
老海分享了關數據分析工具選擇的理解和建議,而今天,老海想回到實際操作角度來聊聊。
作為?數據分析師,我們日常工作中使用的最多自然是SQL查詢,是真正的“金剛鉆”本領。
通常包括了Spark SQL、Hive SQL、MySQL等等,我們主要通過它們提取數據庫中的數據記錄。
而在處理一些外部數據時,如TXT文本數據、CSV日志數據等,SQL沒有Excel或者Python來的靈活。
如果需要把數據進行報表化、可視化,我們又會偏向使用PowerBI或者Tableau這類商業BI工具。
這些工具之間的設計思路、運行原理、編寫語法、操作步驟等等,的確存在著很大不同點。
但是它們又有著最大的共同點:必須圍繞我們的目標需求來執行,否則再強的工具也毫無意義而言了。
比如你要篩選出天津市的銷售訂單,你無論用何種工具方法,都得把訂單給找出來,整別的都沒用的!
所以,在解決問題這點上,它們沒有不同,更沒有強弱之分。
選擇分析工具,不是看誰功能多,而是看誰能解決問題!
面對同一目標,四大數據分析工具都是如何操作的呢?
實際工作中,我們經常在不同工具間來回切換,或者同時配合使用幾種工具
因此我們總是需要不斷記憶和搜索相關的操作步驟,這是一個很繁瑣又浪費時間的過程。
為了徹底解決這個問題,本次老海把四個工具放在一起,同步橫向對比:
在相同目標要求下,Excel、MySQL、Power BI、Python 四大數據分析工具的操作要點
比如:篩選出天津市的銷售訂單,這四種工具各自都是如何具體操作的,盡量做到一目了然!
與某種工具的深度文章不同,此次主要是常見步驟的操作對比,是操作方法的大集合。
本次內容由老海獨家編輯整理,整個過程相當耗時,由于內容較多,計劃分為上中下三篇完成。
感興趣的朋友,可以關注我,收藏文章方便后期查找。
OK,我們下面來同步對比這些工具操作情況:
演示工具版本環境:
OFFCIE2013或2016,
MYSQL8.0以上,
Python3.7,
PowerBI 2020年5月版本
案例模擬數據情況:
本次依舊使用之前的模擬數據,與業務無關,僅供演示:
以下是涉及的表結構,共6張數據表,本文中主要涉及銷售數據表、產品表、顧客信息表
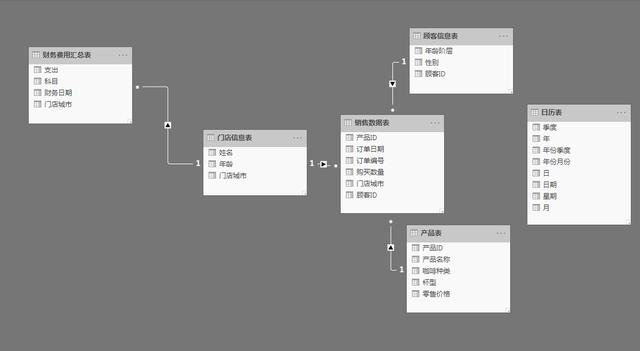
數據實例,如下圖所示:
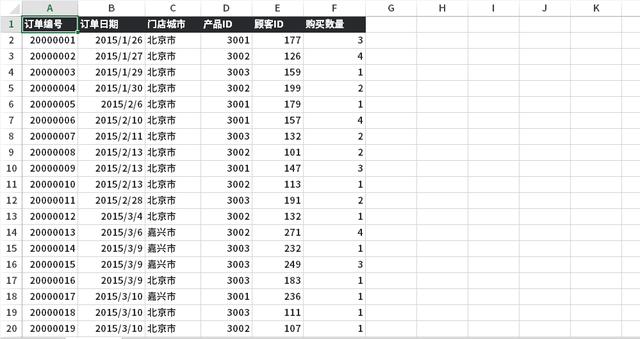
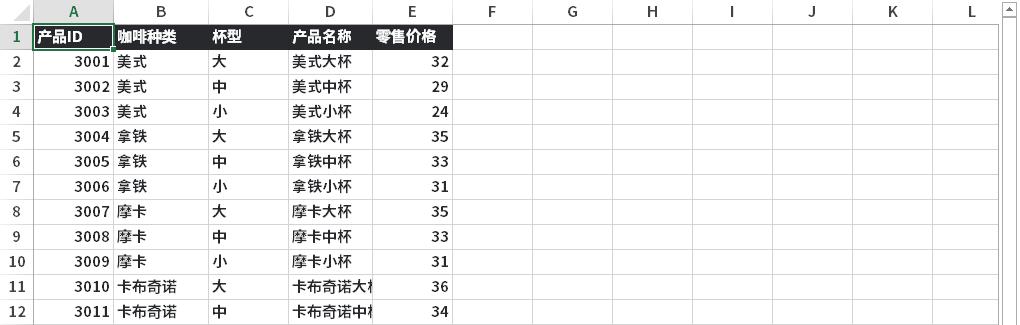
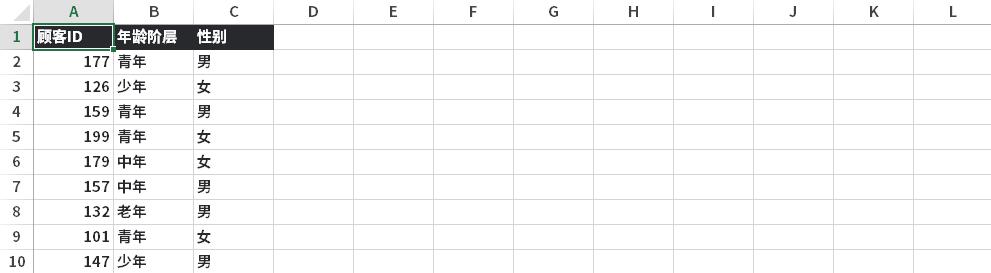
數據集相對比較簡單,容易理解。
OK,接下來,我們將按數據預處理的基本流程開始操作演示:
數據準備和導入
當使用Excel時:
- 沒啥說的,直接打開xlsx或者xls文件即可。
- 打開速度與你自己的電腦配置直接相關,同樣的配置情況下,筆記本的打開速度要大打折扣。
- 經常玩EXCEL數據比較大的同學,老海建議你上個臺式機吧,速度快還穩定,特別爽。
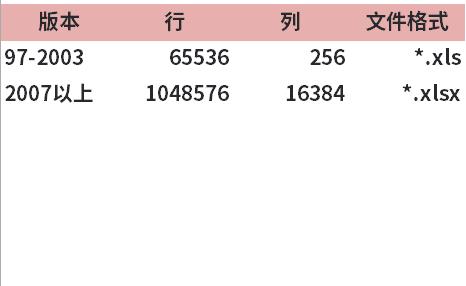
特別注意:Excel本身有數據記錄的數量限制,如果你的數據量很大,使用EXCEL文件類型,可能會造成數據讀取不全,以及各種卡頓報錯。
所以當數據量夠大的時候,建議直接更換其他工具,請不要在Excel上一路走黑。
當使用MySQL時:
我們一般可連接數據庫后臺,添加公司的主機、賬戶密碼登錄即可,一般公司局域網內使用
特別提示:MySQL8.0以后,登錄密碼編碼類型發生了變化,可能出現報錯
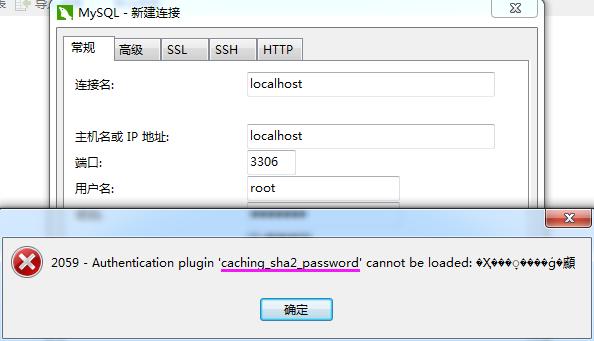
一般需要先啟動MySQL服務:

設置密碼、修改密碼編碼方式、刷新服務,三個步驟來解決

- 第一步:OK,這里我們使用本地搭建的環境,采用人工數據導入的方式
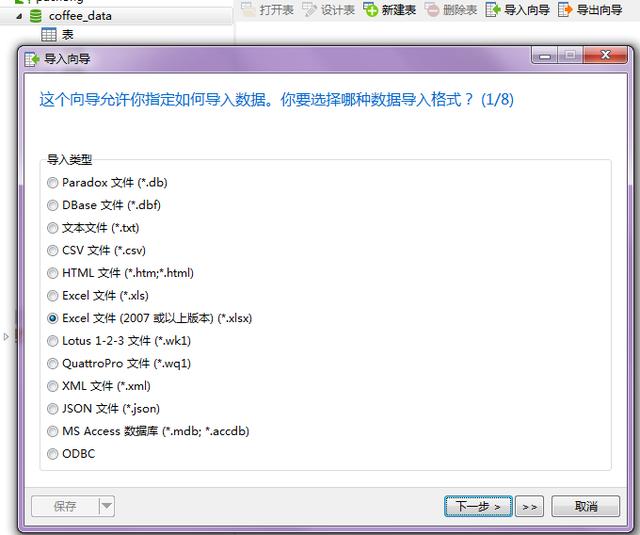
- 第二步:選擇相應的數據文件類型,一般為XLS、XLSX、CSV、TXT、JSON等等。
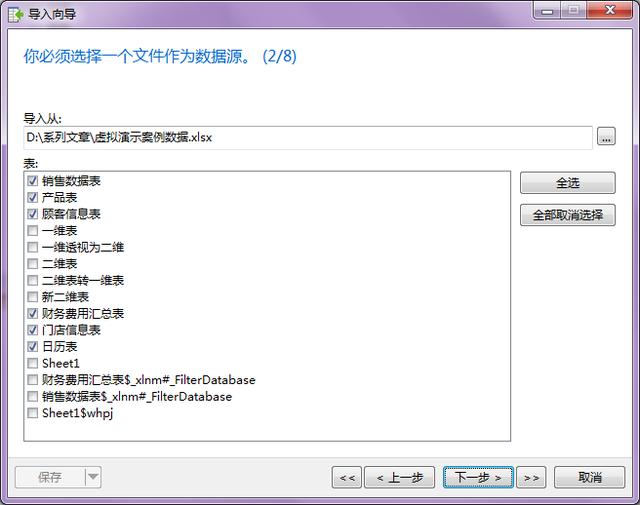
- 第三步:然后我們選擇數據源里的具體表格,比如這里我們選擇了6個表格
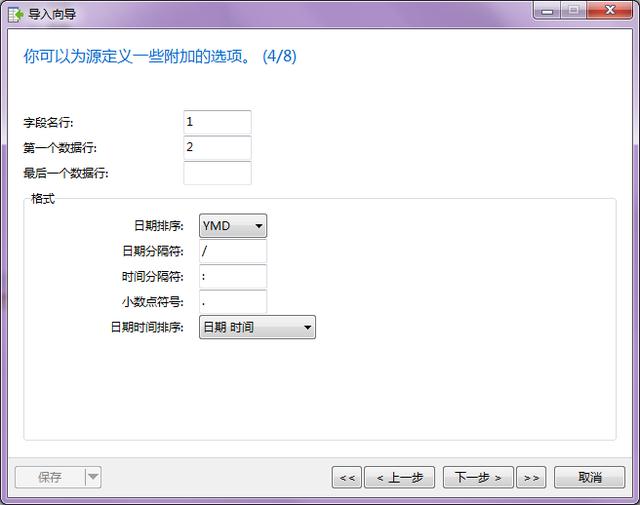
- 第四步:設置數據字段名稱行,一般都是第一行
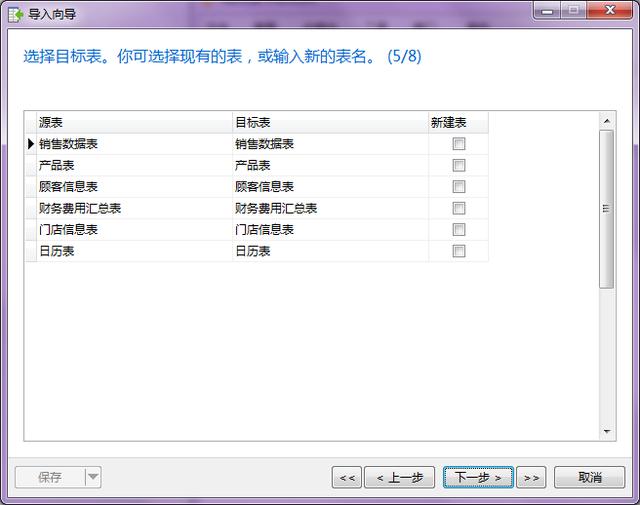
- 第五步:可以設置導入后表名,這里為了方便演示,就不再調整了。
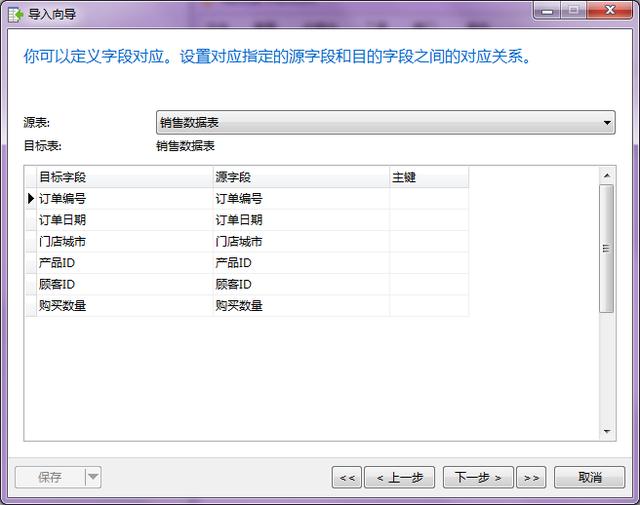
- 第六步:同樣可以設置導入表中的字段名稱,這里老海不再調整。
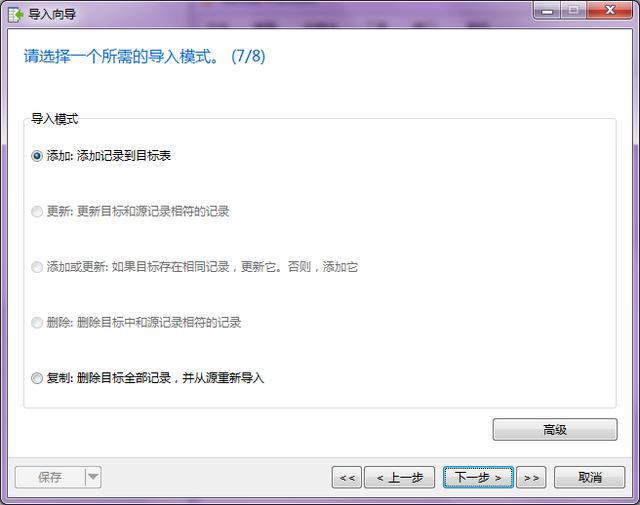
- 第七步:然后選擇導入模式,是添加、更新、還是復制,這里我們同樣選擇默認。
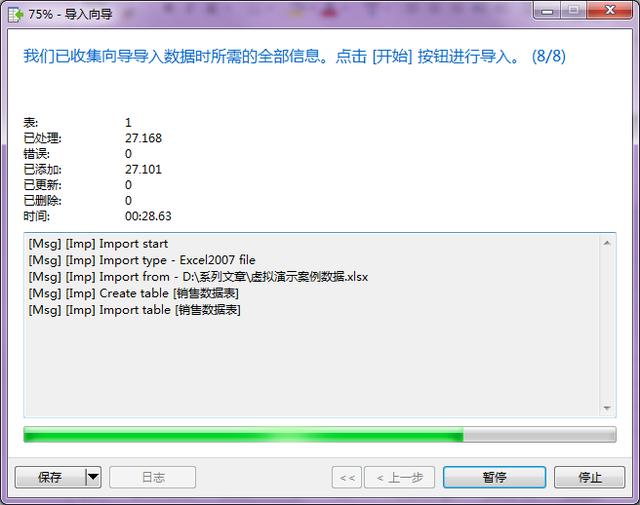
- 第八步:點擊“開始”按鈕,數據不大的話,很快就完成了。
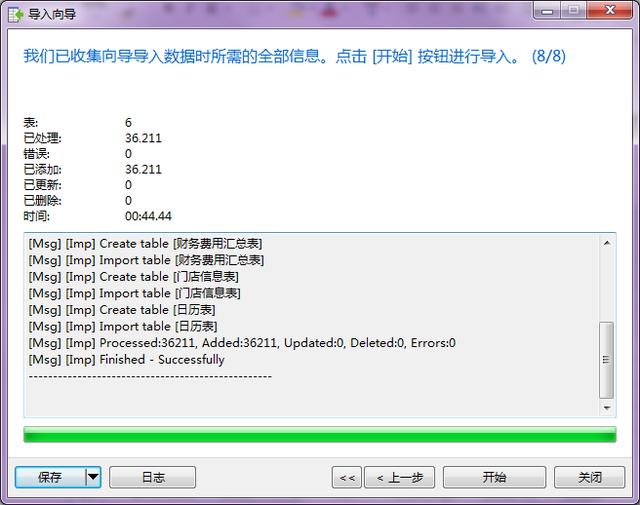
特別注意:當提示成功導入后,記得點擊“關閉”,而不是“開始”,不然又會重新導入
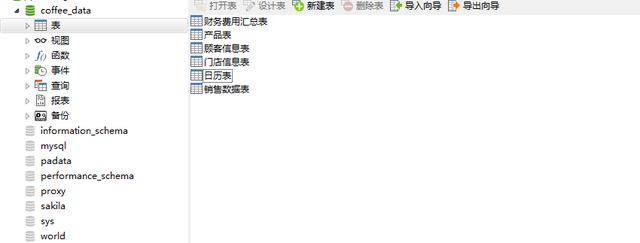
此時我們可以看到數據表已經導入成功了,還可以打開數據表看一下是否顯示正常。
當使用Power BI時:
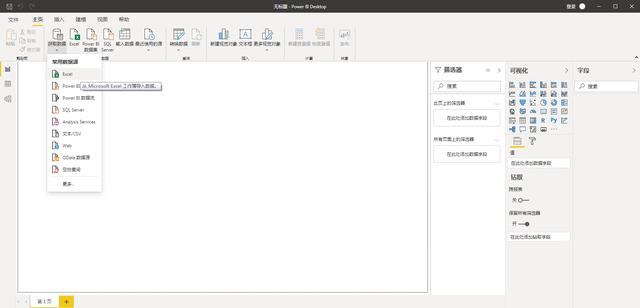
- 第一步:我們打開PowerBI,選擇“獲取數據”,選擇“常見數據源”中的Excel
- 第二步:然后選擇,需要導入的數據表,這里演示選擇了6個表格導入到數據模型里
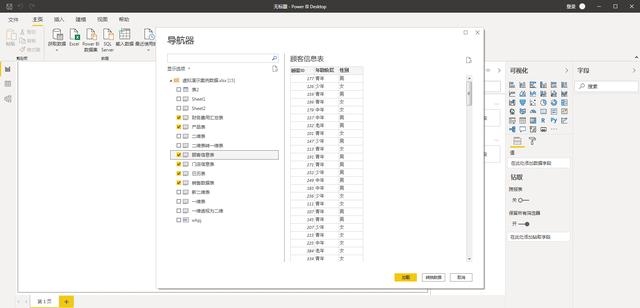
- 第三步:我們可以看到數據表里面具體的數據字段情況,檢查是否顯示正常。
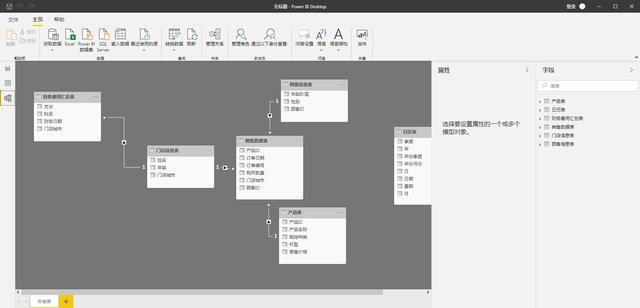
特別注意:PowerBI導入多個數據表格后,會自動選擇字段進行表格關聯,但這種關聯不一定是你實際業務的情況。
你要根據業務工作的實際情況來確定字段是否合理,關聯方式是否合理,比如是左連接、還是右連接等等。
使用Python:
- 第一步:我們先引入必要的pandas、numpy、sys等包,查看運行環境
- 第二步:然后設定好我們的工作路徑,這里是根據我們自己的情況來自行設置的。

- 第三步:最后我們引入需要處理的數據源

特別注意:當我們使用pandas讀取Excel表格數據時,默認會只讀取第1個sheet,因此當需要讀取特定的sheet時,請通過參數來指定完成。
另外pandas的讀取速度,與數據文件的大小、以及你自己設備的內存直接相關,當數據文件很大,比如10G,一般會受到你設備內存大小的影響,讀取速度變慢,此時考慮分批讀取或者使用SQL在服務器上處理。
OK,以上就是關于模擬數據背景、以及數據準備與導入的內容。
限于篇幅,上篇先介紹到這里,歡迎后續后續的2篇內容,涉及數據查看與篩選、更新與刪除、分組聚合、多表關聯、多表聯合、排序與分組、存儲與導出等操作。
本系列文章內容較長,建議隨手收藏下來,相信總有需要的時候!





