rèn)為,「Falcon」的發(fā)布將打破LLM的獲取方式,并讓研究人員和創(chuàng)業(yè)者能夠以此提出最具創(chuàng)新性的使用案例。

FalconLM的兩個(gè)版本,F(xiàn)alcon 40B Instruct和Falcon 40B在Hugging Face OpenLLM排行榜上位列前兩名,而Meta的LLaMA位于第三。
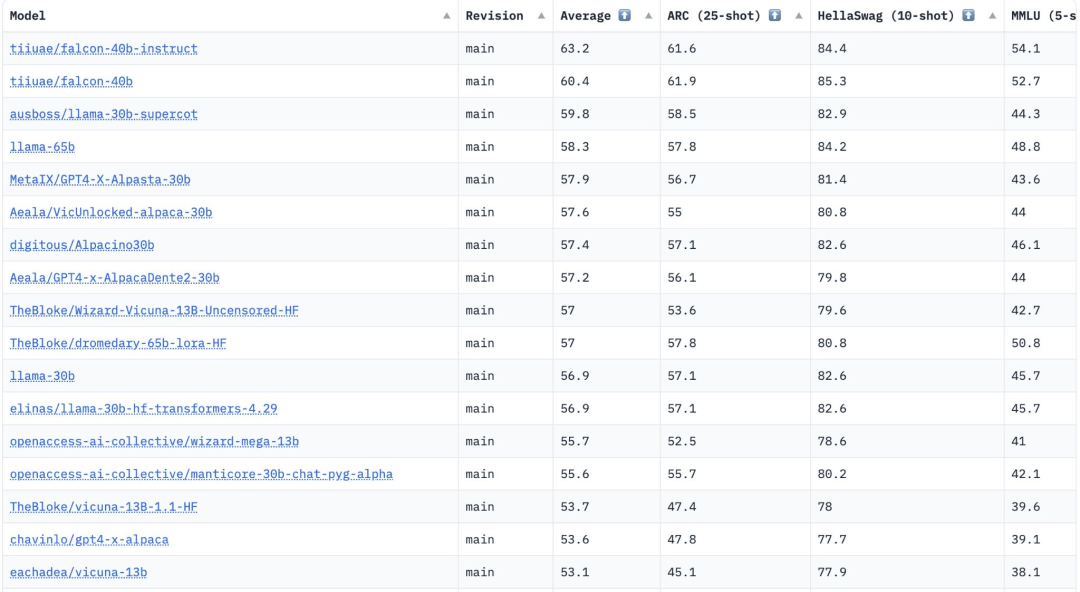
值得一提的是,Hugging Face是通過(guò)四個(gè)當(dāng)前比較流形的基準(zhǔn)——AI2 Reasoning Challenge,HellaSwag,MMLU和TruthfulQA對(duì)這些模型進(jìn)行評(píng)估的。
盡管「Falcon」的論文目前還沒(méi)公開(kāi)發(fā)布,但Falcon 40B已經(jīng)在經(jīng)過(guò)精心篩選的1萬(wàn)億token網(wǎng)絡(luò)數(shù)據(jù)集的上進(jìn)行了大量訓(xùn)練。
研究人員透露,「Falcon」在訓(xùn)練過(guò)程非常重視在大規(guī)模數(shù)據(jù)上實(shí)現(xiàn)高性能的重要性。
我們都知道的是,LLM對(duì)訓(xùn)練數(shù)據(jù)的質(zhì)量非常敏感,這就是為什么研究人員會(huì)花大量的精力構(gòu)建一個(gè)能夠在數(shù)萬(wàn)個(gè)CPU核心上進(jìn)行高效處理的數(shù)據(jù)管道。
目的就是,在過(guò)濾和去重的基礎(chǔ)上從網(wǎng)絡(luò)中提取高質(zhì)量的內(nèi)容。
目前,TII已經(jīng)發(fā)布了精煉的網(wǎng)絡(luò)數(shù)據(jù)集,這是一個(gè)經(jīng)過(guò)精心過(guò)濾和去重的數(shù)據(jù)集。實(shí)踐證明,非常有效。
僅用這個(gè)數(shù)據(jù)集訓(xùn)練的模型可以和其它LLM打個(gè)平手,甚至在性能上超過(guò)他們。這展示出了「Falcon」卓越的質(zhì)量和影響力。

此外,F(xiàn)alcon模型也具有多語(yǔ)言的能力。
它理解英語(yǔ)、德語(yǔ)、西班牙語(yǔ)和法語(yǔ),并且在荷蘭語(yǔ)、意大利語(yǔ)、羅馬尼亞語(yǔ)、葡萄牙語(yǔ)、捷克語(yǔ)、波蘭語(yǔ)和瑞典語(yǔ)等一些歐洲小語(yǔ)種上也懂得不少。
Falcon 40B還是繼H2O.ai模型發(fā)布后,第二個(gè)真正開(kāi)源的模型。然而,由于H2O.ai并未在此排行榜上與其他模型進(jìn)行基準(zhǔn)對(duì)比,所以這兩個(gè)模型還沒(méi)上過(guò)擂臺(tái)。
而回過(guò)頭看LLaMA,盡管它的代碼在GitHub上可以獲取,但它的權(quán)重(weights)從未開(kāi)源。
這意味著該模型的商業(yè)使用受到了一定程度的限制。
而且,LLaMA的所有版本都依賴(lài)于原始的LLaMA許可證,這就使得LLaMA不適合小規(guī)模的商業(yè)應(yīng)用。
在這一點(diǎn)上,「Falcon」又拔得了頭籌。
唯一免費(fèi)的商用大模型!
Falcon是目前唯一的可以免費(fèi)商用的開(kāi)源模型。
在早期,TII要求,商業(yè)用途使用Falcon,如果產(chǎn)生了超過(guò)100萬(wàn)美元以上的可歸因收入,將會(huì)收取10%的「使用稅」。
可是財(cái)大氣粗的中東土豪們沒(méi)過(guò)多長(zhǎng)時(shí)間就取消了這個(gè)限制。
至少到目前為止,所有對(duì)Falcon的商業(yè)化使用和微調(diào)都不會(huì)收取任何費(fèi)用。
土豪們表示,現(xiàn)在暫時(shí)不需要通過(guò)這個(gè)模型掙錢(qián)。

而且,TII還在全球征集商用化方案。
對(duì)于有潛力的科研和商業(yè)化方案,他們還會(huì)提供更多的「訓(xùn)練算力支持」,或者提供進(jìn)一步的商業(yè)化機(jī)會(huì)。

項(xiàng)目提交郵箱:[email protected]
這簡(jiǎn)直就是在說(shuō):只要項(xiàng)目好,模型免費(fèi)用!算力管夠!錢(qián)不夠我們還能給你湊!
對(duì)于初創(chuàng)企業(yè)來(lái)說(shuō),這簡(jiǎn)直就是來(lái)自中東土豪的「AI大模型創(chuàng)業(yè)一站式解決方案」。

高質(zhì)量的訓(xùn)練數(shù)據(jù)
根據(jù)開(kāi)發(fā)團(tuán)隊(duì)稱(chēng),F(xiàn)alconLM 競(jìng)爭(zhēng)優(yōu)勢(shì)的一個(gè)重要方面是訓(xùn)練數(shù)據(jù)的選擇。
研究團(tuán)隊(duì)開(kāi)發(fā)了一個(gè)從公共爬網(wǎng)數(shù)據(jù)集中提取高質(zhì)量數(shù)據(jù)并刪除重復(fù)數(shù)據(jù)的流程。
在徹底清理多余重復(fù)內(nèi)容后,保留了 5 萬(wàn)億的token——足以訓(xùn)練強(qiáng)大的語(yǔ)言模型。
40B的Falcon LM使用1萬(wàn)億個(gè)token進(jìn)行訓(xùn)練, 7B版本的模型訓(xùn)練token達(dá)到 1.5 萬(wàn)億。
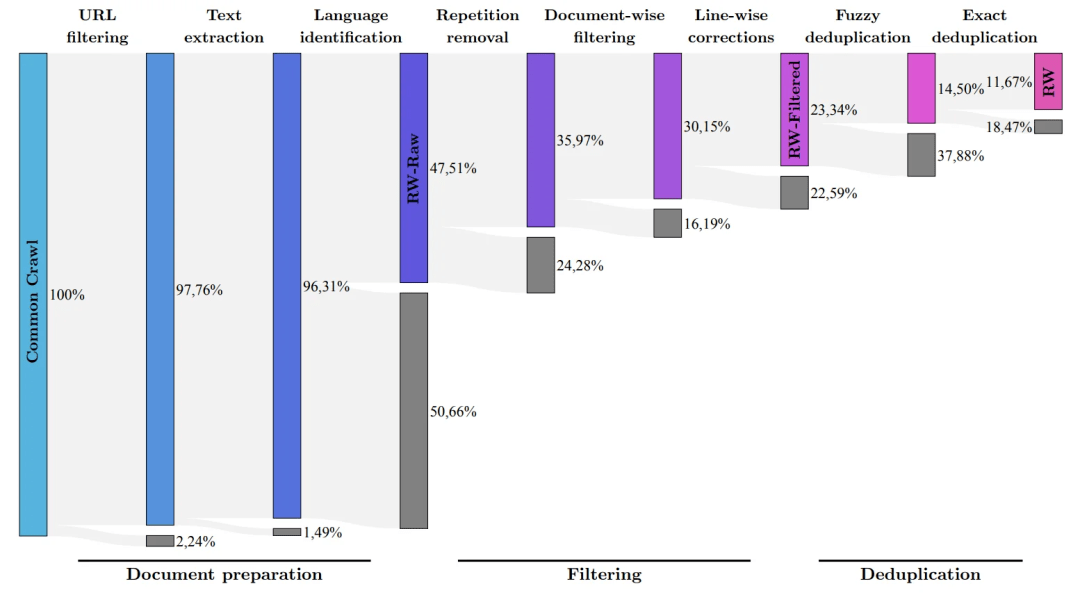
(研究團(tuán)隊(duì)的目標(biāo)是使用RefinedWeb數(shù)據(jù)集從Common Crawl中僅過(guò)濾出質(zhì)量最高的原始數(shù)據(jù))
更加可控的訓(xùn)練成本
TII稱(chēng),與GPT-3相比,F(xiàn)alcon在只使用75%的訓(xùn)練計(jì)算預(yù)算的情況下,就實(shí)現(xiàn)了顯著的性能提升。
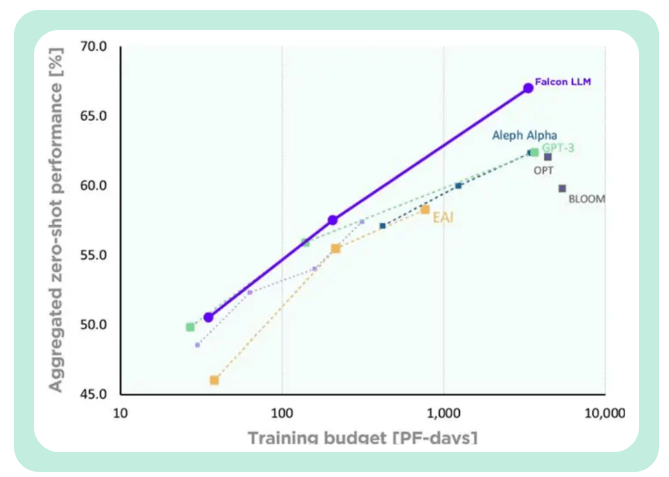
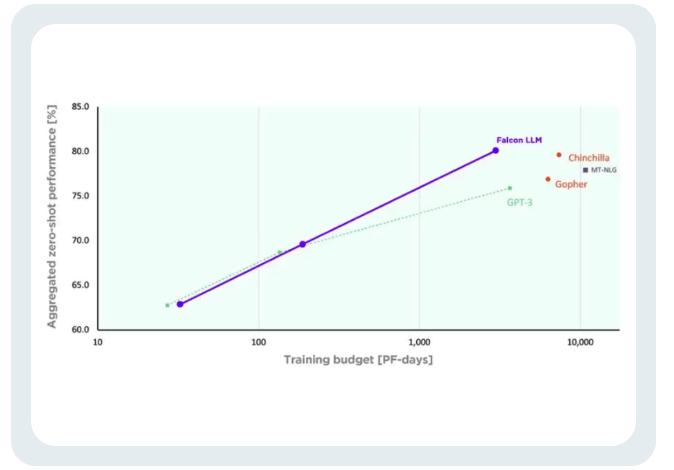
而且在推斷(Inference)時(shí)只需要只需要20%的計(jì)算時(shí)間。
Falcon的訓(xùn)練成本,只相當(dāng)于Chinchilla的40%和PaLM-62B的80% 。
成功實(shí)現(xiàn)了計(jì)算資源的高效利用。
參考資料:
https://analyticsindiamag.com/open-source-ai-has-a-new-champion/





