
隨著5G、AI、IoT等技術越來越普及,企業數據量增大,新的數據業務層出不窮,企業對數據分析的靈活性、性能、成本要求越來越高,基于傳統大數據Hadoop系統搭建的數據分析平臺已無法滿足企業多方面的要求。
近年來隨著云計算技術發展,越來越多企業選擇了以數據湖為中心構建大數據處理平臺,數據湖最明顯的特征就是存儲和計算分離,一方面可以使成本下降;另一方面,可以獲得更好的系統可擴展性。
采用數據湖架構,隨著企業業務增長,可以在一份數據上不斷增加新業務,而不是像傳統數據平臺那樣,每拓展一個新業務就要做一次數據拷貝。
每個硬幣都有兩面,數據湖方案除了低成本、易擴展的優點外,同時也有一些缺點:
1、無事務能力,數據入庫難!
傳統數據湖依賴云存儲,但云存儲一般都沒有ACID(Atomicity, Consistency, Isolation, Durability)事務能力,導致在此之上構建的Hive表格、Spark表格等不支持基于事務的數據入庫,更不用說數據更新了。
這個弊端極大制約了數據湖的使用場景,企業無法將不斷變化的數據快速注入到數據湖內。常常需要在業務層做大量預處理后,才能進入數據湖做分析,處理時延往往在一天以上。
2、分析性能依賴于暴力掃描,即費資源又太慢!
傳統數據湖存儲依賴云存儲,極大降低成本,但做數據分析時屬于暴力掃描方式,完全依靠云存儲自身的吞吐能力,這種方式只適用于ETL、批量計算等對時延不敏感的應用,無法支撐如秒級數據檢索、時序數據分析等低時延分析場景。
+ CarbonData,讓華為云智能數據湖真正成為企業數據架構的底座
為了解決這些問題,華為云基于云存儲+CarbonData構建的新一代數據湖,實現了 "實時數據接入"、"DB數據同步"、"高性能查詢和分析"等能力,填補了業界能力空白,使云化數據湖可以真正成為企業數據架構的底座。
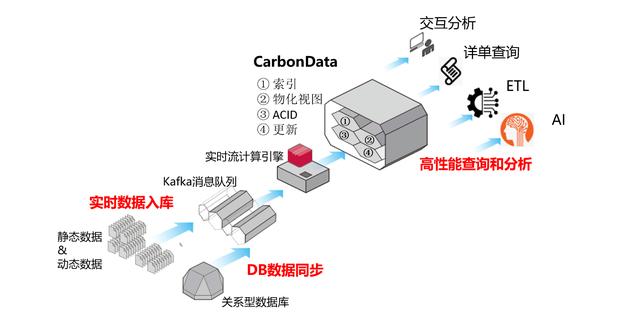
基于CarbonData的華為云數據湖方案如上圖描述,Kafka完成數據收集,由Flink、Spark Streaming等流計算引擎完成數據清洗、預處理等業務邏輯,將處理后的數據注入到CarbonData表格中;
繼而,用戶可使用Spark、Hive、Presto等大數據引擎對CarbonData表格進行交互分析、詳單查詢和ETL等業務;也可以使用TensorFlow、PyTorch等AI引擎進行AI模型訓練、推理等。
下面進一步闡述,加持CarbonData后,華為云智能數據湖的三大特點:
1、實時數據入庫
CarbonData增加了對 Flink 的支持,50行代碼輕松實現對接 Flink 以CarbonData的格式實現實時數據入庫。同時,CarbonData支持ACID事務能力,確保入庫操作的原子性和一致性。這使得CarbonData成為唯一一款兼具速度、靈活性和支持 ACID 事務特性的全場景數據湖。
2、DB數據同步
CarbonData支持Delta增量同步,相比Hive使用的數據重寫策略,數據同步性能提升10倍。基于CarbonData的數據快速同步能力,企業可以輕松實現關系型數據庫到數據湖的數據實時同步,縮短數據入湖可見周期,將數據可見時間從T+1優化為T+0,消除數據入湖壁壘。
3、高性能查詢和分析
CarbonData支持對云存儲的數據構建索引和物化視圖,實現10倍以上的查詢性能提升。根據業務需求,用戶可選擇多種索引和物化視圖加速能力,包括主索引、二級索引、時空索引、多值列索引、時間序列Rollup、多表Join預聚合等。
CarbonData在構建這些索引的時候,同樣遵循ACID事務性,確保索引構建過程中不會對業務查詢造成影響。并可以利用云計算的按需擴展能力,加速索引和物化視圖的構建性能。
基于CarbonData最新版本的異步索引構建能力,在數據入庫實時性要求較高的業務場景,用戶可通過"先入庫再建索引"的方式,平衡數據入庫延遲和查詢性能。實現數據入庫后即可被查詢,并使用周期任務或等到業務閑時再對數據建立索引,大幅提升查詢性能。
典型場景分析
某互聯網行業用戶使用CarbonData構建全場景數據湖,借助"DB數據同步"、"實時數據入庫"和"高性能查詢和分析"功能輕松構建PB級別、甚至EB級別大數據處理平臺。
對于一個日活千萬級別的App應用來說,平均每天約產生500億條用戶行為數據,一年的數據存儲量約10PB。在使用CarbonData之前,該用戶曾做過如下性能和成本分析:
1、傳統Nosql數據庫雖然具有較好的數據索引機制,但是"太貴":
因為要查詢快,用戶通常會首先考慮HBase, ElasticSearch等自帶索引的NoSQL數據庫。
以HBase為例,每PB存儲的云硬盤成本為70萬/月;單臺RegionServer可維護不超過10TB的數據, 每PB的數據存儲需100臺計算節點來部署RegionServer,每臺計算節點500元/月,部署的硬件成本為500*100=5萬/月,每PB總成本=75萬/月。
2、基于云存儲+文件雖然具有較好的成本優勢,但是"太慢":
使用Parquet, ORC等列存,可以將數據存儲在對象存儲中,成本大大降低,每PB存儲的對象存儲成本約為8萬/月;100臺計算節點假設每天開機8小時,計算成本5/3=1.67萬/月,每PB總成本約9.67萬/月,成本大幅下降。
但是由于無索引,只能通過暴力掃描的方式進行查詢和計算,在暴力計算時系統往往受限于對象存儲帶寬,假設對象存儲帶寬為20GB/s,對10PB全量數據查詢一次通常需要4~5個小時(視業務查詢條件而定)。
3、云存儲+CarbonData, 實現"又快又便宜"的任性:
CarbonData兼具NoSQL的索引性能優勢,和Parquet、ORC等文件存儲的成本優勢,又快又便宜:
1) 利用CarbonData的索引、物化視圖、緩存等查詢優化技術,查詢時間從4個小時下降到30秒內,查詢性能提升480倍;
2) 支持ACID事務和DB數據同步能力,縮短數據入湖可見周期從T+1到T+0;
3) 基于存算分離架構,使用云存儲+100計算節點按需啟停,每PB總成本約9.67萬/月,成本降低近10倍。
展望
Apache CarbonData是一個高性能EB級別原生Hadoop分析型數據倉庫,提供面向對象存儲上EB級數據的高性能明細查詢能力、交互式查詢能力,提供流數據接入、DB數據實時同步和更新能力,提供對主要ETL業務的支持和加速,以及機器學習、深度學習等AI引擎的對接和優化,生態發展越來越完善。






