

9月末,Meta發布了新款AI系統Make-A-Video,開啟了“用嘴做視頻”的時代。谷歌不甘落后,在Make-A-Video推出后一周帶著Imagen Video和Phenaki兩款類似的人工智能產品登場。
這幾款產品吸引了技術圈、流媒體行業和吃瓜者的一波又一波的關注,不少大V紛紛感慨原來AI在不知不覺間已經發展得如此智能,自己似乎有些適應不了AI的進化速度了。。。
那么,Meta和谷歌推出的這幾款AI產品究竟有哪些逆天功能?AI的發展又會給Web3時代的內容創作帶來怎樣的改變?
“用嘴做視頻”的時代到來了嗎?
首先,Meta推出的Make-A-Video是一款可以直接基于文字生成短視頻的人工智能系統。
根據Meta AI官網生成的部分短視頻內容顯示,Make-A-Video允許用戶輸入一些單詞或句子,比如“一只披著紅色斗篷、穿著超人服裝的狗在天空中飛翔”,然后系統會生成一個時長5秒的視頻片段。
除此之外,官網示例還有UFO在火星著陸、畫家在畫布上畫畫、馬喝水等短視頻片段。

除了文本輸入外,Make-A-Video還可以根據其他視頻或圖片制作新視頻,或是生成連接圖像的關鍵幀,讓靜態圖片動起來。
不過,Make-A-Video目前只能生成5秒的16幀/秒無聲片段,畫面只能描述一個動作或場景,像素也只有768×768。
并且從官網示例來看,雖然Make-A-Video生成視頻的畫面準確率很高,但動態效果生硬、部分畫面要素過于獵奇,甚至還有些不符合常理,總體上來說視頻效果還是不盡如人意。
不過,對于AI產品的視頻清晰度和畫面時長問題,谷歌AI又一次帶給大家驚喜。
此次谷歌推出的兩款產品中,其中一個叫Imagen Video。Imagen Video是一款和Make-A-Video類似的產品,可以根據文本生成視頻。
與Meta的產品相比,Imagen Video可以生成1280×768的24幀/秒高清視頻片段,至少對于目前人工智能發展來看,技術已經相當可以了。不少網友看了產品網站之后紛紛感慨“誤以為進了視頻素材網站”。
在官方發表的論文中寫到,Imagen Video除了能夠生成高清視頻外,還會在公開可用的LAION-400M圖像文本數據集、1400萬個視頻文本對和6000萬個圖像文本對上進行訓練,因此還具備一些純從數據中學習的非結構化生成模型所沒有的獨特功能。
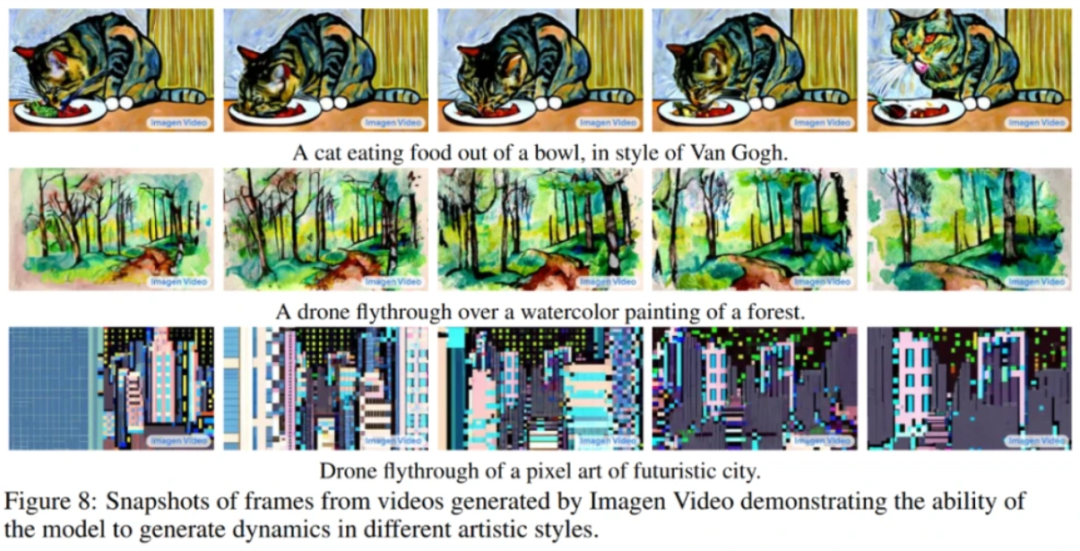
例如,它能理解并生成不同藝術風格的作品,如“水彩”或者“像素畫”,或者直接“梵高風格繪畫”等。
它還能理解物體的3D結構,并基于理解生成旋轉對象的視頻,同時物體的大致結構也能保留,至少不會變形。

最后,它還繼承了此前Imagen文本生成圖像系統的準確描繪文字的能力,在此基礎上僅靠簡單描述產生各種創意動畫,為眾多自媒體行業的朋友們提供了一條素材選擇、制作的捷徑。
而谷歌此次推出的另一款產品Phenaki,則是能根據200個詞左右的提示語生成2分鐘以上的長視頻,講述一個完整的故事。
雖然圖片畫質不如Imagen Video,但Phenaki所呈現的視頻非常貼近文本描述,而且谷歌認為它不僅可用來產生描述單個概念的視頻,還能可根據一系列的文本,產生有連貫性的多個視頻。
基于移動互聯網的普及,產生的圖像資料集、視頻資料庫數據非常龐大。
不管是Meta的Make-A-Video還是谷歌的Imagen Video或Phenaki,都可以利用現有的視頻與圖像數據資源進行AI訓練,讓生成的AI作品更加真實,也為之后的內容生產提供了新的思路。
對AI還有哪些期待?
如今,互聯網內容形態正在變得豐富多樣,從文字、圖片到音樂、視頻,再到直播、游戲,內容需求無處不在,用戶每天消費的內容不斷增加,但是靠人力創作已經很難滿足需求的增長。
隨著科技技術的提升,AI讓內容生產變得更容易、更個性。
盡管從畫面效果和情節串聯上,現有的AI產品還遠遠比不上人力創作,但Meta和谷歌此次的新產品著實讓人眼前一亮,并且讓人們開始期待AI將會如何引領內容生產的發展。
可以說,從UGC、PGC到如今的AIGC(人工智能生產內容),內容生產正在進入一段新的革命,不僅會將內容產業的繁榮推向新的高度,也將對社會的演進產生更深遠的影響。
最后,我們不妨看得更長遠些,無論是元宇宙還是Web3,下一代互聯網的繁榮需要海量的數字內容,同時對內容的數量、形式和交互性都提出了更高的要求。從這個角度來看,AIGC便顯得尤為必要。
在可預見的未來里,AIGC會改變很多行業。那我們不妨多些期待,去擁抱AIGC時代的到來。





