
AI時代來臨,以ChatGPT為代表的新興AI應用帶動了算力需求呈“爆炸式”增長。
本刊特約作者 李赟/文
算力是數字經濟發展的重要底座。隨著AI與數字經濟的發展,算力規模不斷擴大,需求持續攀升。
4月5日,OpenAI停止了ChatGPT Plus的銷售,官網中給出的理由為“由于需求量過大,我們暫停升級服務”。ChatGPT Plus是OpenAI提供的一項訂閱服務,使用價格為20美元/月。訂閱ChatGPT Plus服務的會員可享受三個福利:在高峰時代可以訪問ChatGPT、更快速的響應以及優先訪問新功能。
AI進入“大模型”時代。OpenAI自發布GPT1.0模型之后,一直在持續迭代,陸續發布GPT2.0、GPT3.0和GPT3.5,近期發布GPT4.0是其持續投入AI大模型的必然階段。相比前幾個模型,GPT-4的參數量更大,模型迭代時間更長,也能夠給出更準確的結果。新版本的發布是大模型循序漸進發展的必然成果,未來大模型將成為AI開發范式。
東方證券認為,此次ChatGPT Plus停售事件是因為需求量過大,計算資源供不應求。AI浪潮來襲,智能算力需求將快速提升,AI芯片、AI服務器以及云計算算力需求將持續提升。ChatGPT的訓練需要上萬片英偉達的GPU。同時,在推理端,微軟已經在Azure的六十多個數據中心中部署了幾十萬張GPU,為ChatGPT的超高訪問量提供支持。然而,還是似乎因為計算資源供不應求導致此次ChatGPT Plus停售。
AI浪潮來襲,通用大模型的訓練、行業大模型的訓練、基于通用大模型的行業應用以及推理皆需要大量智能算力提供支持。AI芯片、AI服務器以及云計算算力需求將持續提升。
事實上,算力作為數字經濟的核心生產力,已成為國民經濟發展的重要基礎設施,中國智能算力規模正在高速增長。
IDC預測,2022年中國智能算力規模將達到268.0 EFLOPS(每秒百億億次浮點運算),超過通用算力規模,預計到2026年智能算力規模將達到1271.4 EFLOPS。2021-2026年,預計中國智能算力規模年復合增長率達52.3%,同期通用算力規模年復合增長率為18.5%。華為更是預測,未來10年人工智能算力需求將會增長500倍以上!
未來算力網絡一定會成為國家經濟發展的一個新的基礎設施,根據國家信息中心聯合浪潮信息發布的《智能計算中心創新發展指南》顯示,目前全國已有超過30個城市在建或籌建智算中心。近日,科技部也表態推動算力網建設,打造超算、智算的算力底座。日前,貴州省大數據發展管理局發布《關于印發面向全國的算力保障基地建設規劃的通知》。從能力指標、質量指標、結構指標、通道指標、產業指標共5個維度提出未來三年的建設目標。5大指標均為爆發式擴張,其中機架規模從10.8萬架提高到80萬架,三年時間擴張達7倍;算力總規模從0.81 EFLOPS提高至10 EFLOPS,擴張超11倍。
同時,AI計算需要多元異構算力提供支持,將極大拉動GPGPU、AISC等AI芯片的需求。中國AI芯片市場規模有望快速增長,據艾瑞咨詢預測2027年將達到2164億元,國內相關企業堅持迭代升級,其產品性能日益提升,有望獲得更多市場份額,實現國產替代。另外,隨著大模型的成熟部署,對性能要求稍低的推理芯片的占比將日益提升,也有益于國產AI芯片占比提升。
“智能革命”的起點
回顧歷史,人類社會目前經歷了三次重大的產業變革:蒸汽時代、電氣時代、信息時代,其分別對應了18世紀60年代末期英國人詹姆斯·瓦特制造的第一代具有實用價值的蒸汽機、美國在19世紀60年代實現了電力的廣泛應用以及電燈被發明、1946年美國制造出人類第一臺二進制計算機。每一次的產業革命都具有幾個共通點,首先均有標志性的產品面世,其次持續時間較長以及對于世界發展影響深遠。
如今,人類社會或已處在人工智能時代的臨門一腳。2022年11月,ChatGPT的發布讓世界看到了無限的可能性,這僅僅只是“智能革命”的起點,未來或將呈現出各行業各接納人工智能,人工智能助推世界發展的景象。
自2022年11月底以來,美國初創公司OpenAI發布的人工智能對話聊天機器人軟件(模型)ChatGPT迅速在社交媒體上走紅,短短5天,注冊用戶數就超過100萬,并在2個月內突破1億,成為史上增長最快的消費類應用。
以ChatGPT為代表的AI大模型開啟了新一輪生產力革新的科技浪潮,大模型展現出了理解人類語言的潛力,顛覆過去互聯網發展中的許多業態,并對實體經濟和產業發展產生深遠的影響。也因此,GPT被微軟創始人比爾·蓋茨評價為自圖形界面以來最重要的技術進步,被英偉達創始人黃仁勛稱作是人工智能領域的iphone時刻。
ChatGPT使得人與機器可以直接對話,機器能夠理解人復雜的意圖并能夠做出恰當的反應,人與機器不再局限于簡單的指令式交互,可以流利地與機器對話,進行復雜的交互。機器可以理解人復雜的意圖,輔助人類干更多的工作,人類生產力將會大幅提高,個人AI時代即將到來。從歷史經驗來看,新一輪交互革命引發的浪潮高度與速度都會遠超上一代,目前個人AI時代仍處于萌芽狀態,未來給人類社會帶來的改變不可估量。
同時,ChatGPT也引發了國內外大廠爭相布局,海外方面微軟、谷歌、亞馬遜等大廠均采取投資或商用的方式與OpenAI保持緊密合作,國內方面騰訊、科大訊飛、京東等公司先后宣布與ChatGPT結合上線的業務線,百度、阿里巴巴、昆侖萬維已發或籌備類ChatGPT產品。
國外方面,Meta于近日發布圖像分割基礎模型SAM(Segment Anything Model)。SAM模型能夠在未經過同類數據訓練的情況下,自動分割圖像中的所有內容,自動根據提示詞進行圖像分割。
SAM的發布堪稱圖像識別行業的“GPT-3”時刻。國盛證券表示,圖像識別與分割是當前許多智能化場景的基礎。例如智能駕駛中就需要對攝像頭呈現出的圖像進行分割與識別,從而讓車輛做出反應。醫學影像診斷中需要對病變位置進行分割來進行判斷。過去,圖像分割往往只能通過對預先打包的數據進行訓練,并針對海量的特定場景進行調優,效率和成本均不占優。此次Meta發布的SAM模型,能使得AI通過已有數據的訓練,獲得面對未知內容的自動識別能力。
國盛證券認為,可以把這個過程比作人類的視覺,人類所擁有看見新事物時自動處理并理解的能力。這將改變傳統的圖像識別訓練模式,加快圖像識別行業的發展。
視覺大模型,算力要先行。相較于傳統的圖像識別解決方案,SAM更加偏向于LLM模型(大型語言模型)的模式,即通過海量的預先訓練與擴大模型參數,來使得模型獲得自主識別和學習能力,最終實現圖像“AGI”。這類模式對于算力基礎設施的需求程度遠大于傳統的小模型或者垂直模型,同時圖像模型包含的數據量更大,訓練過程中需要的計算能力,通信能力和存儲能力相較于文字模型更多。因此,視覺大模型的前提是海量的算力基建,算力的重要性在LLM模式邁入圖像領域時被再度提升。
國內方面,以百度為代表的科技公司主導國內AI基礎生態是大勢所趨。在這一生態下,一批基于大模型底座進行應用開發的公司將在文字、圖像、音視頻生成、數字人、3D生成等領域大顯身手,“AI+”應用端有望呈現百花齊放。
4月10日,商湯科技發布“日日新”大模型體系,含自然語言生成、照片生成服務、感知模型預標注、模型研發。1800億參數中文語言大模型應用平臺“商量”支持超長文本知識理解,支持問答、理解與生成等中文語言能力。
而商湯科技下一代軟件開發范式是AI for AI,代碼=80% AI生成+20%人工。超10億參數自研文生圖生成模型“秒畫”,支持二次元等多種生成風格。單卡A100支持,2秒生成1張512K分辨率的圖片。用戶可基于單卡A100自訓練。基于平臺發布的模型,可設置to B服務API(應用程序編程接口),結合商湯大算力對外提供服務。
數據、算力與算法是人工智能時代的三大基石,三者相互促進帶動AI+應用快速落地,大語言模型在豐富的場景中帶動AIGC類應用全面發展,開啟了新一輪人工智能創新周期,將帶動算力、服務器、通信等多領域的發展。
算力需求黃金時代
AI奇點的到來也將會成就算力領域的黃金時代。
算力是指計算機系統能夠完成的計算任務量,通常用來描述計算機的處理能力。算力的單位通常采用FLOPS(Floating Point Operations Per Second)表示每秒鐘能夠完成的浮點運算或指令數。以英偉達在2020年發布的A100產品為例,根據英偉達官方介紹,A100的理論浮點運算性能可以達到19.5 TFLOPS,即每秒195萬億次浮點運算。
算力可分為通用算力、智能算力以及超算算力,對應著三種計算模式:基礎計算、智能計算以及超級計算。不同的場景所需的算力種類不同,其對應的計算精度也不盡相同。
AI大模型是“大數據+大算力+強算法”結合的產物,凝聚了大數據內在精華的“隱式知識庫”,希望邏輯結構能夠自發地從模型的訓練過程中涌現。AI大模型包含了“預訓練”和“大模型”兩層含義,即模型在大規模數據集上完成了預訓練后形成特征和規則,無需或僅需要少量數據的微調,就能直接支撐各類應用。
人工智能實現方法之一為機器學習,而深度學習是用來實現機器學習的技術,通常可分為“訓練”和“推理”兩個階段。訓練階段:需要基于大量的數據來調整和優化人工智能模型的參數,使模型的準確度達到預期,核心在于算力;推理階段:訓練結束后,建立的人工智能模型相可用于推理或預測待處理輸入數據對應的輸出(例如給定一張圖片,識別該圖片中的物體),這個過程為推理階段,對單個任務的計算能力不及訓練,但總計算量也相當可觀。
比于傳統AI算法,大模型在參數規模上得到大幅提升,參數一般達到千億甚至萬億規模。例如OpenAI的GPT系列,最開始的GPT-1擁有1.17億個參數,到GPT-3的參數已經到達1750億個,而相應的能力也得到大幅提升。
GPT-3開啟了大模型時代。GPT-3使用了大量的語料庫進行預訓練,使其能夠理解語言的規則和模式,并生成與輸入文本相關的自然語言文本,GPT-3的主要特點是它具有大規模的預訓練模型,而同時大規模的訓練模型與之對應的便是龐大的算力需求。
根據OpenAI團隊成員2020年發表的論文《Language Models are Few-Shot Learners》,GPT-3模型擁有約1750億個參數,這使得GPT-3擁有其他較少參考量模型來說更高的準確性。同時基于1750億個參數的模型僅需少量的樣本訓練,就能夠接近于BETR模型使用大量樣本訓練后的效果。
大模型無論在性能還是在學習能力上,相較于其他模型都具備明顯優勢,未來或將成為行業趨勢。伴隨大模型的明顯優勢,與之而來的則是對于算力要求的顯著提升。以GPT-3為例,如果以英偉達旗艦級GPU產品A100對其進行訓練,1024塊A100卡需要耗費超過1個月(大于30天),按比例可以計算出,如果需要單日完成訓練,需要的A100數量則將超過30000塊。
OpenAl的數據也顯示,從2012年到2020年,其算力消耗平均每3.4個月就翻倍一次,8年間算力增長了30萬倍。OpenAI首席執行官Sam Altman接受公開采訪表示,GTP-4參數量為GTP-3的20倍,需要的計算量為GTP-3的10倍;GTP-5在2024年底至2025年發布,它的參數量為GTP-3的100倍,需要的計算量為GTP-3的200-400倍。
此外,AI時代算力的增長也遠遠超過了摩爾定律每18個月翻番的速率,根據中國信息通信研究院的估算,2021年全球超算算力規模大約為14EFLOPS,預測到2030年全球超算算力將達到0.2ZFLOPS,平均年增速超過34%。
而ChatGPT僅僅是AI大規模應用的開始,更多的AI應用尚在路上,海量的數據將會產生且非結構化數據居多,這些數據需要更大帶寬的網絡設備進行傳輸,更多的AI算力進行處理。
AI滲透千行百業,拉動智能算力規模高速增長。2022年,各行各業的AI應用滲透度都呈不斷加深的態勢,尤其是在金融、電信、制造以及醫療領域,為實現業務增長、保持強大競爭力、從而占據更大的市場份額,企業紛紛入局AI領域,通過新技術提升傳統業務用戶體驗,人工智能應用增長迅速。
據IDC和浪潮信息聯合發布的《2022-2023中國人工智能計算力發展評估報告》,預計到2023年年底,中國將有50%的制造業供應鏈環節采用人工智能技術實現業務體驗提升。在未來,隨著AI技術對傳統行業賦能作用日益凸顯,催生出更大智算需求成為必然。
顯然,算力已成為數字化時代的關鍵生產要素。越來越多的國家會認識到算力對宏觀經濟的重要性,算力資本與物質資本形成互補效應,共同促進GDP增長,算力勢必會成為各國未來主要的角逐點。
隨著全球數字化進程的全面開啟,算力作為重要支持,賦能作用已經有所顯現。《2021-2022全球計算力指數評估報告》的評估結果顯示,15個重點國家的計算力指數平均每提高1點,國家的數字經濟和GDP將分別增長3.5‰和1.8‰,并預計該趨勢在2021-2025年將繼續保持。
隨著全球數字化進程的推進,云計算、人工智能、無人駕駛、AR/VR等新興數字科技產業蓬勃發展,全球數據總量呈現爆發式增長。據IDC預測,2021-2025年,全球新增和復制的數據量復合增長率達到23%,與此同時,全球算力規模也在同步高增長。根據華為的預測,到2030年全球通用計算算力將達3.3 ZFLOPS(FP32,每秒十萬億億次浮點計算),AI計算算力將達到105 ZFLOPS(FP16),增長500倍。
在2022世界人工智能大會上,華為輪值董事長胡厚崑做出了上述預測,他提議“AI先行”,讓國家的算力網絡的建設從這個最大的增量開始,通過新建人工智能計算中心,形成人工智能算力的網絡,也為國家推行東數西算的戰略的落地先行先試。他大膽預測,未來,算力網絡將像電網、通訊網、高鐵一樣,會成為國家新的基礎設施,為國家整體經濟的發展提供強大的動力。
隨著數字化進程推進,算力需求持續增長,數據中心的市場規模不斷擴大。國內外云計算龍頭企業亞馬遜、微軟、谷歌等紛紛加大資本開支,主要用于數據中心基礎設施的建設。服務器作為數據中心建設成本的最大部分,市場規模快速擴張。
東吳證券表示,ChatGPT引爆的AI浪潮將拉動云服務器數量的增長,其國內相關供應廠商將有望受益于下游AI+級應用所帶來的算力需求增長,國內云服務器與算力相關廠商有望直接受益。
AI服務器算力底座
數據海量增加,算法模型愈加復雜,應用場景的深入和發展,帶來了對算力需求的快速提升。
根據IDC測算,國內智能算力規模正在高速增長,2021年中國智能算力規模達155.2 EFLOPS,2022年智能算力規模將達到268.0 EFLOPS,預計到2026年智能算力規模將進入ZFLOPS級別,達到1271.4 EFLOPS。2021-2026年期間,預計中國智能算力規模年復合增長率達52.3%。通用算力規模也正在高速增長,根據IDC測算,2021年中國通用算力規模達47.7 EFLOPS,預計到2026年通用算力規模將達到111.3 EFLOPS。2021-2026年期間,預計中國通用算力規模年復合增長率為18.5%。

目前,AI服務器通常選用CPU和加速芯片組來滿足其龐大算力需求,其中加速芯片包括GPU、FPGA、ASIC等邏輯芯片,其中GPU由于其具有最強的計算能力同時具備深度學習等能力,成為服務器中加速芯片的首選。
根據中商產業研究院數據,2021年全球服務器出貨量達1315萬臺,同比增長7.8%,對應全球市場規模達995億美元。根據Counterpoint預計,2022年全球服務器市場規模有望達到1117億美元,同比增長17.0%。預計云服務提供商數據中心擴張增長驅動力主要來自于汽車、5G、云游戲和高性能計算。
根據TrendForce數據,截至2022年全球搭載GPGPU的AI服務器(推理)出貨量占整體服務器比重約1%,同時TrendForce預測2023年伴隨AI相關應用加持,年出貨量增速達到8%,2022-2026年CAGR為10.8%。
根據IDC發布的《全球人工智能市場半年度追蹤報告》顯示,2021年全球人工智能服務器市場規模達156.3億美元,約合人民幣1045億元,全球年度人工智能服務器市場首次突破千億元人民幣,同比2020年增速達39%。其中,浪潮信息、戴爾、HPE分別以20.9%、13.0%、9.2%的市占率位列前三,三家廠商總市場份額占比達43.1%。人工智能服務器市場預計將繼續高速增長,預計2026年全球人工智能服務器市場規模將達到347.1億美元,5年復合增長率為17.3%。
國內市場方面,根據IDC數據,2021年中國人工智能服務器市場規模達到59.2億美元,與2020年相比增長68.2%,其中,浪潮信息、新華三、寧暢、安擎、華為等諸多中國廠商正加速推動人工智能基礎設施產品的優化更新。預計到2026年,中國人工智能服務器市場規模將達到123.4億美元。
安信證券表示,隨著ChatGPT模型的不斷升級,其參數量和模型規模也不斷增大,因此對計算資源的需求也越來越高。尤其是在推理過程中,需要將模型加載到計算節點上進行運算,因此需要高性能的計算設備來支持模型的推理。同時,由于ChatGPT模型需要進行海量的預訓練和微調,因此需要大量的算力資源來支持這些任務。ChatGPT的發展將帶來算力需求的大幅提升。
經安信證券測算,到2024年底,若ChatGPT每日用戶數量達5億人,則需要23萬臺服務器;若用戶數量達10億人,則需要46萬臺服務器。2022-2024年CAGR分別達51.7%、114.5%。
隨著GPT模型在各個領域的應用越來越廣泛,對算力的需求也在不斷增加。一方面,由于GPT模型的參數量越來越大,每次訓練需要的算力也越來越大;另一方面,GPT模型的應用場景也在不斷拓展,例如自然語言處理、計算機視覺、語音識別等領域,這些領域對算力的需求也越來越高。預計未來每日訪客數量將有巨大提升空間,算力需求短期內有較大提升空間,AI服務器數量有較大增長空間。
AI芯片算力“明珠”
AI芯片是提供算力的基礎,包括人工智能芯片、服務器、計算架構、算法及應用等方面。
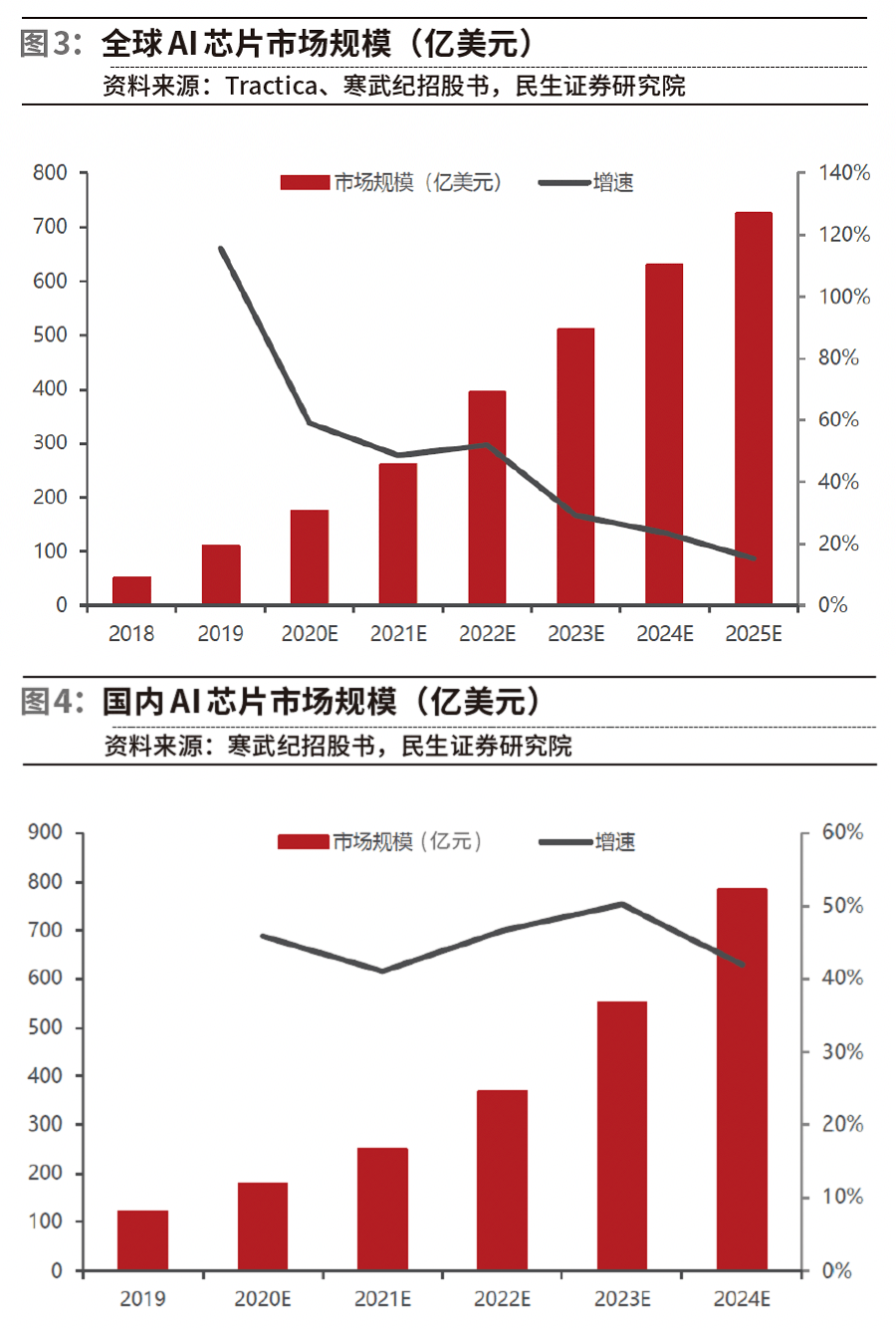
全球人工智能技術發展逐漸成熟,數字化基礎設施不斷建設完善,推動全球人工智能芯片市場高速增長。IDC全球范圍調研顯示,人工智能芯片搭載率(attach rate)將持續增高。根據Tractica、寒武紀招股書相關數據,全球人工智能芯片2022年市場規模預計約395億美元,預計到2025年將達到726億美元,年復合增長率達到22%。
國內市場方面,隨著大數據的發展和計算能力的提升,根據寒武紀招股書,2022年中國人工智能芯片市場規模預計達368億元,預計2024年市場規模將達到785億元,復合增速有望達到46%。
根據IDC數據,2021年中國AI芯片市場中,GPU的市場占有率近90%。因此,GPU也成為算力的核心硬件。
GPU是圖形處理器的簡稱,它是一種專門用于處理圖形、視頻、游戲等高性能計算的硬件設備。GPU相對于傳統的中央處理器(CPU)而言,其擁有更多的計算核心和更快的內存帶寬,能夠大幅度提高計算效率和圖形渲染速度。
現階段,隨著例如英偉達A100、H100等型號產品的發布,GPU在算力方面的優勢相較于其他硬件具有較大優勢,GPU的工作也從一開始的圖形處理逐步轉化為計算,成為最適合支撐人工智能訓練和學習的硬件。
國盛證券認為,其原因主要在于一是擁有更多處理單元:GPU相比于CPU等其他硬件有更多的處理單元(核心數更多),因此可以并行處理更多的數據。主要系GPU最初是為了圖形渲染而設計的,而圖形渲染涉及的計算是高度并行化的。這種并行化的特性使GPU非常適合進行機器學習和深度學習這樣的大規模數據并行計算。
二是具有更高的內存帶寬和更大的內存容量:在進行深度學習等計算時,需要大量的內存和高速的內存帶寬來存儲和處理海量數據。GPU相比于其他硬件(如CPU),具有更高的內存帶寬和更大的內存容量,可以更有效地存儲和處理數據,從而提高計算速度。
三是具有專門的計算單元:相較于其他硬件,GPU具有例如張量核心和矩陣乘法等計算單元,可以更快地執行常見的機器學習和深度學習操作:如卷積和矩陣乘法。這些計算單元與通用計算單元相比,具有更高的效率和更快的速度。
基于上述優勢,通用圖形處理單元(GPGPU)也因運而生,其主要利用GPU的功能來執行CPU的任務,雖然在設計初期是為了更好地圖形處理,但是多內核多通道的設計使其非常適合科學計算,發展至今GPGPU也成為了專為計算而設計的硬件。
GPU市場規模的大小取決于多種因素,其中游戲和娛樂市場一直是GPU市場的主要驅動力,因為這些領域需要高性能的GPU來支持更高質量的游戲畫面和娛樂內容。同時人工智能和機器學習的發展對GPU市場也有著巨大的影響,因為這些技術需要大量的計算能力,而GPU可以提供比CPU更高的效率。此外,科學和研究領域的需求以及新興市場(如游戲機和數據中心)也對GPU市場的規模產生了影響。根據Verified Market Research的數據,2021年全球GPU市場規模為334.7億美元,預計到2030年將達到4473.7億美元,期間CAGR達到33.3%。
目前,GPU在AI服務器中價值量占比接近50%。據國盛證券測算,以英偉達的DGX A100為例,其搭載了8張A100 Tensor GPU,根據新浪科技數據,DGX A100售價約為19.9萬美元; A100 Tensor價格為1.00萬-1.20萬美元。按照1.20萬美元售價計算可得出GPU在DGX A100價值量占比約為48.24%。
根據TrendForce的預計,2023年全球AI服務器(推理)出貨大約在14.4萬臺,到2026年預計實現出貨量20.0萬臺。假設訓練AI服務器和推理AI服務器的比例為1:4,則可以得到2023年、2026年訓練服務器的數量大約為3.60萬、5.00萬臺。由于兩種AI 服務器對應的模型訓練階段不同,假設推理AI服務器和訓練AI服務器使用的GPU數量分別為4張和8張,則可以計算出2023年、2026年全球AI服務器領域所需GPU數量約為86.4萬張和120萬張,以A100 Tensor約1.20萬美元的價格作為參考計算出2023年、2026年AI服務器所需GPU的價值分別為103.7億美元和144.0 億美元。
此外,汽車智能化也將帶動GPU的算力需求。輔助駕駛成為汽車研發的重點方向,L1至L5級別越高自動化水平越高,對于算力的需求也隨之大幅提升。為了實現L2或者更高等級的自動駕駛,往往需要部署如攝像頭、激光雷達在內的多種傳感器,例如Tesla Model 3車型中包括了8個攝像頭和12個超聲波雷達。多傳感器帶來的是龐大的數據處理需求,伴隨攜帶自動駕駛功能的汽車銷量持續提升,相關算力硬件需求也逐步擴大。
目前,英偉達自動駕駛平臺NVIDIA DRIVE Thor能夠提供2000 TFLOPS算力,為自動駕駛、車載AI、停車輔助等多功能提供所需算力需求。
目前,全球GPU市場基本被海外企業壟斷。全球范圍內,人工智能、云端計算和獨立GPU主要為英偉達主導,旗下深度學習旗艦GPU產品A100和H100最高浮點算力分別實現19.5 TFLOPS和67 TFLOPS;PC GPU由于涵蓋集成GPU,英特爾由于為全球CPU龍頭,使其在PC GPU中份額最高。
根據Jon Peddie Research數據,2022年四季度PC GPU中,英特爾、英偉達、AMD份額分別為71%、17%、12%;2022年四季度獨立GPU中,英特爾、英偉達、AMD 份額分別為6%、85%、9%。
2022年10月,美國對中國半導體進行三方面限制,在AI領域限制中國獲取等效8 Int 600 TOPS 算力的芯片。英偉達針對中國市場推出了符合新規的A800芯片,相比A100芯片,A800互聯標準由600GB/s降為400GB/s,國產大模型算力需求和國內AI產業發展面臨阻礙。
高端型號產品的出口限制將在很大程度上影響國內相關領域的發展,根據國盛證券的計算,GPT-3當日完成訓練需要的A100數量將超過3萬塊,國內公司百度旗下大模型ERNIE3.0 Titan,參數量達到2600億,高于GPT-3的1750億,其所需的同規格GPU數量也將遠大于GPT-3。同時,未來AI倘若進入大模型時代,相關算力需求將快速增加,屆時對于國產高算力GPU需求將進一步提升, GPU國產化進程迫在眉睫。
東吳證券表示,以GPU細分賽道來看,目前國內自研GPU的領軍企業主要是寒武紀、景嘉微、華為昇騰等,其中成立最早的是景嘉微,主打產品有JH920獨立顯卡。行業內專家稱,從產品參數來看,景嘉微的JH920的性能與英偉達在2016年發布的GTX 1050相仿,雖然僅相差6年,但考慮到模型與算力發展之迅速,整體而言國產GPU的現狀并不算樂觀,雖然在特殊領域可滿足部分的需求,但是在中高端領域及硬核的算力需求仍存在較長的追趕道路。
國產替代加速期
東方證券表示,人工智能一直是中美兩國科技競爭的重要領域,而中美在AI的三大技術數據、算法、算力中各有優勢。中國的數據優勢較為明顯,然而算法和智能算力卻明顯落后于美國。智能算力對于中國發展AI、數據要素以及社會全方位的發展都有著重大的戰略意義。
從智能算力總額來看,美、中處于領先地位。從人均智能算力的角度,中國仍處于全球中等水平。據《中國算力指數發展白皮書(2022)》,美、中的智能算力處于全球領先地位,分別占全球比重的45%和28%。然而從人均算力的高低來衡量,中國僅處于中等水平。據IMB研究發現,人均算力的水平與一國的智能化水平高度相關,中國積極發展智能算力、打造智算中心是打造國際競爭力、發展綜合國力的關鍵。
近年來,國家制定一系列政策,在全國范圍內推動信息基礎設施建設,智算中心的建設是其中的關鍵環節。2020年4月20日,國家發改委首次明確新型基礎設施范圍,將智能計算中心作為算力基礎設施的重要代表納入信息基礎設施范疇。2021年5月,國家發改委等四部門聯合發布了《全國一體化大數據中心協同創新體系算力樞紐實施方案》,提出布局全國算力網絡樞紐節點。2022年2月17日,國家發改委、中央網信辦、工業和信息化部、國家能源局聯合印發通知,同意在京津冀、長三角、粵港澳大灣區、成渝、內蒙古、貴州、甘肅、寧夏8地啟動建設國家算力樞紐節點,并規劃了10個國家數據中心集群。“東數西算”工程正式全面啟動。而智算中心承載的以模型訓練為代表的非實時性計算尤為適合“東數西算”。
隨著全國一體化算力網絡和“東數西算”工程的部署,中國智能計算中心也加快布局。根據國家信息中心與相關部門聯合發布的《智能計算中心創新發展指南》,當前超過30個城市正在建設或提出建設智算中心,整體布局以東部地區為主,并逐漸向中西部地區拓展。根據ICPA智算聯盟統計,截至2022年3月,全國已投運的人工智能計算中心有近20個,在建設的人工智能計算中心超20個。
另外,科技部出臺政策推動人工智能公共算力平臺建設,要求在混合部署的公共算力平臺中,自主研發芯片所提供的算力標稱值占比不低于60%,并優先使用國產開發框架,使用率不低于60%,此舉將推動中國AI芯片等國產化進程。
隨著智能計算資源需求的大幅增加,東方證券認為 AI芯片、AI服務器以及云計算算力需求將持續提升,國產化替代有望加速。
AI計算需要多元異構算力提供支持,將極大拉動GPGPU、AISC等AI芯片的需求。中國AI芯片市場規模有望快速增長,據艾瑞咨詢發布的《2022年中國人工智能產業研究報告(Ⅴ)》,預計2027年達到2164億元。目前,英偉達憑借其AI芯片的超高性能,占中國加速卡市場的80%以上。根據東方證券研報,海光信息、寒武紀等巨頭堅持迭代升級,其產品性能日益提升,有望獲得更多市場份額,實現國產替代。另外,隨著大模型的成熟部署,對性能要求稍低的推理芯片的占比將日益提升,也有益于國產AI芯片占比提升。
AI計算需求提升有望持續拉動AI服務器需求,國產AI服務器龍頭有望持續受益。相比于AI芯片,AI服務器的技術壁壘較低,浪潮信息、中科曙光等中國服務器廠商占領了AI服務器絕大部分市場,有望持續受益于智能算力需求提升。根據東方證券研報,浪潮信息的AI服務器在世界市場和中國市場均蟬聯第一位,是AI服務器行業的頂尖巨頭。而中科曙光是高性能計算的龍頭,響應國家號召建設曙光5A級智算中心,覆蓋全算力精度,賦能人工智能應用場景落地。拓維信息和四川長虹則是華為的親密合作伙伴,依托“昇騰+鯤鵬”打造AI服務器。
隨著AI算法的計算需求不斷增加,將有越來越多的企業使用云計算平臺來滿足其計算需求,中立云計算廠商有望持續受益。云計算廠商可以為企業提供靈活的計算資源,幫助企業更好地管理其計算需求,提高其計算效率和靈活性,減少部署和管理本地計算基礎設施的復雜性。根據東方證券研報,除了華為云等國內外云計算巨頭,優刻得、深桑達旗下中國電子云等第三方中立廠商也在積極參與AI云服務,有望持續受益于AI算力需求的提升。一方面,這些廠商可以作為客戶除云大廠外的第二選擇。另外,這些廠商具有中立方的身份優勢,不會和下游客戶產生競爭,更容易獲得客戶信任。





