
商品的信息結構化程度在某種意義上來說決定導購效率的天花板。閑魚商品結構化和淘寶/天貓最大的區別在于閑魚賣家都是個人用戶,無論是專業程度還是行動力遠不及淘寶賣家。為了不阻礙商品發布,閑魚一直倡導輕發布,理想狀況用戶拍完照片輸入一段描述即可完成發布。但是這和商品結構化相悖:賣家輸入信息越多,越有利于商品結構化,但是用戶發布商品的意愿就會越低。我們要做的就是在不阻礙用戶發布商品的前提下提高商品結構化程度。
結構化歷程
閑魚商品結構化的探索一直沒有停過。目前為止,可以劃分出四個階段

-
2016年及以前:利用文本挖掘算法,從用戶輸入的標題/描述中提取出結構化信息。
-
2017年:文本屬性依賴用戶輸入。遺憾的是大部分閑魚用戶輸入相當"簡潔"。于是我們把目光轉向圖片:1)從商品圖片中提取結構化信息。2)根據商品圖片預測商品類目。
-
2018年:2018年以前閑魚類目處于刀耕火種的原始狀態,發布時需要選擇商品應該在哪個類目之下。所以我們建立了閑魚渠道類目,將類目映射到渠道類目。另一個嘗試就是將閑魚商品直接與天貓的SPU(Standar Product Unit,標準產品單元)映射。
-
2019年:啟動了哥倫布項目,進一步挖掘圖像潛力。通過圖像相似度識別,直接將閑魚商品和淘寶/天貓商品進行關聯,通過對淘寶同款的結構化信息清洗得到閑魚商品的結構化信息。
當前結構化策略
目前圍繞著算法,我們在商品發布的各個環節都提供了同款關聯的入口:從智能發布到發布完成之后的算法識別以及售賣體系。

現階段閑魚商品結構化圍繞著算法,在商品發布的各個環節都提供了同款關聯的入口:從智能發布到發布完成之后的算法識別以及售賣體系。
-
端側智能發布。商品發布過程中,充分利用端側計算能力,將商品結構化的產品問題,轉變成同款商品匹配這樣的技術問題。模糊檢測,相似度檢測,主體識別這些算法都是在端側實現的。
-
算法圖像識別。商品發布完成后,借助圖像識別算法,對于精度較高的識別結果直接和商品建立映射關系。
-
售賣項目。當圖像識別算法只能縮小范圍而無法精確給出結果時,借助于售賣任務體系,可以讓用戶選擇完成同款關聯。
通過同款關聯,閑魚商品結構化往前走了一大步,使得閑魚商品結構化的比例有將近47%的提升。盡管如此閑魚商品結構化現狀仍不容樂觀,主要體現在
-
同款覆蓋率。覆蓋雖然提升比例較大,但離目標還有一定的距離。
-
同款精度。1)部分類目精度低,比如手機和手機殼在圖像上相似,但實際是不同的商品。2)整體精度離目標仍有較大gap。
-
結構化信息應用。目前只應用在了搜索場景的商品擴招回,結構化信息的應用仍有待充分挖掘。
未來的打法
當前結構化策略面臨著一個問題:當算法能力達到上限后,如何繼續推進結構化覆蓋&精度提升?目前為止起碼有三種手段
-
算法多模態。集團有著眾多在各自領域深耕的圖像算法團隊,比如在女裝等垂直類目上沉淀深厚的專家系統。融合多算法團隊能在一定程度上提升算法能力的天花板。
-
文本識別。在下面的case中,單純憑借圖片無法識別是否是同款,因為圖像確實非常相似,這個時候就需要文本的輔助。

-
輸入輔助。文本識別模型依賴用戶的輸入。輸入輔助引導用戶輸入更多高質量文本的同時降低用戶描述成本。另一方面輸入輔助也可以承擔部分屬性補全的能力。
然而在現階段以算法為中心的工程體系中,上面的策略應用上會面臨很多痛點
-
如何定義結構化。本質上是結構化標準的問題,一方面相同的商品算法識別出來的結果千差萬別,相同的商品不同算法識別出來的結果最終如何歸一化成相同的同款。另一方面對于算法覆蓋不到的領域如何通過其他手段來完成結構化。
-
算法多模態接入成本飆升。如何抹平多算法之間的差異,算法對大盤的貢獻,各個算法之間的效果快速上線對比?
-
輸入輔助。輸入輔助需要解決2個問題:1)輸入聯想素材池來源。2)用戶體驗,輸入輔助對實時響應有著非常高的要求。
這些問題大部分本質還是工程問題(結構化定義,多算法融合,輸入輔助等)。所以轉換一下結構化思路:以算法為中心轉向以工程為中心,把算法當作能力補齊插件。結構化圍繞著屬性補齊做如下抽象
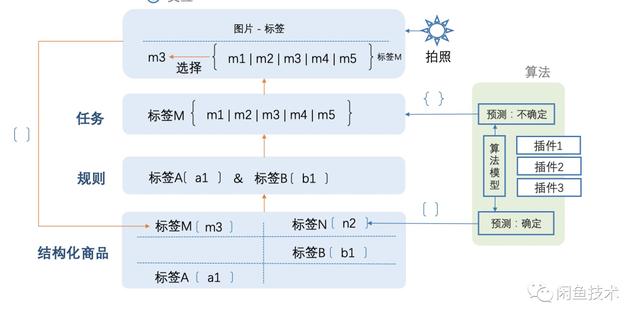
總體策略
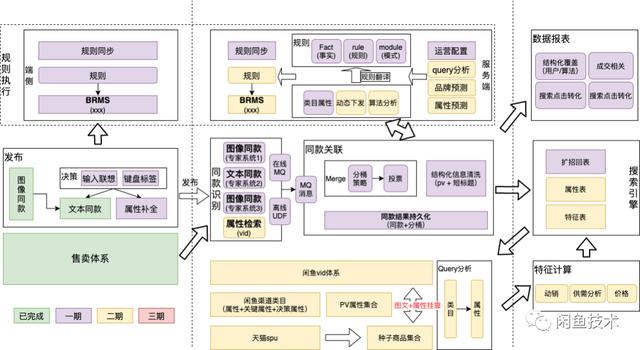
總結起來做這幾件事
-
閑魚vid體系重新定義結構化標準。
-
算法多模態接入,提升覆蓋&精度。
-
引入規則引擎,服務于輸入輔助等場景。
-
結構化數據持久化&特征計算,提升搜索推薦等導購場景的匹配效率。
重新定義結構化
定義結構化的標準,一方面可以抹平多算法接入帶來的差異,另一方面對于拓展算法邊界也有重要意義。所以重新給商品結構化下一個定義:如果一個商品的關鍵屬性都有,那我們認為這個商品就是結構化的。

這套標準稱為閑魚vid(想好名字前暫且叫vid)體系,基于閑魚渠道類目+屬性組成。這套標準有兩種方式生成
-
天貓spu體系。天貓的spu運營到現在,數據體系已經較為完善,標準品類和閑魚有很大重疊部分,這部分可以直接實現spu互通。
-
對于非標品,從需求側分析而來。通過搜索推薦等導購場景反向分析可以拿到當前買家關心的品類+屬性。這部分可以補齊SPU缺失的數據。
基于這套標準體系,可以很好的解決多算法接入問題:直接以vid體系對應的種子商品集為候選池,實現同款掛靠。除此之外,算法沒法覆蓋的商品(圖文質量較差)如果能確定類目和屬性,也能實現vid掛靠。
算法多模態
工程上主要解決算法接入效率問題。當從商品發布到最后的導購主鏈路搭建完成,算法以插件化的方式運行在主鏈路之上。

這里多模態主要包括兩方面:1)識別能力從圖像擴展到文本,圖文結合。2)算法模型從單團隊拓展到多團隊,能力互補。解決的問題主要包括
-
屏蔽數據差異。不同算法數據產生方式的差異,實時/準實時/離線。
-
數據融合。算法快速上線/數據效果對比/結構化信息入引擎。
-
算法結果對齊。根據定義的結構化標準,抹平算法結果差異。如果識別出的同款商品本質上是同一個商品,那多算法的識別結果最終應當能歸一化。
輸入輔助
輸入輔助需要解決兩個問題:
-
聯想素材池來源:用戶輸入具有持續時間很短的特征,所以在較短時間內輔助用戶進行有價值的輸入很關鍵。
-
用戶體驗:嚴苛的實時性要求。用戶輸入是一個連續且對時效要求極高的過程,所有數據的交互需在極短時間內完成。
第一個問題很好解決,素材池提煉可以包括:
-
搜索逆向分析產出。根據用戶query統計分析,可以得到買家關心的屬性。
-
算法產出:算法對動銷高的商品進行特征提取得到,并歸到對應的渠道類目上。
-
運營行業經驗產出。
第二個問題最好的解法肯定是把所有的邏輯全部下放到端上本地執行避免響應問題。然而不可能把所有的邏輯放到端上,比如需要算法介入時,我們不可能把復雜的算法模型運行在端上。所以把素材池分成兩部分:
-
需要算法介入的邏輯放在服務端來完成。
-
其余邏輯選擇適當時機下發給端上執行,這部分需要保證良好的擴展能力。
通過對輸入輔助的執行邏輯進行抽象發現其存在形式類似于規則引擎中的規則。在規則引擎中規則一般包含三要素:事實,規則,模式。

這里的事實對應著用戶的輸入,module對應著單個判定條件,rule則對應著條件判定以及對應的action。以運營的行業經驗產出為例,手機類目下有兩個很重要的屬性:1)是否維修過。2)是否過保。那這條經驗可以翻譯成兩條規則:1)IF類目=手機AND屬性不包含 是否維修過THEN引導用戶選擇。2)IF類目=手機AND屬性不包含 是否過保THEN引導用戶選擇。當執行邏輯被抽象成若干條規則時,就可以在適當的時機下發到客戶端側本地執行。整個流程抽象如下

當新的運營經驗或者分析數據產生時,通過翻譯成規則可以很好的實現輔助輸入的擴展性。通過規則的共享,客戶端的邏輯可以無感知的在服務端執行。
上線效果
商品結構化的目標圍繞著結構化信息的覆蓋&精度進行,目前已經上線了部分功能(文本同款以及算法多模態),從數據上看取得了不錯的效果:
-
算法多模態接入能對結構化覆蓋占比8%絕對提升。
-
文本同款正在分桶測試中,從分桶數據來看覆蓋上漲13%絕對值提升。
展望
結構化的愿景是在不影響發布體驗的前提下完成商品結構化工作。理想情況下只需要一張照片,一段描述就能完成商品發布,其余工作統統移交給算法以及工程同學。當圖像和文本內容能被充分挖掘理解,標簽成色甚至類目這些都可以去掉,用戶只需要點確認發布按鈕即可。我們會不斷朝著這個目標努力。
閑魚技術團隊不僅是阿里巴巴集團旗下閑置交易社區的創造者,更是移動與高并發大數據應用新技術的引導者與創新者。我們與google Flutter/Dart小組密切合作,為社區貢獻了多個高star的項目和大量PR。我們正在積極探索深度學習和視覺技術在互動、交易、社區場景的創新應用。閑魚技術與集團中間件團隊共同打造的FaaS平臺每天支持數以千萬級用戶的高并發訪問場景。





