
作者:人月神話,新浪博客同名
簡介:多年SOA規劃建設,私有云PaaS平臺架構設計經驗,長期從事一線項目實踐
今天準備談下微服務架構和API網關中的限流熔斷,當前可以看到對于Spring Cloud框架本身也提供了Hystrix,主流的開源API網關產品類似Kong網關本身也包括了限流熔斷能力。
當然也有完全較為獨立的限流熔斷開源實現,比如阿里的Sentinel即是我們經常會用到的限流熔斷開源產品,而且可以和Dubbo,SpringCloud等各種微服務框架無縫集成。
由于網上大家能夠搜索到的關于各開源產品實現的限流熔斷功能和使用的文章都很多,因此這篇文章不打算再去介紹這些開源產品,而是從業務場景出發來思考下一個限流熔斷功能實現中的一些思路。當然,對于我們常說的資源定義,線程池隔離,滑動時間窗口計算等內容仍然是相通的。
問題和背景說明
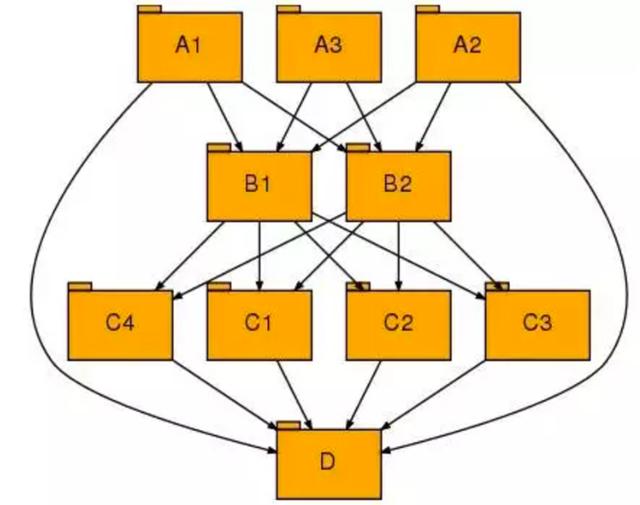
首先我們來看下限流熔斷的出現背景。比如上圖的一個微服務間調用關系,我們用這個圖作為參考來進行一些常見的場景和問題。
某一個API接口服務調用導致整體資源被耗盡
這是一個比較典型的場景,即某一個API接口服務的大并發,大數據量調用導致服務器線程和內存資源的全部耗盡。
對于API接口服務調用,往往并不怕大并發調用,而是怕長耗時和大數據量的調用,這種接口調用導致連接一直被占用,而是大數據量情況下內存資源也一直被占用而服務是否。在這種場景下往往導致線程池滿,或者場景的JVM內存溢出問題,將直接導致整個JVM內存溢出宕機。
即我們常說的單個API服務問題導致所有資源被搶占,而影響到所有API接口調用。
常說的服務調用引發雪崩
在微服務架構下,微服務API接口間相互依賴,形成服務鏈調用關系,如上圖。在這種情況下依賴的API接口服務如果出現問題,那么就會導致上層的各個消費方都出現調用異常,而導致整體服務鏈調用雪崩。
比如上圖里面如果C1出現性能問題,那么將直接導致B1和B2都出現性能問題,而由于B層出現的性能問題又會快速的傳遞到A層,導致A層相關的API接口服務全部出現問題。
通過上面初步分析也可以看到,服務限流熔斷簡單來說就是不要因為單個API接口服務出現的異常或性能問題而影響都整體API網關或微服務架構的運行,犧牲或拒絕一個服務的訪問往往是確保了更多的服務能夠正常被消費和調用。
在梳理清楚以上概念后,我們再回來看下服務限流熔斷本身的概念。
限流熔斷的基本概念
對于限流熔斷,我原來給過一個概念,簡單來說限流就是服務請求調用要排隊,只給你一個線程池總數,超過就等待,即使你瞬間的請求并發再大也需要慢慢進入。而對于熔斷則我們常說的整個服務都處于不可用狀態。
今天我們對這個概念重新進行下說明。如下圖:
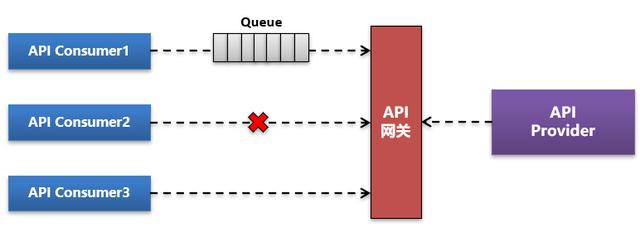
一個API接口有多個Consumer消費方,對于限流更多的是針對消費方+API這個粒度來說的,而對于熔斷則是針對整個API Provider服務來說的。
一個限流策略既可以是讓消費方的服務請求進行排隊,也可以是對觸發某個規則后直接對某個特定的消費方調用進行拒絕,比如上圖僅拒絕Consumer2的調用,而對于其它消費方調用仍然放行。而對于熔斷策略則一定是整個服務全部進行拒絕訪問,注意這種熔斷不一定必須是服務下線或狀態變更,也可以是直接在限流熔斷攔截器上對所有入口請求進行拒絕。
整體實現思路說明
在講具體的實現方案的時候先講下整體的實現思路。
從前面的分析我們也看到,實際上對于限流和熔斷更多的是控制的資源單位和粒度不一樣,因為我們希望的是構建一套算法來滿足對所有的問題場景下的需求。由于服務限流熔斷更多的是需要對服務進行攔截處理,我們也看到限流熔斷器一般都會配合API網關,微服務網關等使用,而不是獨立的存在。
01-對于資源粒度的考慮
在阿里的Sentinel的實現里面有幾個重要的概念,一個是資源,一個是Slot,一個是實現機制中的滑動時間窗口,但是初步看好像無法配置到單個消費方+服務這個層面。
對資源粒度,初步分析應該包括了多個層次,從最粗的資源到最細化的資源,在傳統的資源粒度考慮里面我們往往并不會考慮到某個微服務或業務系統這個粒度,但是如果從API網關的限流熔斷,對API網關本身的性能保護來說,這個還是有必要。
比如用戶中心這個微服務,實際上提供29個API服務接口。
當用戶中心微服務模塊本身出現問題的時候,這29個微服務可能都會出現性能訪問緩慢,那么需要的是對整個用戶中心接入的API服務全部限流和熔斷。
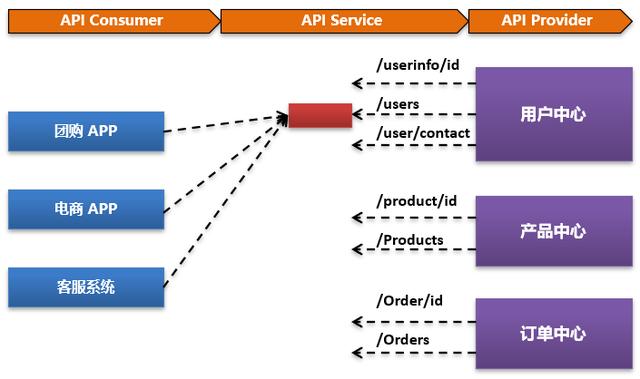
即我們對資源本身的顆粒度進一步細化,從最細粒度到最粗粒度可以分為:
- 最細粒度:API消費方+API服務+API提供方
- 熔斷層:API服務+API提供方
- 熔斷范圍:API提供方(對API服務提供方所有服務進行熔斷)
以上三種粒度才是我們實際進行資源控制的時候需要考慮的內容。
為啥考慮這個問題,搞清楚了資源管控的顆粒度,我們一個方面是要在規則配置的時候支持多種層次的配置,一個方面就是我們實際實時數據計算的時候需要進行顆粒度的考慮。
02-對規則的關鍵說明
要實現限流熔斷,簡單來就是三個方面的內容,一個就是資源,一個是就是規則,一個就是通過計算匯總處理過程。計算過程最終就是來判斷在某一個時間點當前的實際數據是否已經滿足了規則觸發的要求,如果滿足要求就觸發規則進行限流熔斷。
對于規則,首先要考慮維度定義,而維度本身就是API接口服務運行實例的匯總統計數據,那么這些場景的維度包括了:
- API服務運行時長
- API服務單位時間的運行次數
- API服務運行數據量
而這三個基礎維度本身又會進一步產生其它擴展維度,比如我們常說的最大數據量,評價數據量,運行失敗次數,運行成功率,運行最大耗時等。
而對于具體的規則,我們希望最簡單處理,即:
- 某一個指標 大于 或小于 我們預定的某一個閾值,就算規則滿足。
其次就是可以定義復合規則。復合規則也簡單處理為規則的與或處理,即:
- 規則1和規則2同時滿足,就算整體規則滿足
而對于規則本身的作用范圍,我在前面已經講到,即資源本身的不同粒度。規則可以最細化的作用到某一個特定的消費方調用的某一個特定服務,也可以是作用到某個服務所有消費方。
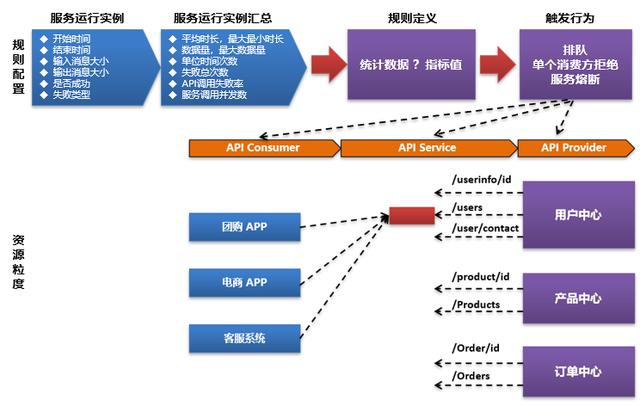
簡單來說就是:規則+資源最終通過計算后觸發限流熔斷行為。
03-對計算邏輯的關鍵說明
在前面我們把規則和資源講清楚后,再來看下具體的計算邏輯思路。
對于計算邏輯,我們可以將計算過程分解為多個獨立的計算單元,然后多個計算單元的組合最終形成了完整的計算和處理邏輯。
大家可以看下,對于Sentinel限流熔斷產品中的Slot概念正是可以理解為我們前面談到的計算單元。Sentinel將各個Slot的能力最終組合在一起完成了一次完整的限流熔斷邏輯處理。
對于計算邏輯,我們還是要回歸到具體的規則配置。
比如,我們配置完成的規則呈現方式可能如下:
- 對于用戶查詢API接口,在5分鐘內調用次數大于1萬次即整體熔斷
- 對于CRM系統消費產品查詢接口,在10分鐘內如果平均時長大于30秒則拒絕CRM訪問
- 對于訂單更新API接口,如果失敗率超過1%則全部熔斷
從上面的描述我們看了單位時間的概念,即當我們去觸發限流熔斷行為的時候,我們不希望是一次偶然的調用并發或異常就馬上觸發,而是希望是我們觀察的一個單位時間段,如果持續發生某種異常行為才觸發。
這個單位時間可以是5分鐘,也是是10分鐘,乃至1個小時。
也就是說我們最終統計的是單位時間的最終匯總統計數據。也就是說對于服務運行實例數據我們需要進行實時采集,采集完成后在基于資源粒度進行分類匯總,形成匯總數據。
那么如何匯總?
如果希望是統計1個小時,難道我們要在內存里面一直存儲一個小時的實例數據,達到了1個小時的單位時間后再進行匯總處理?這個顯然是不合適的。
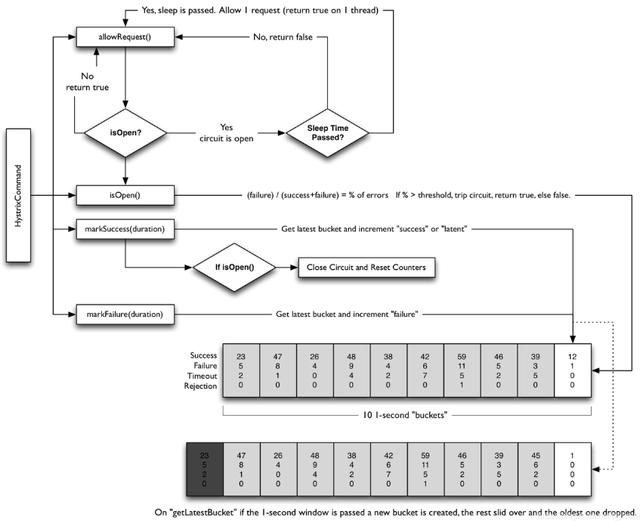
Hystrix滑動窗口計算邏輯
正是這個原因,我們再給出一個最小統計時間間隔概念,比如我們可以設置為10秒,我們先將10秒這個最小時間間隔的實例數據進行一次匯總,然后將第一次匯總后的數據放入到我們的滑動窗口數組里面。然后再基于規則配置,提取滑動窗口中的數據來進行二次匯總處理,最終判斷配置的規則是否觸發限流熔斷操作。
限流熔斷整體實現邏輯
在前面的內容講解完成后,我們再來看下限流熔斷的整體實現邏輯,你可以將這篇文章邏輯看做是當前主流的限流熔斷產品的一個邏輯簡化實現。
當然一方面是簡化,一方面在資源控制顆粒度上反而是本文的方法會更加細化。對于整個限流熔斷的處理邏輯流程,我們可以簡化為下圖:
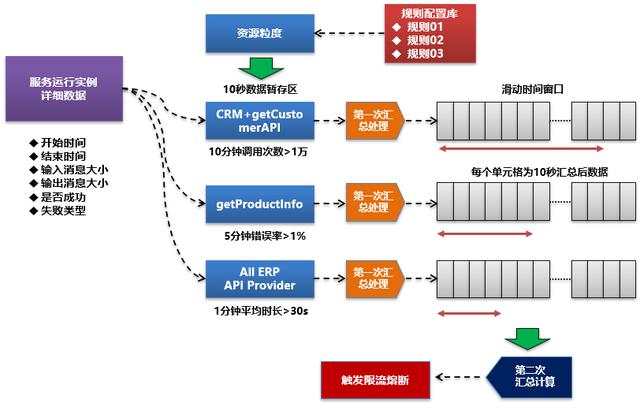
對于該圖,實際可以看到,如果按 Slot計算邏輯單元劃分的思路可以分為:
- 基于配置的規則將服務運行實例按資源顆粒度匹配要求存到實例數據暫存區
- 進行第一次匯總計算
- 將匯總數據推入到滑動時間窗口數組
- 基于規則配置進行二次匯總計算
- 對限流熔斷是否觸發進行判斷和處理
我們再將上面的思路做一個簡單的描述。
比如我們當前在限流熔斷規則配置中配置了三條獨立的規則,不同的資源顆粒度。
- 規則1:對于CRM消費getCustomer接口進行限流,10分鐘調用>1萬即拒絕
- 規則2:對于getProductinfo接口流控,5分鐘錯誤>1%則整體熔斷
- 規則3:對于ERP系統提供所有服務,1分鐘平均時長>30秒則整體熔斷
如果是以上三條獨立的限流熔斷規則,則我們需要配置三個不同的臨時數據存儲區和三個獨立的滑動時間窗口區。
在朝10秒臨時數據暫存區推送臨時數據的時候可能會造成冗余,但是在限流規則本身不帶來配置的情況下該方案反而是最優方案。畢竟在實際應用場景中,我們往往是在發現了明細的性能異常或問題的時候才會配置限流熔斷規則。
比如,CRM系統調用getCustomer API接口。
當獲取到這次實例數據的時候,我們將其推送到第一個緩存集合,如果該接口本身也是ERP系統提供的接口,那么我們會同時將該數據推送一份到ERP系統緩存集合。
對于緩存數據集,我們每10秒就做一次匯總處理。并將匯總完成的結果數據形成一條記錄推送到對應的滑動時間窗口區。在推送完成后將該數據集數據全部清空或進行資源釋放。
基于滑動窗口數據的二次數據處理
對于滑動窗口中的二次數據處理,我們可以在每次數據推送完成后就計算一次滑動窗口數據,比如5分鐘規則,我們就獲取窗口中最近5分鐘的數據進行二次匯總,并判斷二次匯總后的數據是否滿足了相應的觸發條件。
如果滿足條件,就進行限流熔斷處理。
限流熔斷實現邏輯和API網關能力的解耦
最后談下限流熔斷實現和整個API網關能力的解耦。
簡單來說,限流熔斷本身也是一個獨立的攔截器,對服務請求進行攔截,并判斷當前限流熔斷規則是否處于生效狀態,如果處于生效狀態就觸發限流熔斷操作,比如對訪問請求進行拒絕。如果不生效狀態,那么就放行服務請求。
那么整個限流熔斷和API網關的集成關系,我們需要重新梳理如下:
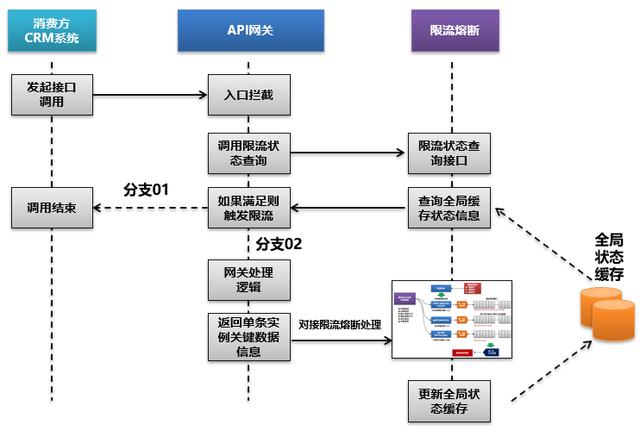
當然在服務本身被熔斷后,我們還可以設置一個解除時間間隔,比如5分鐘或10分鐘,我們還需要設置一個定時任務來進行計算,當解除條件滿足后,將全局狀態緩存中的服務狀態進行刷新,以對服務限流進行解除。
以上即是服務限流熔斷邏輯實現的以下關鍵思考,供參考。





