
作者 | 郭文飛
編輯 | 蔡芳芳
2021 年,字節跳動旗下產品總 MAU 已超過 19 億。在以抖音、今日頭條、西瓜視頻等為代表的產品業務背景下,強大的推薦系統顯得尤為重要。Flink 提供了非常強大的 SQL 模塊和有狀態計算模塊。目前在字節推薦場景,實時簡單計數特征、窗口計數特征、序列特征已經完全遷移到 Flink SQL 方案上。結合 Flink SQL 和 Flink 有狀態計算能力,我們正在構建下一代通用的基礎特征計算統一架構,期望可以高效支持常用有狀態、無狀態基礎特征的生產。
業務背景
對于今日頭條、抖音、西瓜視頻等字節跳動旗下產品,基于 Feed 流和短時效的推薦是核心業務場景。而推薦系統最基礎的燃料是特征,高效生產基礎特征對業務推薦系統的迭代至關重要。
主要業務場景

- 抖音、火山短視頻等為代表的短視頻應用推薦場景,例如 Feed 流推薦、關注、社交、同城等各個場景,整體在國內大概有 6 億 + 規模 DAU;
- 頭條、西瓜等為代表的 Feed 信息流推薦場景,例如 Feed 流、關注、子頻道等各個場景,整體在國內大概有 1.5 億 + 規模 DAU; 業務痛點和挑戰

目前字節跳動推薦場景基礎特征的生產現狀是“ 百花齊放”。離線特征計算的基本模式都是通過消費 Kafka、BMQ、Hive、HDFS、Abase、RPC 等數據源,基于 Spark、Flink 計算引擎實現特征的計算,而后把特征的結果寫入在線、離線存儲。各種不同類型的基礎特征計算散落在不同的服務中,缺乏業務抽象,帶來了較大的運維成本和穩定性問題。
而更重要的是,缺乏統一的基礎特征生產平臺,使業務特征開發迭代速度和維護存在諸多不便。如業務方需自行維護大量離線任務、特征生產鏈路缺乏監控、無法滿足不斷發展的業務需求等。

在字節的業務規模下,構建統一的實時特征生產系統面臨著較大挑戰,主要來自四個方面:
巨大的業務規模:抖音、頭條、西瓜、火山等產品的數據規模可達到日均 PB 級別。例如在抖音場景下,晚高峰 Feed 播放量達數百萬 QPS,客戶端上報用戶行為數據 高達數千萬 IOPS。業務方期望在任何時候,特征任務都可以做到不斷流、消費沒有 lag 等,這就要求特征生產具備非常高的穩定性。
較高的特征實時化要求:在以直播、電商、短視頻為代表的推薦場景下,為保證推薦效果,實時特征離線生產的時效性需實現常態穩定于分鐘級別。
更好的擴展性和靈活性:隨著業務場景不斷復雜,特征需求更為靈活多變。從統計、序列、屬性類型的特征生產,到需要靈活支持窗口特征、多維特征等,業務方需要特征中臺能夠支持逐漸衍生而來的新特征類型和需求。
業務迭代速度快:特征中臺提供的面向業務的 DSL 需要足夠場景,特征生產鏈路盡量讓業務少寫代碼,底層的計算引擎、存儲引擎對業務完全透明,徹底釋放業務計算、存儲選型、調優的負擔,徹底實現實時基礎特征的規模化生產,不斷提升特征生產力;
迭代演進過程
在字節業務爆發式增長的過程中,為了滿足各式各樣的業務特征的需求,推薦場景衍生出了眾多特征服務。這些服務在特定的業務場景和歷史條件下較好支持了業務快速發展,大體的歷程如下:
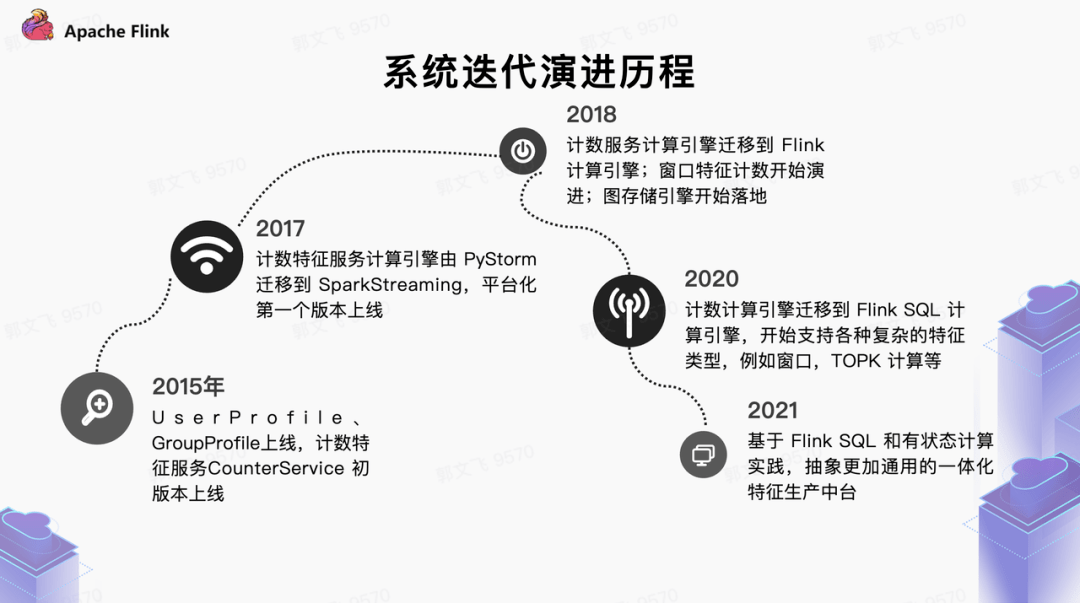
推薦場景特征服務演進歷程
在這其中 2020 年初是一個重要節點,我們開始在特征生產中引入 Flink SQL、Flink State 技術體系,逐步在計數特征系統、模型訓練的樣本拼接、窗口特征等場景進行落地,探索出新一代特征生產方案的思路。
新一代系統架構
結合上述業務背景,我們基于 Flink SQL 和 Flink 有狀態計算能力重新設計了新一代實時特征計算方案。 新方案的定位是:解決基礎特征的計算和在線 Serving,提供更加抽象的基礎特征業務層 DSL。在計算層,我們基于 Flink SQL 靈活的數據處理表達能力,以及 Flink State 狀態存儲和計算能力等技術,支持各種復雜的窗口計算。極大地縮短業務基礎特征的生產周期,提升特征產出鏈路的穩定性。新的架構里,我們將 特征生產的鏈路分為數據源抽取 / 拼接、狀態存儲、計算三個階段,Flink SQL 完成特征數據的抽取和流式拼接,Flink State 完成特征計算的中間狀態存儲。
有狀態特征是非常重要的一類特征,其中最常用的就是帶有各種窗口的特征,例如統計最近 5 分鐘視頻的播放 VV 等。對于窗口類型的特征在字節內部有一些基于存儲引擎的方案,整體思路是“ 輕離線重在線”,即把窗口狀態存儲、特征聚合計算全部放在存儲層和在線完成。離線數據流負責基本數據過濾和寫入,離線明細數據按照時間切分聚合存儲(類似于 micro batch),底層的存儲大部分是 KV 存儲、或者專門優化的存儲引擎,在線層完成復雜的窗口聚合計算邏輯,每個請求來了之后在線層拉取存儲層的明細數據做聚合計算。
我們新的解決思路是“ 輕在線重離線”,即把比較重的 時間切片明細數據狀態存儲和窗口聚合計算全部放在離線層。窗口結果聚合通過 離線窗口觸發機制完成,把特征結果 推到在線 KV 存儲。在線模塊非常輕量級,只負責簡單的在線 serving,極大地簡化了在線層的架構復雜度。在離線狀態存儲層。我們主要依賴 Flink 提供的 原生狀態存儲引擎 RocksDB,充分利用離線計算集群本地的 SSD 磁盤資源,極大減輕在線 KV 存儲的資源壓力。
對于長窗口的特征(7 天以上窗口特征),由于涉及 Flink 狀態層明細數據的回溯過程,Flink Embedded 狀態存儲引擎沒有提供特別好的外部數據回灌機制(或者說不適合做)。因此對于這種“ 狀態冷啟動”場景,我們引入了中心化存儲作為底層狀態存儲層的存儲介質,整體是 Hybrid架構。例如 7 天以內的狀態存儲在本地 SSD,7~30 天狀態存儲到中心化的存儲引擎,離線數據回溯可以非常方便的寫入中心化存儲。
除窗口特征外,這套機制同樣適用于其他類型的有狀態特征(如序列類型的特征)。
實時特征分類體系
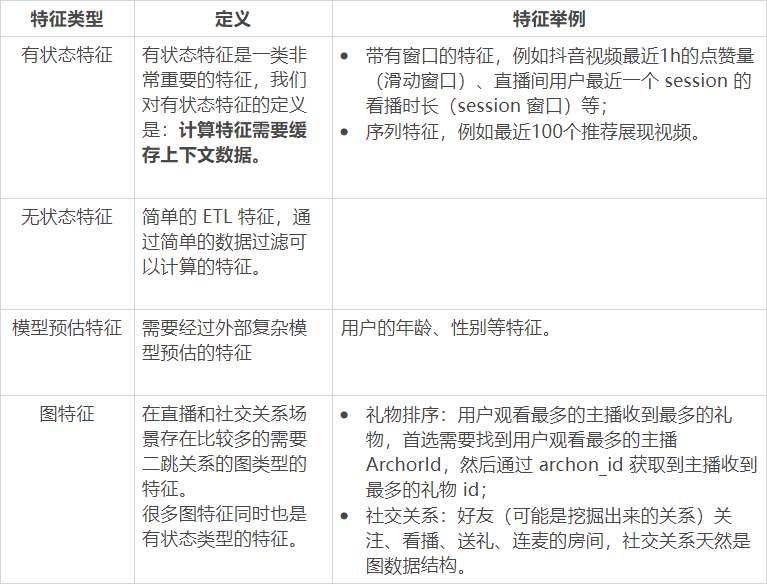
整體架構

帶有窗口的特征,例如抖音視頻最近 1h 的點贊量(滑動窗口)、直播間用戶最近一個 session 的看播時長(session 窗口)等;
數據源層
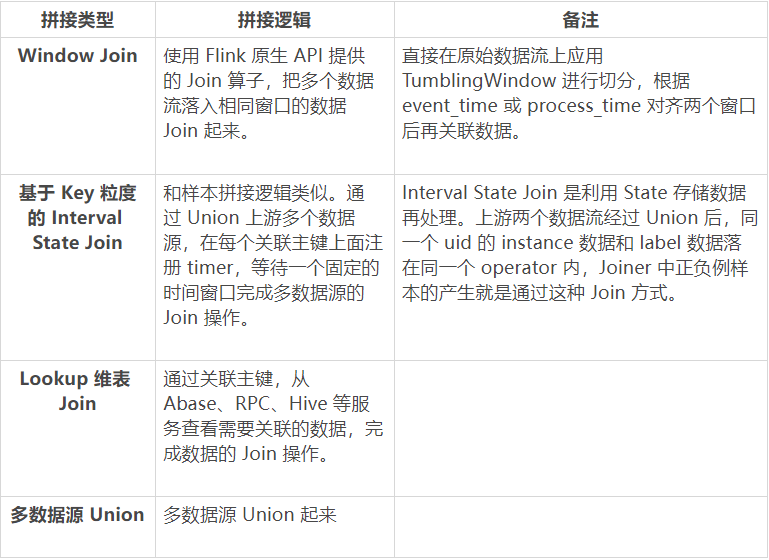
在新的一體化特征架構中,我們統一把各種類型數據源抽象為 Schema Table,這是因為底層依賴的 Flink SQL 計算引擎層對數據源提供了非常友好的 Table Format 抽象。在推薦場景,依賴的數據源非常多樣,每個特征上游依賴一個或者多個數據源。數據源可以是 Kafka、RMQ、KV 存儲、RPC 服務。對于多個數據源,支持數據源流式、批式拼接,拼接類型包括 Window Join 和基于 key 粒度的 Window Union Join,維表 Join 支持 Abase、RPC、HIVE 等。具體每種類型的拼接邏輯如下:

三種類型的 Join 和 Union 可以組合使用,實現復雜的多數據流拼接。例如 (A union B) Window Join (C Lookup Join D)。
另外,Flink SQL 支持復雜字段的計算能力,也就是業務方可以基于數據源定義的 TableSchema 基礎字段實現擴展字段的計算。業務計算邏輯本質是一個 UDF,我們會提供 UDF API 接口給業務方,然后上傳 JAR 到特征后臺加載。另外對于比較簡單的計算邏輯,后臺也支持通過提交簡單的 Python 代碼實現多語言計算。
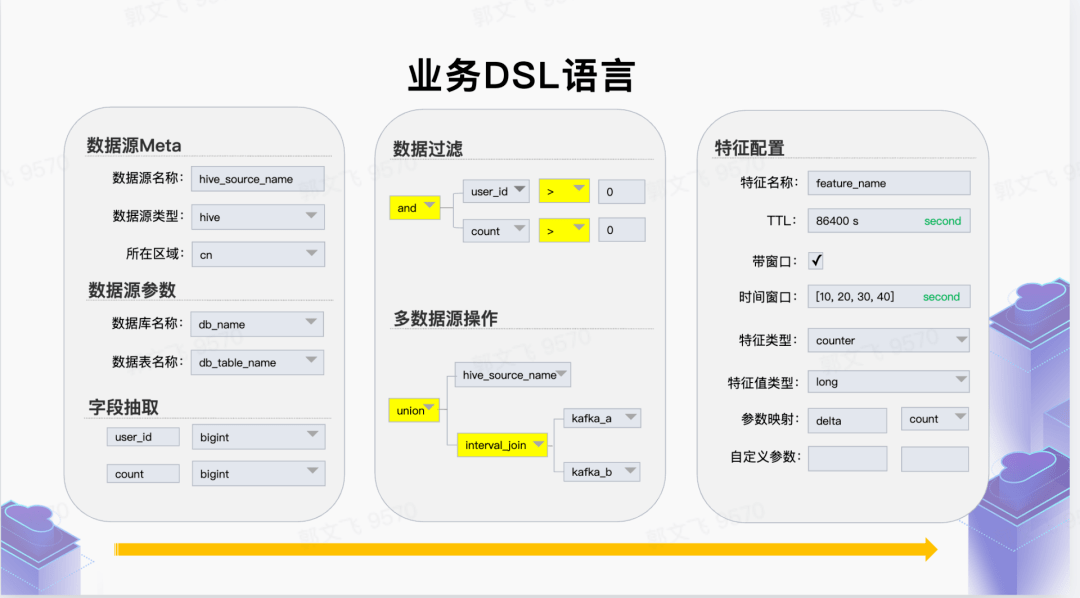
業務 DSL
從業務視角提供高度抽象的特征生產 DSL 語言,屏蔽底層計算、存儲引擎細節,讓業務方聚焦于業務特征定義。業務 DSL 層提供:數據來源、數據格式、數據抽取邏輯、數據生成特征類型、數據輸出方式等。
狀態存儲層
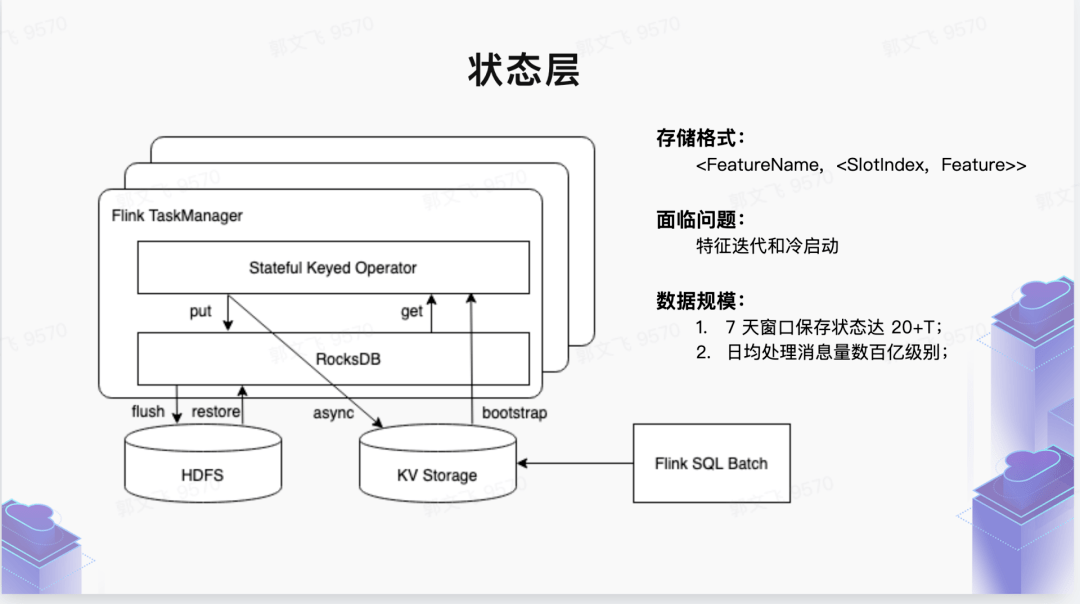
如上文所述,新的特征一體化方案解決的主要痛點是:如何應對各種類型(一般是滑動窗口)有狀態特征的計算問題。對于這類特征,在離線計算層架構里會有一個狀態存儲層,把抽取層提取的 RawFeature 按照切片 Slot 存儲起來 (切片可以是時間切片、也可以是 Session 切片等)。切片類型在內部是一個接口類型,在架構上可以根據業務需求自行擴展。狀態里面其實存儲的不是原始 RawFeature(存儲原始的行為數據太浪費存儲空間),而是轉化為 FeaturePayload 的一種 POJO 結構,這個結構里面支持了常見的各種數據結構類型:
- Int:存儲簡單的計數值類型 (多維度 counter);
- HashMap<int, int>:存儲二維計數值,例如 Action Counter,key 為 target_id,value 為計數值;
- SortedMap<int, int>: 存儲 topk 二維計數 ;
- LinkedList :存儲 id_list 類型數據;
- HashMap<int, List >:存儲二維 id_list;
- 自定義類型,業務可以根據需求 FeaturePayload 里面自定義數據類型
狀態層更新的業務接口:輸入是 SQL 抽取 / 拼接層抽取出來的 RawFeature,業務方可以根據業務需求實現 updateFeatureInfo 接口對狀態層的更新。對于常用的特征類型內置實現了 update 接口,業務方自定義特征類型可以繼承 update 接口實現。
/** * 特征狀態 update 接口 */ publicinterfaceFeatureStateApiextendsSerializable{ /** * 特征更新接口, 上游每條日志會提取必要字段轉換為 fields, 用來更新對應的特征狀態 * * @paramfields * context: 保存特征名稱、主鍵 和 一些配置參數 ; * oldFeature: 特征之前的狀態 * fields: 平臺 / 配置文件 中的抽取字段 * @return */ FeaturePayLoad assign(Context context,FeaturePayLoad feature, Map<String, Object> rawFeature); }當然對于無狀態的 ETL 特征是不需要狀態存儲層的。
計算層
特征計算層完成特征計算聚合邏輯,有狀態特征計算輸入的數據是狀態存儲層存儲的帶有切片的 FeaturePayload 對象。簡單的 ETL 特征沒有狀態存儲層,輸入直接是 SQL 抽取層的數據 RawFeature 對象,具體的接口如下:
/** * 有狀態特征計算接口 */ publicinterfaceFeatureStateApiextendsSerializable{/*** 特征聚合接口,會根據配置的特征計算窗口, 讀取窗口內所有特征狀態,排序后傳入該接口** @paramfeatureInfos, 包含 2 個 field * timeslot: 特征狀態對應的時間槽* Feature: 該時間槽的特征狀態* @return*/FeaturePayLoad aggregate(Context context, List<Tuple2<Slot, FeaturePayLoad>> slotStates);
}
有狀態特征聚合接口
/*** 無狀態特征計算接口*/publicinterfaceFeatureConvertApiextendsSerializable{/*** 轉換接口, 上游每條日志會提取必要字段轉換為 fields, 無狀態計算時,轉換為 gauss 內的 feature 類型 ;** @paramfields * fields: 平臺 / 配置文件 中的抽取字段* @return*/FeaturePayLoad convert(Context context, FeaturePayLoad featureSnapshot, Map<String, Object> rawFeatures);
}
無狀態特征計算接口
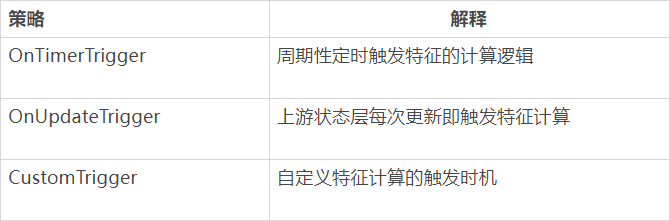
另外通過觸發機制來觸發特征計算層的執行,目前支持的觸發機制主要有:
業務落地
目前在字節推薦場景,新一代特征架構已經在 抖音直播、電商、推送、抖音推薦等場景陸續上線了一些實時特征。主要是有狀態類型的特征,帶有窗口的一維統計類型、二維倒排拉鏈類型、二維 TOPK 類型、實時 CTR/CVR Rate 類型特征、序列類型特征等。
在業務核心指標達成方面成效顯著。在直播場景,依托新特征架構強大的表達能力上線了一批特征之后,業務看播核心指標、互動指標收益非常顯著。在電商場景,基于新特征架構上線了 400+ 實時特征。其中在直播電商方面,業務核心 GMV、下單率指標收益顯著。在抖音推送場景,基于新特征架構離線狀態的存儲能力,聚合用戶行為數據然后寫入下游各路存儲,極大地緩解了業務下游數據庫的壓力,在一些場景中 QPS 可以下降到之前的 10% 左右。此外,抖音推薦 Feed、評論等業務都在基于新特征架構重構原有的特征體系。
值得一提的是,在電商和抖音直播場景,Flink 流式任務狀態最大已經達到 60T,而且這個量級還在不斷增大。 預計不久的將來,單任務的狀態有可能會突破 100T,這對架構的穩定性是一個不小的挑戰。
性能優化
Flink State Cache
目前 Flink 提供兩類 StateBackend:基于 Heap 的 FileSystemStateBackend 和基于 RocksDB 的 RocksDBStateBackend。對于 FileSystemStateBackend,由于數據都在內存中,訪問速率很快,沒有額外開銷。而 RocksDBStateBackend 存在查盤、序列化 / 反序列化等額外開銷,CPU 使用量會有明顯上升。在字節內部有大量使用 State 的作業,對于大狀態作業,通常會使用 RocksDBStateBackend 來管理本地狀態數據。RocksDB 是一個 KV 數據庫,以 LSM 的形式組織數據,在實際使用的過程中,有以下特點 :
- 應用層和 RocksDB 的數據交互是以 Bytes 數組的形式進行,應用層每次訪問都需要序列化 / 反序列化;
- 數據以追加的形式不斷寫入 RocksDB 中,RocksDB 后臺會不斷進行 compaction 來刪除無效數據。
業務方使用 State 的場景多是 get-update,在使用 RocksDB 作為本地狀態存儲的過程中,出現過以下問題:
- 爬蟲數據導致熱 key,狀態會不斷進行更新 (get-update),單 KV 數據達到 5MB,而 RocksDB 追加更新的特點導致后臺在不斷進行 flush 和 compaction,單 task 出現慢節點(抖音直播場景)。
- 電商場景作業多數為大狀態作業 (目前已上線作業狀態約 60TB),業務邏輯中會頻繁進行 State 操作。在融合 Flink State 過程中發現 CPU 的開銷和原有~~ 的~~ 基于內存或 abase 的實現有 40%~80% 的升高。經優化后,CPU 開銷主要集中在序列化 / 反序列化的過程中。
針對上述問題,可以通過在內存維護一個對象 Cache,達到優化熱點數據訪問和降低 CPU 開銷的目的。通過上述背景介紹,我們希望能為 StateBackend 提供一個通用的 Cache 功能,通過 Flink StateBackend Cache 功能設計方案達成以下目標:
- 減少 CPU 開銷 : 通過對熱點數據進行緩存,減少和底層 StateBackend 的交互次數,達到減少序列化 / 反序列化開銷的目的。
- 提升 State 吞吐能力 : 通過增加 Cache 后,State 吞吐能力應比原有的 StateBackend 提供的吞吐能力更高。理論上在 Cache 足夠大的情況下,吞吐能力應和基于 Heap 的 StateBackend 近似。
- Cache 功能通用化 : 不同的 StateBackend 可以直接適配該 Cache 功能。目前我們主要支持 RocksDB,未來希望可以直接提供給別的 StateBackend 使用,例如 RemoteStateBackend。
經過和字節基礎架構 Flink 團隊的合作,在實時特征生產升級 ,上線 Cache 大部分場景的 CPU 使用率大概會有高達 50% 左右的收益;
PB IDL 裁剪
在字節內部的實時特征離線生成鏈路當中,我們主要依賴的數據流是 Kafka。這些 Kafka 都是通過 PB 定義的數據,字段繁多。公司級別的大 Topic 一般會有 100+ 的字段,但大部分的特征生產任務只使用了其中的部分字段。對于 Protobuf 格式的數據源,我們可以完全通過裁剪數據流,mask 一些非必要的字段來節省反序列化的開銷。PB 類型的日志,可以直接裁剪 idl,保持必要字段的序號不變,在反序列化的時候會跳過 unknown field 的解析,這 對于 CPU 來說是更節省的,但是網絡帶寬不會有收益,預計裁剪后能節省非常多的 CPU 資源。在上線了 PB IDL 裁剪之后, 大部分任務的 CPU 收益在 30% 左右。
遇到的問題
新架構特征生產任務本質就是一個有狀態的 Flink 任務,底層的狀態存儲 StateBackend 主要是本地的 RocksDB。主要面臨兩個比較難解的問題,一是任務 DAG 變化 Checkpoint 失效,二是本地存儲不能很好地支持特征狀態歷史數據回溯。
-
實時特征任務不能動態添加新的特征:對于一個線上的 Flink 實時特征生產任務,我們不能隨意添加新的特征。這是由于引入新的特征會導致 Flink 任務計算的 DAG 發生改變,從而導致 Flink 任務的 Checkpoint 無法恢復,這對實時有狀態特征生產任務來說是不能接受的。目前我們的解法是禁止更改線上部署的特征任務配置,但這也就導致了線上生成的特征是不能隨便下線的。對于這個問題暫時沒有找到更好的解決辦法,后期仍需不斷探索。
- 特征狀態冷啟動問題:目前主要的狀態存儲引擎是 RocksDB,不能很好地支持狀態數據的回溯。 后續規劃
當前新一代架構還在字節推薦場景中快速演進,目前已較好解決了實時窗口特征的生產問題。
出于實現統一推薦場景下特征生產的目的,我們后續會繼續基于 Flink SQL 流批一體能力,在批式特征生產發力。此外也會基于 Hudi 數據湖技術,完成特征的實時入湖,高效支持模型訓練場景離線特征回溯痛點。規則引擎方向,計劃繼續探索 CEP,推動在電商場景有更多落地實踐。在實時窗口計算方向,將繼續深入調研 Flink 原生窗口機制,以期解決目前方案面臨的窗口特征數據退場問題。
-
支持批式特征:這套特征生產方案主要是解決實時有狀態特征的問題,而目前字節離線場景下還有大量批式特征是通過 Spark SQL 任務生產的。后續我們也會基于 Flink SQL 流批一體的計算能力,提供對批式場景特征的統一支持,目前也初步有了幾個場景的落地;
-
特征離線入湖:基于 Hudi On Flink 支持實時特征的離線數倉建設,主要是為了支持模型訓練樣本拼接場景離線特征回溯;
-
Flink CEP 規則引擎支持:Flink SQL 本質上就是一種規則引擎,目前在線上我們把 Flink SQL 作為業務 DSL 過濾語義底層的執行引擎。但 Flink SQL 擅長表達的 ETL 類型的過濾規則,不能表達帶有時序類型的規則語義。在直播、電商場景的時序規則需要嘗試 Flink CEP 更加復雜的規則引擎。
-
Flink Native Windowing 機制引入:對于窗口類型的有狀態特征,我們目前采用上文所述的抽象 SlotState 時間切片方案統一進行支持。另外 Flink 本身提供了非常完善的窗口機制,通過 Window Assigner、Window Trigger 等組件可以非常靈活地支持各種窗口語義。因此后續我們也會在窗口特征計算場景引入 Flink 原生的 Windowing 機制,更加靈活地支持窗口特征迭代。
-
Flink HybridState Backend 架構:目前在字節的線上場景中,Flink 底層的 StateBackend 默認都是使用 RocksDB 存儲引擎。這種內嵌的存儲引擎不能通過外部機制去提供狀態數據的回灌和多任務共享,因此我們需要支持 KV 中心化存儲方案,實現靈活的特征狀態回溯。
- 靜態屬性類型特征統一管理 :通過特征平臺提供統一的 DSL 語義,統一管理其他外部靜態類型的特征服務。例如一些其他業務團隊維度的用戶分類、標簽服務等。
作者介紹:
郭文飛,字節跳動推薦系統基礎服務方向負責人。2015 年初加入字節,主要負責推薦系統基礎服務方向,例如消重、計數、特征等。





