

傳統(tǒng)的數(shù)據(jù)開放共享方式,很多是將原始數(shù)據(jù)以明文的方式直接輸出,這樣在數(shù)據(jù)安全和隱私保護方面存在顯著風(fēng)險,不符合日益完善的法律法規(guī)要求,也越來越不能滿足當(dāng)今數(shù)據(jù)體量、規(guī)模日益龐大而復(fù)雜的應(yīng)用需求。另外,也存在加工為標(biāo)簽類的數(shù)據(jù)再進行輸出的方式,但通常存在信息漏損,使用這類數(shù)據(jù)進行建模,效果大打折扣。

經(jīng)過實踐,TalkingData 借助機器學(xué)習(xí)技術(shù)探索出一套新的方案,通過對原始數(shù)據(jù)進行分布式的隱含表征提取計算(一種數(shù)據(jù)變換方式),再將變換后的數(shù)據(jù)用于開放共享,既可以滿足數(shù)據(jù)輸出的安全性要求,又提升了大數(shù)據(jù)輸出的處理速度。該數(shù)據(jù)輸出方式主要基于機器學(xué)習(xí)的分布式 embedding 算法(嵌入算法)。Embedding 算法是一系列算法的統(tǒng)稱,該類算法能夠?qū)υ紨?shù)據(jù)進行變換,并挖掘其中的潛在關(guān)聯(lián)。Embedding 算法處理后的數(shù)據(jù)由于信息漏損較少,相對標(biāo)簽數(shù)據(jù)有更好的建模效果,被廣泛用于推薦系統(tǒng)、自然語言處理等領(lǐng)域。
TalkingData 將該類算法應(yīng)用到數(shù)據(jù)安全輸出領(lǐng)域,使得原始數(shù)據(jù)在經(jīng)過變換后,能夠以不具備可識別性的方式輸出,而數(shù)據(jù)獲取方無法從中提取到與個人身份相關(guān)的敏感信息,也就實現(xiàn)了對隱私數(shù)據(jù)的匿名化保護。
基于保護用戶隱私、保障數(shù)據(jù)輸出安全性以及提升大數(shù)據(jù)輸出處理速度的考量,構(gòu)建了 TalkingData System 平臺(以下簡稱 TDS)。TDS 平臺的底層基于 Spark 和 Hadoop 生態(tài)搭載了 embedding 算法,對原始數(shù)據(jù)進行計算和處理,再將結(jié)果通過前端平臺頁面輸出給企業(yè)用戶,目前已經(jīng)在金融、零售、互聯(lián)網(wǎng)、廣告等行業(yè)中得到應(yīng)用。
借助 TDS 平臺,企業(yè)可以將內(nèi)部來自垂直領(lǐng)域的第一方數(shù)據(jù),比如用戶群體的活躍、消費、人口屬性標(biāo)簽等,與 TalkingData 的第三方數(shù)據(jù)進行融合,豐富企業(yè)的自有模型特征維度。理論上,不需要業(yè)務(wù)解釋或識別的預(yù)測模型均可使用本方法輸出的數(shù)據(jù)。
1.1 算法方案詳解
本算法具有通用性,可以應(yīng)用于任何能變換為標(biāo)準(zhǔn)格式的原始數(shù)據(jù)輸出。下面通過一個示例詳解說明處理過程:
1.TDS 平臺的使用方上傳了一批設(shè)備 ID(設(shè)備標(biāo)識),通過 ID 匹配,得到對應(yīng)的 TDID(即 TalkingData 自有的加密標(biāo)識符)。
2. 使用 TDID 作為索引,提取原始數(shù)據(jù)。假設(shè)有 M 個 TDID,TDID 可以看作每一臺智能移動設(shè)備的虛擬唯一編號,則提取后的原始數(shù)據(jù)共有 M 行,每行對應(yīng)一個設(shè)備的屬性信息。假設(shè)屬性個數(shù)為 N,每個設(shè)備的每個屬性值為 1 或 0,代表一個設(shè)備具有或不具有某個屬性。將該原始數(shù)據(jù)變換為 M*N 的稀疏矩陣,每行對應(yīng)一個設(shè)備,每列對應(yīng)一個屬性。例如第三行第五列為 0,則表示第三個設(shè)備不具有第五列對應(yīng)的屬性。
稀疏矩陣相對普通矩陣來比,能夠極大的節(jié)省存儲空間。構(gòu)造稀疏矩陣的方法可以理解為以下步驟:
(1)創(chuàng)建一個 M*N 的矩陣,將其中的值全部填充為零。
(2)逐行掃描,如果一個設(shè)備具有某個屬性,就將該處的值替換為 1,直到掃描完成。
(3)記錄哪些行和哪些列的數(shù)據(jù)為 1,存儲這些信息。存儲下來的這些信息,實際上就是一個系數(shù)矩陣。
3. 通過嵌入模型對標(biāo)準(zhǔn)格式的原始數(shù)據(jù)進行表征學(xué)習(xí)。實際上就是對輸入的原始矩陣進行分解。嵌入模型可以使用的算法很多,此處以奇異值分解 SVD(Singular Value Decomposition)算法為例進行介紹。
提到 SVD,就不得不提到與其相關(guān)的概念——PCA(Principal Components Analysis),即主成分分析,又被稱為特征值分解。關(guān)于 PCA 方法,大家的普遍聯(lián)想是降維 。簡單來說,PCA 所做的就是在原始空間中順序地找一組相互正交的坐標(biāo)軸,第一個軸是使得方差最大的,第二個軸是在與第一個軸正交的平面中使得方差最大的,第三個軸是在與第 1、2 個軸正交的平面中方差最大的。這樣,假設(shè)在 N 維空間中,我們可以找到 N 個這樣的坐標(biāo)軸,我們?nèi)∏?r 個去近似這個空間,這樣就從一個 N 維的空間壓縮到 r 維的空間了,而我們選擇的 r 值對空間的壓縮要能使數(shù)據(jù)的損失最小。
PCA 從原始數(shù)據(jù)中挑選特征明顯的、比較重要的信息保留下來,這樣一來問題就在于如何用比原來少的維度去盡可能刻畫原來的數(shù)據(jù)。同時,PCA 也有很多的局限,比如說變換的矩陣必須是方陣,而 SVD 算法能夠避免這一局限。
SVD 算法,能夠?qū)⒁粋€矩陣分解為三個子矩陣(三個子矩陣相乘可以還原得到原始矩陣)。我們將這三個矩陣稱為 U、Sigma 及 V,其中 Sigma 矩陣為奇異值矩陣,只有對角線處有值,其余均為 0。
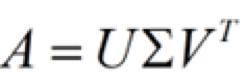
假設(shè)原始矩陣是 10,000 行 1,000 列,那么分解后即可得到如下三個子矩陣:
- U 矩陣為 10,000*10,000
- Sigma 矩陣為 10,000*1,000(除了對角線的元素都是 0,對角線上的元素稱為奇異值)
- V(^)T 矩陣(V 的轉(zhuǎn)置)為 1,000*1,000
實際應(yīng)用過程中,我們只保留 U 矩陣的前 512 列,于是三個矩陣的維度就變成了:10,000*512,512*512,512*1,000。為什么是保留 512 列呢?原因是奇異值在矩陣Σ中是從大到小排列,而且奇異值的減小特別快,在很多情況下,前 10% 甚至 1% 的奇異值之和,就占了全部奇異值之和的 99% 以上了。根據(jù)我們的多次實驗,512 列已經(jīng)能夠很好的保留奇異值的信息。
4. 矩陣分解得到三個子矩陣后,將 U 和 Sigma 相乘,得到輸出矩陣。輸出矩陣的維度為 10,000*512。可以看到,輸出矩陣與輸入矩陣有著相同的行數(shù),每一行仍舊代表一個設(shè)備。但是輸出矩陣的列數(shù)變?yōu)榱?512,與原始矩陣中每一列是一個屬性不同,此時的輸出矩陣中每一列對應(yīng)一個特征。該特征不具備可解釋性和可識別性,這也就保證了輸出數(shù)據(jù)不會泄露個人隱私。
5. 將輸出矩陣直接輸出,TDS 平臺的使用方可以通過數(shù)據(jù)接口進行調(diào)用。因為平臺使用方無法獲得 V 矩陣,故而無法還原得到原始矩陣,也就無法還原出任何與個人相關(guān)的原始屬性信息。
輸出時,需要將所有的數(shù)據(jù)先整理成步驟 2 中的標(biāo)準(zhǔn)輸入格式,然后拼接成一個輸入矩陣。之后的步驟與上述示例中相同。
1.2 效果
對于 Embedding 算法在數(shù)據(jù)安全輸出的實際表現(xiàn),TalkingData 做了很多相關(guān)實驗,也在多個實際項目中進行了驗證。以下用兩個真實案例進行說明:
案例一:性別標(biāo)簽預(yù)測效果提升
性別標(biāo)簽是基于設(shè)備信息通過機器學(xué)習(xí)模型預(yù)測打分得出的。在過往的建模過程中,算法人員往往會對原始信息進行一定的處理,比如將非結(jié)構(gòu)性的數(shù)據(jù)處理為結(jié)構(gòu)性的統(tǒng)計數(shù)值,或者將其他標(biāo)簽作為特征輸入到模型中。但是,這些特征工程方法都會產(chǎn)生一定的信息漏損或者誤差引入。
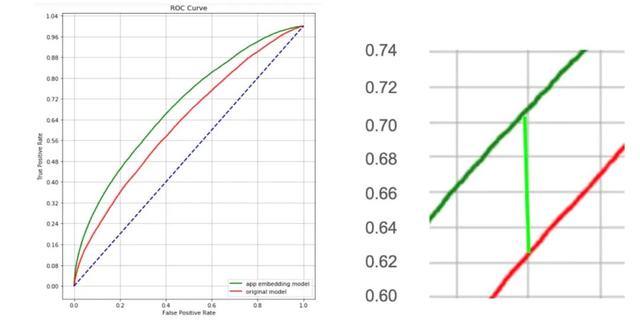
而 Embedding 處理后的數(shù)據(jù)相比人工的特征篩選,由于信息漏損較少,理論上會取得更好的建模效果。從以下兩圖可以看出,基于相同原始數(shù)據(jù),使用 Embedding 模型的預(yù)測效果比原始性別預(yù)測模型提升 (0.71 - 0.63)/0.63 = 13.7%。
案例二:某金融企業(yè)的風(fēng)控模型預(yù)測效果提升
在與很多企業(yè)的合作中,會將 TalkingData 的人口屬性標(biāo)簽和應(yīng)用興趣標(biāo)簽作為第三方數(shù)據(jù)引入。在與某金融企業(yè)的合作中,TalkingData 將數(shù)據(jù)通過 TDS 輸出給該企業(yè)并應(yīng)用在風(fēng)控模型中。
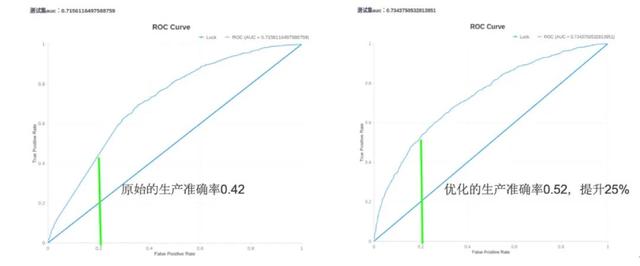
在相同的假陽率(False Positive Rate)下,企業(yè)原有算法的生產(chǎn)準(zhǔn)確率為 0.42,而加入 Embedding 算法輸出的數(shù)據(jù)后,經(jīng)過優(yōu)化的生產(chǎn)準(zhǔn)確率達(dá)到 0.52,提升 25%。在風(fēng)控領(lǐng)域中,25% 的提升能夠幫助企業(yè)避免很大的經(jīng)濟損失。
1.3 關(guān)于其他 Embedding 方法的思考
Embedding 方法被廣泛應(yīng)用于自然語言處理領(lǐng)域,也就是使用數(shù)學(xué)語言表示一篇文本。雖然上文提到的 SVD 算法的有效性在實際模型計算中被驗證了,但是在文本特征表示方面仍有缺陷。
首先,它是一個詞袋模型(BOW,bag of words),不考慮詞與詞之間的順序,而在實際文本中,詞語的順序也非常重要,而且每個詞在句子中的重要性各不相同;其次,它假設(shè)詞與詞之間相互獨立,但在大多數(shù)情況下詞與詞是相互影響的,這也是為什么我們在做“閱讀理解”的時候經(jīng)常要聯(lián)系上下文的原因。
如今 Embedding 領(lǐng)域早已向深度學(xué)習(xí)的方向衍化,大致可以分為以下四種常見應(yīng)用:
- 不依賴文本語法和語序的詞袋模型:one-hot、tf-idf、textrank 等;
- 主題模型:LSA、pLSA、LDA;
- 基于詞向量的固定表征:word2vec、fastText、glove
- 基于詞向量的動態(tài)表征:elmo、GPT、bert
其中,Word2vec 是獲得工業(yè)界廣泛應(yīng)用的算法之一。提到 Word2vec 就不得不引入“詞向量”的概念。NLP 領(lǐng)域中,最細(xì)粒度的是詞語,詞語構(gòu)成句子,句子再組成段落、篇章、文檔。如何用數(shù)學(xué)語言表示每一個詞語,成為研究詞與詞之間關(guān)系的關(guān)鍵。Word2vec 正是來源于這個思想,可以把它看作是簡單化的神經(jīng)網(wǎng)絡(luò)模型,但是它的最終目的,不僅僅是用數(shù)值表示文本符號,還有模型訓(xùn)練完后的副產(chǎn)物——模型參數(shù)(這里特指神經(jīng)網(wǎng)絡(luò)的權(quán)重)。該模型參數(shù)將作為輸入詞語的某種向量化的表示,這個向量便稱為——詞向量。
舉例子說明如何通過 Word2vec 尋找相近詞:
結(jié)合 TalkingData 應(yīng)用 Embedding 的實際場景,與詞向量的最大區(qū)別就是被表示的特征之間沒有上下文的聯(lián)系。TalkingData 以分析移動設(shè)備行為數(shù)據(jù)為主,對大多數(shù)設(shè)備屬性來說,打亂排列的順序?qū)τ趯嶋H意義來說沒有任何影響,但是一個句子里面的詞語是不能被打亂順序排列的,句式結(jié)構(gòu)對于詞向量表示來說是非常重要的。基于實際業(yè)務(wù)場景的考量,我們沒有選擇用 Word2vec 或更復(fù)雜的 Embedding 算法來轉(zhuǎn)換原始數(shù)據(jù)。
雖然,我們保證了原始數(shù)據(jù)輸出的安全性,但是伴隨而來的是數(shù)據(jù)可解釋性較弱的問題。由于 Embedding 算法將原始數(shù)據(jù)轉(zhuǎn)化為了另一個空間的數(shù)值向量,因此無法人為理解或者賦予輸出矩陣的每一列的實際含義。
假設(shè)建模人員構(gòu)建一個“工資預(yù)測回歸模型”,采集到的樣本特征包括“性別、年齡、學(xué)歷、工作城市、工作年限…”,分別對應(yīng)數(shù)據(jù)集中的每一列,那么他們可以容易的計算得到每個特征的權(quán)重,并且能夠比較哪個特征的權(quán)重較高,即特征重要性的排序,得到諸如“工作年限對工資高低的影響比性別更重要”這樣的結(jié)論。
但是在使用 TDS 平臺輸出的數(shù)據(jù)構(gòu)建模型的時候,我們沒辦法向上述模型一樣分析比較每一列特征對模型的影響,只能得出增加 Embedding 特征對于模型效果是否有提升這樣粒度較粗的結(jié)論。顯然,如果建模人員對于模型的解釋性有特別嚴(yán)苛的需求的話,TDS 平臺暫時沒有辦法提供解決方案。
作者簡介:
周婷,TalkingData 數(shù)據(jù)科學(xué)家,專注移動大數(shù)據(jù)的深度挖掘和基于 Spark 的機器學(xué)習(xí)平臺開發(fā),為 TalkingData 智能營銷云和數(shù)據(jù)智能市場提供算法支持,主要負(fù)責(zé)精準(zhǔn)營銷預(yù)測、企業(yè)級用戶畫像等產(chǎn)品的算法研發(fā),長期關(guān)注互聯(lián)網(wǎng)廣告、金融營銷、反欺詐檢測等領(lǐng)域。





