


全世界都在搶算力,中國大公司更急迫。
文丨張家豪
編輯丨程曼祺 黃俊杰
2022 年下半年,生成式 AI 爆火的同時,硅谷著名風險資本 a16z 走訪了數十家 AI 創業公司和大科技公司。他們發現,創業公司轉手就把 80%-90% 的早期融資款送給了云計算平臺,以訓練自己的模型。他們估算,即便這些公司的產品成熟了,每年也得把 10%-20% 的營收送給云計算公司。相當于一筆 “AI 稅”。
這帶來了在云上提供模型能力和訓練服務,把算力租給其它客戶和創業公司的大市場。僅在國內,現在就至少有數十家創業公司和中小公司在自制復雜大語言模型,他們都得從云計算平臺租 GPU。據 a16z 測算,一個公司一年的 AI 運算開支只有超過 5000 萬美元,才有足夠的規模效應支撐自己批量采購 GPU。
據《晚點 LatePost》了解,今年春節后,擁有云計算業務的中國各互聯網大公司都向英偉達下了大單。字節今年向英偉達訂購了超過 10 億美元的 GPU,另一家大公司的訂單也至少超過 10 億元人民幣。
僅字節一家公司今年的訂單可能已接近英偉達去年在中國銷售的商用 GPU 總和。去年 9 月,美國政府發布對 A100、H100(英偉達最新兩代數據中心商用 GPU) 的出口限制時,英偉達曾回應稱這可能影響去年四季度它在中國市場的 4 億美元(約合 28 億元人民幣)潛在銷售。以此推算,2022 年全年英偉達數據中心 GPU 在中國的銷售額約為 100 億元人民幣。
相比海外巨頭,中國大科技公司采購 GPU 更為急迫。過去兩年的降本增效中,一些云計算平臺減少了 GPU 采購,儲備不足。此外,誰也不敢保證,今天能買的高性能 GPU,明天會不會就受到新的限制。
從砍單到加購,同時內部騰挪
今年初之前,中國大型科技公司對 GPU 的需求還不溫不火。
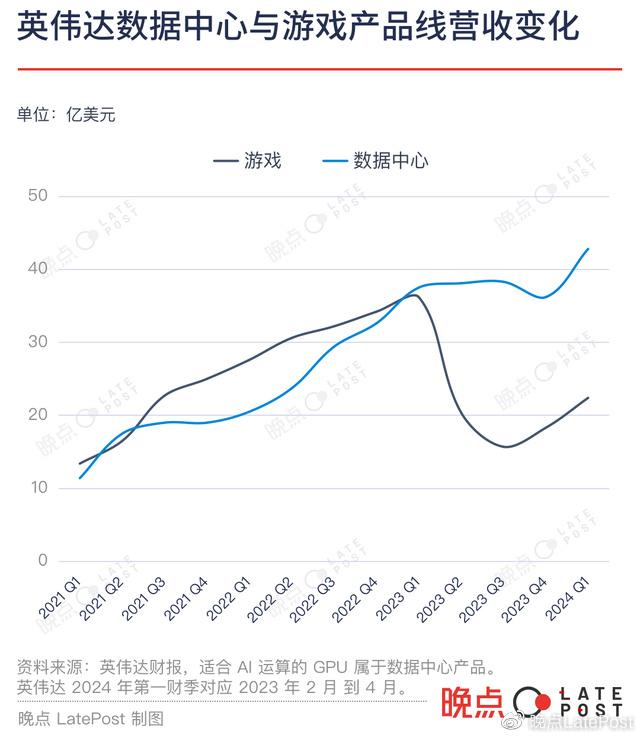
GPU 在中國大型互聯網科技公司中主要有兩個用途:一是對內支持業務和做一些前沿 AI 研究,二是把 GPU 放到云計算平臺上對外售賣。
一名字節人士告訴《晚點 LatePost》,2020 年 6 月 OpenAI 發布 GPT-3 后,字節就曾訓練了一個數十億參數的生成式語言大模型,當時主要使用的 GPU 是 A100 前代產品 V100。由于參數規模有限,這個模型生成能力一般,字節當時看不到它的商業化可能性,“ROI(投資回報率) 算不過來”,這次嘗試不了了之。
阿里也曾在 2018-2019 年積極采購 GPU。一位阿里云人士稱,當時阿里的采購量至少達到上萬塊規模,購買的型號主要是 V100 和英偉達更早前發布的 T4。不過這批 GPU 中只有約十分之一給到了達摩院用作 AI 技術研發。2021 年發布萬億參數大模型 M6 后,達摩院曾披露訓練 M6 使用了 480 塊 V100。
阿里當時購買的 GPU,更多給到了阿里云用于對外租賃。但包括阿里云在內,一批中國云計算公司都高估了中國市場的 AI 需求。一位科技投資人稱,大模型熱潮之前,國內主要云廠商上的 GPU 算力不是緊缺,而是愁賣,云廠商甚至得降價賣資源。去年阿里云先后降價 6 次,GPU 租用價下降超兩成。
在降本增效,追求 “有質量的增長” 與利潤的背景下,據了解,阿里在 2020 年之后收縮了 GPU 采購規模,騰訊也在去年底砍單一批英偉達 GPU。
然而沒過多久后的 2022 年初,ChatGPT 改變了所有人的看法,共識很快達成:大模型是不容錯過的大機會。
各公司創始人親自關注大模型進展:字節跳動創始人張一鳴開始看人工智能論文;阿里巴巴董事局主席張勇接手阿里云,在阿里云峰會發布阿里大模型進展時稱,“所有行業、應用、軟件、服務,都值得基于大模型能力重做一遍”。
一名字節人士稱,過去在字節內部申請采購 GPU 時,要說明投入產出比、業務優先級和重要性。而現在大模型業務是公司戰略級別新業務,暫時算不清 ROI 也必須投入。
研發自己的通用大模型只是第一步,各公司的更大目標是推出提供大模型能力的云服務,這是真正可以匹配投入的大市場。
微軟的云服務 Azure 在中國云計算市場本沒有太強存在感,入華十年來主要服務跨國公司的中國業務。但現在客戶得排隊等待,因為它是 OpenAI 商業化的唯一云代理商。
阿里在 4 月的云峰會上,再次強調 MaaS(模型即服務)是未來云計算趨勢,在開放自研的通用基礎模型 “通義千問” 測試之外,還發布了一系列幫助客戶在云上訓練、使用大模型的工具。不久后騰訊和字節火山引擎也先后發布自己的新版訓練集群服務。騰訊稱用新一代集群訓練萬億參數的混元大模型,時間可被壓縮到 4 天;字節稱它們的新集群支持萬卡級大模型訓練,國內數十家做大模型的企業,多數已在使用火山引擎。
所有這些平臺使用的要么是英偉達 A100、H100 GPU,要么是去年禁令后英偉達專門推出的減配版 A800、H800,這兩款處理器帶寬分別是原版的約 3/4 和約一半,避開了高性能 GPU 的限制標準。
圍繞 H800 和 A800,中國科技大公司開始了新一輪下單競爭。
一名云廠商人士稱,字節、阿里等大公司主要是和英偉達原廠直接談采購,代理商和二手市場難以滿足他們的龐大需求。
英偉達會按目錄價,根據采購規模談一個折扣。據英偉達官網,A100 售價為 1 萬美元 / 枚(約 7.1 萬元人民幣),H100 售價為 3.6 萬美元 / 枚(約 25.7 萬元人民幣);據了解,A800 和 H800 售價略低于原版。
中國公司能否搶到卡,更多是看商業關系,比如以往是不是英偉達的大客戶。“你是和中國英偉達談,還是去美國找老黃(黃仁勛,英偉達創始人、CEO)直接談,都有差別。” 一位云廠商人士說。
部分公司也會和英偉達進行 “業務合作”,在購買搶手的數據中心 GPU 時,也購買其它產品,以爭取優先供應。這就像愛馬仕的配貨,如果你想買到熱門的包,往往也得搭配幾萬元的衣服、鞋履。
綜合我們獲得的行業信息,字節今年的新下單動作相對激進,超過 10 億美元級別。
一位接近英偉達的人士稱,字節到貨和沒到貨的 A100 與 H800 總計有 10 萬塊。其中 H800 今年 3 月才開始投產,這部分芯片應來自今年的加購。據了解,以現在的排產進度,部分 H800 要到今年底才能交貨。
字節跳動 2017 年開始建設自己的數據中心。曾經的數據中心更依賴適應所有計算的 CPU,直到 2020 年,字節采購英特爾 CPU 的金額還高于英偉達 GPU。字節采購量的變化,也反映了如今大型科技公司的計算需求中,智能計算對通用計算的趕超。
據了解,某互聯網大廠今年至少已給英偉達下了萬卡級別訂單,按目錄價估算價值超 10 億元人民幣。
騰訊則率先宣布已用上 H800,騰訊云在今年 3 月發布的新版高性能計算服務中已使用了 H800,并稱這是國內首發。目前這一服務已對企業客戶開放測試申請,這快于大部分中國公司的進度。
據了解,阿里云也在今年 5 月對內提出把 “智算戰役” 作為今年的頭號戰役,并設立三大目標:機器規模、客戶規模和營收規模;其中機器規模的重要指標就是 GPU 數量。
新的 GPU 到貨前,各公司也在通過內部騰挪,優先支持大模型研發。
能一次釋放較多資源的做法是砍掉一些沒那么重要,或短期看不到明確前景的方向。“大公司有好多半死不活的業務占著資源。” 一位互聯網大公司 AI 從業者說。
今年 5 月,阿里達摩院裁撤自動駕駛實驗室:300 多名員工中,約 1/3 劃歸菜鳥技術團隊,其余被裁,達摩院不再保留自動駕駛業務。研發自動駕駛也需要用高性能 GPU 做訓練。這一調整可能與大模型無直接關系,但確實讓阿里獲得了一批 “自由 GPU”。
字節和美團,則直接從給公司帶來廣告收入的商業化技術團隊那里勻 GPU。
據《晚點 LatePost》了解,今年春節后不久,字節把一批原計劃新增給字節商業化技術團隊的 A100 勻給了 TikTok 產品技術負責人朱文佳。朱文佳正在領導字節大模型研發。而商業化技術團隊是支持抖音廣告推薦算法的核心業務部門。
美團在今年一季度左右開始開發大模型。據了解,美團不久前從多個部門調走了一批 80G 顯存頂配版 A100,優先供給大模型,讓這些部門改用配置更低的 GPU。
財力遠不如大平臺充裕的 B 站對大模型也有規劃。據了解,B 站此前已儲備了數百塊 GPU。今年,B 站一方面持續加購 GPU,一方面也在協調各部門勻卡給大模型。“有的部門給 10 張,有的部門給 20 張。” 一位接近 B 站的人士稱。
字節、美團、B 站等互聯網公司,原本支持搜索、推薦的技術部門一般會有一些 GPU 資源冗余,在不傷害原有業務的前提下,他們現在都在 “把算力水份擠出來”。
不過這種拆東補西的做法能獲得的 GPU 數量有限,訓練大模型所需的大頭 GPU 還是得靠各公司過去的積累和等待新 GPU 到貨。
全世界都在搶算力
對英偉達數據中心 GPU 的競賽也發生在全球范圍。不過海外巨頭大量購買 GPU 更早,采購量更大,近年的投資相對連續。
2022 年,META 和甲骨文就已有對 A100 的大投入。Meta 在去年 1 月與英偉達合作建成 RSC 超級計算集群,它包含 1.6 萬塊 A100。同年 11 月,甲骨文宣布購買數萬塊 A100 和 H100 搭建新計算中心。現在該計算中心已部署了超 3.27 萬塊 A100,并陸續上線新的 H100。
微軟自從 2019 年第一次投資 OpenAI 以來,已為 OpenAI 提供數萬塊 GPU。今年 3 月,微軟又宣布已幫助 OpenAI 建設了一個新計算中心,其中包括數萬塊 A100。google 在今年 5 月推出了一個擁有 2.6 萬塊 H100 的計算集群 Compute Engine A3,服務想自己訓練大模型的公司。
中國大公司現在的動作和心態都比海外巨頭更急迫。以百度為例,它今年向英偉達新下的 GPU 訂單高達上萬塊。數量級與 Google 等公司相當,雖然百度的體量小得多,其去年營收為 1236 億元人民幣,只有 Google 的 6%。
據了解,字節、騰訊、阿里、百度這四家中國投入 AI 和云計算最多的科技公司,過去 A100 的積累都達到上萬塊。其中字節的 A100 絕對數最多。不算今年的新增訂單,字節 A100 和前代產品 V100 總數接近 10 萬塊。
成長期公司中,商湯今年也宣稱,其 “AI 大裝置” 計算集群中已總共部署了 2.7 萬塊 GPU,其中有 1 萬塊 A100。連看似和 AI 不搭邊的量化投資公司幻方之前也購買了 1 萬塊 A100。
僅看總數,這些 GPU 供各公司訓練大模型似乎綽綽有余——據英偉達官網案例,OpenAI 訓練 1750 億參數的 GPT-3 時用了 1 萬塊 V100 ,訓練時長未公開;英偉達測算,如果用 A100 來訓練 GPT-3 ,需要 1024 塊 A100 訓練 1 個月,A100 相比 V100 有 4.3 倍性能提升。但中國大公司過去采購的大量 GPU 要支撐現有業務,或放在云計算平臺上售賣,并不能自由地用于大模型開發和對外支持客戶的大模型需求。
這也解釋了中國 AI 從業者對算力資源估算的巨大差別。清華智能產業研究院院長張亞勤 4 月底參加清華論壇時說,“如果把中國的算力加一塊,相當于 50 萬塊 A100,訓練五個模型沒問題。”AI 公司曠視科技 CEO 印奇接受《財新》采訪時則說:中國目前可用作大模型訓練的 A100 總共只有約 4 萬塊。
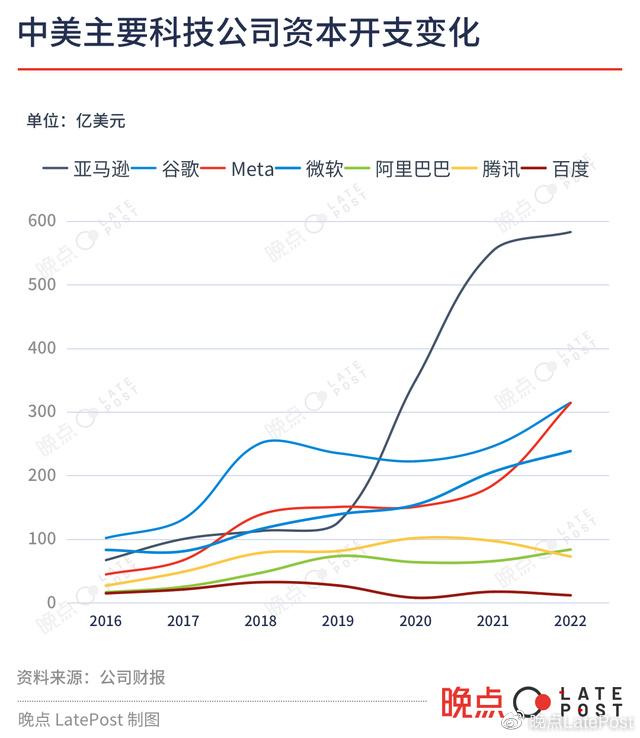
主要反映對芯片、服務器和數據中心等固定資產投資的資本開支,可以直觀說明中外大公司計算資源的數量級差距。
最早開始測試類 ChatGPT 產品的百度,2020 年以來的年資本開支在 8 億到 20 億美元之間,阿里在 60-80 億美元之間,騰訊在 70-110 億美元之間。同期,亞馬遜、Meta、Google、微軟這四家自建數據中心的美國科技公司的年資本開支最少均超過 150 億美元。
疫情三年中,海外公司資本開支繼續上漲。亞馬遜去年的資本開支已來到 580 億美元,Meta、Google 均為 314 億美元,微軟接近 240 億美元。中國公司的投資在 2021 年之后則在收縮。騰訊、百度去年的資本開支均同比下滑超 25%。
訓練大模型的 GPU 已不算充足,各家中國公司如果真的要長期投入大模型,并賺到給其它模型需求 “賣鏟子” 的錢,未來還需要持續增加 GPU 資源。
走得更快 OpenAI 已遇到了這一挑戰。5 月中旬,OpenAI CEO SamAltman 在與一群開發者的小范圍交流中說,由于 GPU 不夠,OpenAI 現在的 API 服務不夠穩定,速度也不夠快,在有更多 GPU 前,GPT-4 的多模態能力還無法拓展給每個用戶,他們近期也不準備發布新的消費級產品。技術咨詢機構 TrendForce 今年 6 月發布報告稱,OpenAI 需要約 3 萬塊 A100 來持續優化和商業化 ChatGPT。
與 OpenAI 合作頗深的微軟也面臨類似情境:今年 5 月,有用戶吐槽 New Bing 回答速度變慢,微軟回應,這是因為 GPU 補充速度跟不上用戶增長速度。嵌入了大模型能力的微軟 office 365 Copilot 目前也沒有大規模開放,最新數字是有 600 多家企業在試用——Office 365 的全球總用戶數接近 3 億。
中國大公司如果不是僅把訓練并發布一個大模型作為目標,而是真想用大模型創造服務更多用戶的產品,并進一步支持其它客戶在云上訓練更多大模型,就需要提前儲備更多 GPU。
為什么只能是那四款卡?
在 AI 大模型訓練上,現在 A100、H100 及其特供中國的減配版 A800、H800 找不到替代品。據量化對沖基金 Khaveen Investments 測算,英偉達數據中心 GPU 2022 年市占率達 88%,AMD 和英特爾瓜分剩下的部分。

2020 年的 GTC 大會上,黃仁勛攜 A100 第一次亮相。
英偉達 GPU 目前的不可替代性,源自大模型的訓練機制,其核心步驟是預訓練(pre-training)和微調(fine-tuning),前者是打基座,相當于接受通識教育至大學畢業;后者則是針對具體場景和任務做優化,以提升工作表現。
預訓練環節尤其消耗算力,它對單個 GPU 的性能和多卡間的數據傳輸能力有極高要求。
現在只有 A100、H100 能提供預訓練所需的計算效率,它們看起來昂貴,反倒是最低廉的選擇。今天 AI 還在商用早期,成本直接影響一個服務是否可用。
過去的一些模型,如能識別貓是貓的 VGG16,參數量只有 1.3 億,當時一些公司會用玩游戲的 RTX 系列消費級顯卡來跑 AI 模型。而兩年多前發布的 GPT-3 的參數規模已達到 1750 億。
大模型的龐大計算需求下,用更多低性能 GPU 共同組成算力已行不通了。因為使用多個 GPU 訓練時,需要在芯片與芯片間傳輸數據、同步參數信息,這時部分 GPU 會閑置,無法一直飽和工作。所以單卡性能越低,使用的卡越多,算力損耗就越大。OpenAI 用 1 萬塊 V100 訓練 GPT-3 時的算力利用率不到 50%。
A100 、H100 則既有單卡高算力,又有提升卡間數據傳輸的高帶寬。A100 的 FP32(指用 4 字節進行編碼存儲的計算)算力達到 19.5 TFLOPS(1 TFLOPS 即每秒進行一萬億次浮點運算),H100 的 FP32 算力更高達 134 TFLOPS,是競品 AMD MI250 的約 4 倍。
A100、H100 還提供高效數據傳輸能力,盡可能減少算力閑置。英偉達的獨家秘籍是自 2014 年起陸續推出的 NVLink、NVSwitch 等通信協議技術。用在 H100 上的第四代 NVLink 可將同一服務器內的 GPU 雙向通信帶寬提升至 900 GB/s(每秒傳輸 900GB 數據),是最新一代 PCle(一種點對點高速串行傳輸標準)的 7 倍多。
去年美國商務部對 GPU 的出口規定也正是卡在算力和帶寬這兩條線上:算力上線為 4800 TOPS,帶寬上線為 600 GB/s。
A800 和 H800 算力和原版相當,但帶寬打折。A800 的帶寬從 A100 的 600GB/s 降為 400GB/s,H800 的具體參數尚未公開,據彭博社報道,它的帶寬只有 H100(900 GB/s) 的約一半,執行同樣的 AI 任務時,H800 會比 H100 多花 10% -30% 的時間。一名 AI 工程師推測,H800 的訓練效果可能還不如 A100,但更貴。
即使如此,A800 和 H800 的性能依然超過其他大公司和創業公司的同類產品。受限于性能和更專用的架構,各公司推出的 AI 芯片或 GPU 芯片,現在主要用來做 AI 推理,難以勝任大模型預訓練。簡單來說,AI 訓練是做出模型,AI 推理是使用模型,訓練對芯片性能要求更高。
性能差距外,英偉達的更深護城河是軟件生態。
早在 2006 年,英偉達就推出計算平臺 CUDA,它是一個并行計算軟件引擎,開發者可使用 CUDA 更高效地進行 AI 訓練和推理,用好 GPU 算力。CUDA 今天已成為 AI 基礎設施,主流的 AI 框架、庫、工具都以 CUDA 為基礎進行開發。
英偉達之外的 GPU 和 AI 芯片如要接入 CUDA,需要自己提供適配軟件,但只有 CUDA 部分性能,更新迭代也更慢。PyTorch 等 AI 框架正試圖打破 CUDA 的軟件生態壟斷,提供更多軟件能力以支持其它廠商的 GPU,但這對開發者吸引力有限。
一位 AI 從業者稱,他所在的公司曾接觸一家非英偉達 GPU 廠商,對方的芯片和服務報價比英偉達更低,也承諾提供更及時的服務,但他們判斷,使用其它 GPU 的整體訓練和開發成本會高于英偉達,還得承擔結果的不確定性和花更多時間。
“雖然 A100 價格貴,但其實用起來是最便宜的。” 他說。對有意抓住大模型機會的大型科技公司和頭部創業公司來說,錢往往不是問題,時間才是更寶貴的資源。
短期內,唯一影響英偉達數據中心 GPU 銷量的可能只有臺積電的產能。
H100/800 為 4 nm 制程,A100/800 為 7 nm 制程,這四款芯片均由臺積電代工生產。據中國臺灣媒體報道,英偉達今年向臺積電新增了 1 萬片數據中心 GPU 訂單,并下了超急件 ,生產時間最多可縮短 50%。正常情況下,臺積電生產 A100 需要數月。目前的生產瓶頸主要在先進封裝產能不夠,缺口達一至兩成,需要 3-6 個月逐步提升。
自從適用于并行計算的 GPU 被引入深度學習,十多年來,AI 發展的動力就是硬件與軟件,GPU 算力與模型和算法的交疊向前:模型發展拉動算力需求;算力增長,又使原本難以企及的更大規模訓練成為可能。
在上一波以圖像識別為代表的深度學習熱潮中,中國 AI 軟件能力比肩全球最前沿水平;算力是目前的難點——設計與制造芯片需要更長的積累,涉及漫長供應鏈和浩繁專利壁壘。
大模型是模型與算法層的又一次大進展,沒時間慢慢來了,想做大模型,或提供大模型云計算能力的公司必須盡快獲得足夠多的先進算力。在這輪熱潮使第一批公司振奮或失望前,圍繞 GPU 的搶奪不會停止。





