
簡介: 新的接入方案在接入成本、接入延遲上都有了較為明顯的優化效果,減輕了對統一調度系統的負載壓力,并具備了端到端的業務對賬能力。在公司開源協同的大背景下,TDBank的hive數據實時接入方案已經應用在pcg數據的接入中,并將逐步替換pcg現有的基于atta的數據接入。對TEG信安數據的接入目前也在進行中,后續我們還計劃對現網存量的TDBank數據接入任務也進行遷移。
一、TDBank接入hive數據的痛點和挑戰
數據接入到Hive是TDW數據接入中應用最廣泛的場景,整體的數據流向路徑如下所示:

圖1 數據接入到TDW Hive的流向路徑
數據從源側發送,經過TDBus后存入MQ,然后由TDSort消費并根據業務規則進行分揀處理后存入中轉的hdfs目錄,再由配置的統一調度任務定時將數據以分區為單位寫入hive倉庫。可以看出,整個系統數據流經的環節較多,對運維和用戶具有如下的痛點:
難以保證實時入庫。數據多次流轉、統一調度本身調度的延遲、hdfs性能的抖動、gaia資源的競爭(統一調度會通過hive生成gaia應用執行實際入庫邏輯)等都會導致入庫延遲。
接入質量無法衡量。由于缺少入庫數據的對賬環節,導致往往難以在第一時間感知到數據接入質量的好壞。
接入和運維成本高。整個過程需要額外準備hdfs存儲資源、統一調度資源、hive資源、gaia計算資源,需維護這些資源和服務的可用性。這里面僅僅是統一調度的入庫任務就占其總任務量的一半左右,給統一調度也帶來了巨大的計算量。
整個過程需要額外的物力和人力投入,且還無法保證入庫的及時性(不考慮數據遲到話入庫延遲一般在30分鐘到幾小時之間)。
除此之外,大數據接入還有如下的挑戰:
高流量和易運維性
目前tdbank接入的hive表總數為153978,日均的接入量為30萬億左右,其中最大的業務日均接入量達8萬億+。一方面流量巨大使得接入中斷或重啟的成本非常高,一方面需接入的hive表和業務規則眾多,而我們需要根據業務規則把數據按照相應的格式落地到對應的hive。而這里的接入數據和業務規則往往會動態變化,故我們需要靈活高效的適應業務規則的變動。
接入延遲和數據碎片
接入延遲和數據碎片是一對矛盾體。追求低接入延遲會導致產生數據碎片,不利于HDFS的存儲,并降低數據查詢的效率。而高接入延遲在某些場景下無法被用戶接受,在實際中需要權衡。
異常處理和數據一致性
流式數據處理過程中隨時可能因為機器、磁盤、人為、軟件等故障原因中斷或重啟,這種情況下必然有一部分數據是on the fly的,從而導致了不一致性,在大數據流量場景下會更加明顯。Flink作為流式數據處理領域最流行的框架為我們提供了分布式系統流式數據處理時具有exactly_once語義的checkpoint機制,以幫助解決異常恢復問題,但應用仍然需要自己處理source和sink的狀態保存和恢復,其中sink側的處理尤其具有挑戰性。
指標統計
從業務和運維角度,需要按表分區的維度統計指標數據。分布式系統中指標統計會面臨兩個問題:一是如何對指標按所需維度做匯聚;二是異常恢復時如何對指標進行回滾。
數據(負載)傾斜
TDSort運行在gaia上,gaia目前只支持對CPU和內存進行管控,而流式數據處理中IO資源,尤其是網絡IO也是一種寶貴的資源。在大數據流量場景下極易發生因節點流量不均勻而導致的數據傾斜。
故障轉移
大流量下,流式數據處理應用啟停的代價相對較高,而機器、磁盤等經常會因為一些原因發生故障,這時需要有便利的手段使得運維人員可以進行剔除gaia節點、切換gaia集群等操作。
Sink(HDFS)性能抖動
HDFS性能抖動或故障除了導致數據無法寫入、吞吐降低外,還會導致TDSort做checkpoint時因超時而失敗。
二、接入實時性優化和功能增強
TDBus可以幫助收斂MQ的producer連接數并提供一個業務維度指標統計的切入點,MQ是數據暫存并可削峰平谷、解耦數據發送和數據處理,TDSort作為類似ETL或者data pipeline的角色承載了主要的數據接入邏輯,從業務角度審視都有其存在的必要性。入庫任務主要承擔如下功能:
根據調度配置定期去中轉的hdfs目錄上檢查某個分區的數據是否已準備就緒;
準備就緒后創建hive外表,然后通過執行sql將數據從中轉目錄插入到實際的hive分區目錄,這個過程是統一調度提交sql到hive server,hive server再在gaia上提交并運行任務完成的,中間涉及到的數據格式的轉換也都是gaia上的任務來完成的。
基于以上分析,我們做了如下優化:
去除了統一調度任務入庫的邏輯,業務數據由TDSort直接寫入hive庫。為了做到直接入庫,TDSort除了需要獲取到hive庫表、分區等相關信息外,還需要支持將源數據轉換為所需要的hive文件格式、壓縮類型等。
提供了高效的分區入庫狀態查詢服務TDLedger
增加了端到端對賬的支持,同樣由TDLedger承載。
對checkpoint的全面支持。
通過oceanus平臺啟停TDSort應用。Oceanus為我們提供了方便的任務啟停、checkpoint保存、歷史checkpoint點管理和恢復、資源管理和審批等功能,讓我們可以聚焦于業務本身。
優化后的數據流向圖如下所示:

圖2 優化后的hive數據接入流向
除了數據流向本身的優化外,圖中同時新增了入口指標流和出口指標流的統計計算,并在TDLedger側進行對賬,這對用戶和運維側也是非常重要的功能。
三、接入實時性優化效果
以日均接入6000億、gzip壓縮、文本格式接入的業務為例,下面為優化前后的對比:
入庫延遲可以滿足TP99<15min
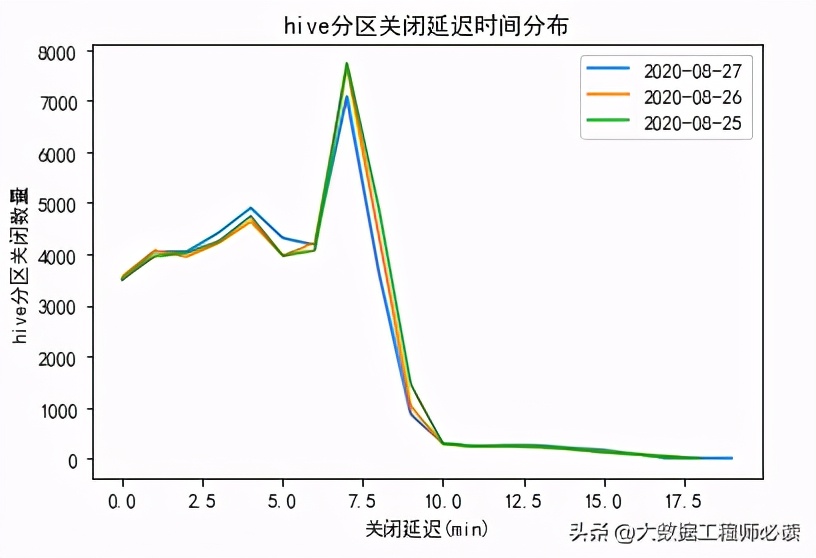
圖3 優化后hive入庫延遲時間分布
有效降低了成本和資源的投入,包括hdfs存儲資源、統一調度資源、hive資源、gaia計算資源等。
很自然地解決了數據遲到問題,不論遲到多久的數據都可以安全入庫,同時也允許其他渠道來源的數據寫入。
降低了系統復雜度,入庫不再需要統一調度的支持,不再依賴運維側的一些腳本。
通過oceanus統一管理了歷史checkpoint、資源、權限、任務啟停等,并將TDSort運行在gaia上,從而更便于運維和維護。
四、其他接入挑戰的解決實踐
1. 高流量和易運維性
對topic內的數據抽象了tid的概念,每個tid和一個hive表關聯,每條數據歸屬于一個tid,這樣就可以在一個topic內接入多個hive表的數據。
基于zookeeper做了配置服務,這樣可以動態的下發配置和感知變動,并動態的接入新的topic。
接入服務TDSort基于流式數據處理領域最流行的flink開發,采用如下的拓撲結構:
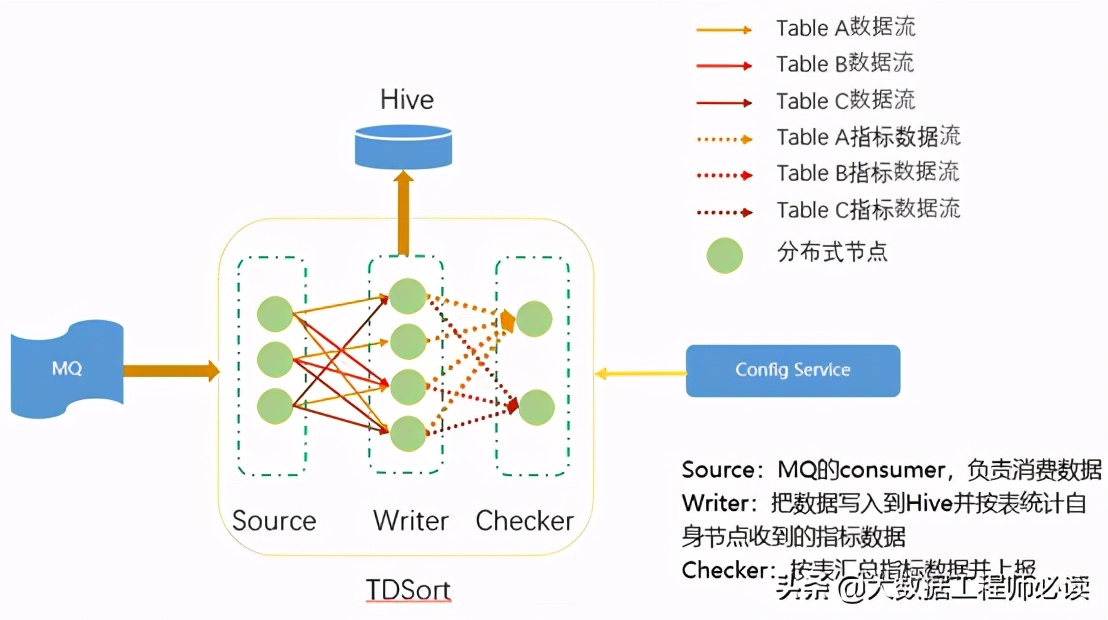
圖4 TDSort拓撲結構
2. 接入延遲和數據碎片
定義單個文件最大大小和最大數據延遲兩個維度,業務根據需要進行配置。
對接入延遲容忍度較低的業務,通過小文件壓縮任務定期對小文件進行合并。
3. 異常處理和數據一致性
Source側:Checkpoint時保存MQ的offset信息,這樣異常時就可以從前一個成功的checkpoint進行恢復。
Sink側:對落地的HDFS文件名進行特意設計,這樣我們從checkpoint恢復進行rollback時才能知道哪些文件是可以被安全刪除的。這里不能根據文件的修改時間戳進行判斷,因為每個gaia節點的時鐘并不一定是完全一致的,而HDFS的性能也會有抖動導致上傳文件有延遲。
需要優先確保服務的可用性,而異常回滾是一個耗時的操作,故設計為異步的,保證數據的最終一致性。
運維下發停止命令后可以停止MQ消費,并將on the fly的數據排干后再停止應用,這樣可以有效降低下次啟動時巨大的checkpoint恢復成本。
遇到HDFS故障時可以將本地磁盤作為暫存,這樣可以避免checkpoint因超時失敗的問題,并有效降低下次啟動時巨大的checkpoint恢復成本。
4. 指標統計
如圖4所示,TDSort由source、writer、checker三級vertex構成,其中checker按照期望的維度對指標進行匯聚(相當于sql中的group by后組內進行sum),進而可得到相應的指標數據。
存儲每條指標數據時,同時存儲checkpointId和指標發送時間,這樣在rollback時根據checkPointId和指標發送時間刪除相應記錄即可。
5. 數據(負載)傾斜
仔細觀察會發現,流量傾斜主要發生在Source和Writer節點之間。如下圖所示,對于每個gaia集群,我們引入了稱之為Router的協調者。每個節點會定期上報IO相關的負載信息到Router,Router會根據最近一段時間的流量情況判斷是否有機器的IO高于設定的閾值,如果是的話則找出發數據過來的Source節點,從中找出流量最大的數據通道并進行分裂,將數據分發到負載較低的節點上去,實現IO的負載均衡。

圖5 Router調整數據路由過程
6. 故障轉移
TDSort可根據運維下發的指令動態停止某一些Source或者Writer而又不用重啟整個應用,這在某些機器故障的情況下非常有用,可以避免成本較高的應用啟停,并實現人為控制下的故障和流量轉移。
7. Sink(HDFS)性能抖動
使用本地磁盤作為暫存,在HDFS性能抖動時將數據存入本地磁盤,不堵塞數據接入,并使checkpoint快速通過。
每個節點通過常駐的uploader上傳文件,這樣可在sort停止后將殘留文件也上傳到HDFS,確保不丟失數據。
五、總結
新的接入方案在接入成本、接入延遲上都有了較為明顯的優化效果,減輕了對統一調度系統的負載壓力,并具備了端到端的業務對賬能力。在公司開源協同的大背景下,TDBank的hive數據實時接入方案已經應用在pcg數據的接入中,并將逐步替換pcg現有的基于atta的數據接入。對TEG信安數據的接入目前也在進行中,后續我們還計劃對現網存量的TDBank數據接入任務也進行遷移。
原文鏈接:https://developer.aliyun.com/article/778464





