
隨著大數據時代的悄然來臨,大數據的價值逐步得到廣泛認可。有效管理大數據,沉淀成數據資產,對內可實現數據資產增值,對外可實現數據共享變現,是企業的通用訴求。
然而,企業在管理底層數據時,經常會面臨各種挑戰:各業務系統分散,形成信息孤島;未制定統一的數據標準;數據處理能力薄弱;數據沒有互通互聯,難以建立數據共享機制。
本文就來聊聊大數據管理的兩個重要概念:數據倉庫、數據治理。
(上)數據倉庫
| 數據倉庫是什么
數據倉庫是基于數據庫的建設過程,是一個面向主題的、集成的、相對穩定的、反映歷史變化的數據集合,用于支持管理決策。
未建設數倉前,需要對多個源表進行查詢分析,查詢慢,數據質量差,無法進行高價值的數據分析。通過建設數倉,可以在一個地方快速訪問多個系統源數據,快速響應OLAP分析;提高數據質量和一致性;能夠提供歷史的數據存儲;更有利于進行數據價值挖掘和數據分析。
| 數據倉庫與數據庫區別
數據庫是面向事物的設計,更關注業務交易處理(OLTP);而數據倉庫面向主題設計,更關注數據分析層面(OLAP)。
數據庫一般存儲在線交易數據,數據倉庫反應的是歷史信息,存儲歷史數據,不可修改。
數據庫盡量避免冗余,而數據倉庫有意冗余,通過空間換時間。
以銀行業務為例,客戶在銀行的每筆交易需要寫入數據庫記錄下來,起到“記賬”的作用,是事物系統的數據平臺;而數據倉庫是分析系統的數據平臺,它從事物系統獲取數據并匯總加工,支持分析決策,如某分行每月發生多少交易、當前存款余額,以此來決定是否需要增加ATM機。
| 數據倉庫整體框架
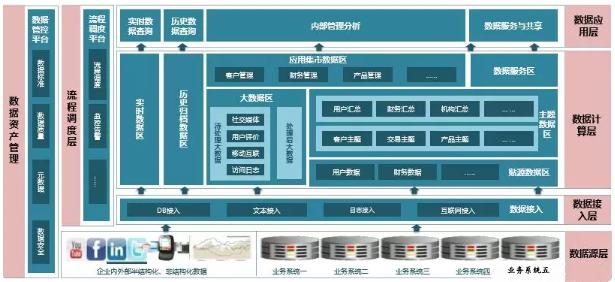
數據源層:
盤點數據倉庫需要接入的數據源,數據庫、結構化電子文件、非結構化數據文件、行為日志等。最終在接入數據倉庫時,所有的數據類型都會轉化成兩種數據格式:數據庫表和電子化結構化文件。
數據接入層:
按上層應用場景不同,接入可分為實時接入和批量接入。
實時接入:對于實時接入的數據,以流式的方式寫入kafka,創建Topic供后續消費;
批量接入:對于批量接入的數據,主要有4種處理邏輯:
寫入Kafka的數據被spark消費,處理后寫入HDFS,然后load至hive表;FTP方式批量傳輸;利用sqoop將數據庫數據批量遷移至HDFS或hive;數據共享交換平臺提取數據庫或文件數據進行入庫。
數據計算層:
ETL任務開發,按需生成對應的事實-維度表或集市層表。業內通常將數據倉庫構建為4層架構:
- STG層,緩沖層,主要用來接收源頭系統提供的數據;
- ODS層,操作數據存儲層,該層存儲和源頭系統相同的數據結構,方便數據質量稽核和數據處理。緩沖層的增量數據會在該層做數據合并。
- DW層,數據倉庫,對接入數據進行模型化的構建,形成所有主題的通用的集合。
- DM層,數據集市,面向某個業務應用而構建的局部DW。
圖:ODS到DW的集成示例
數據應用層:
基于數倉的頂層應用有很多,例如:
- 實時統計類:通過流式處理,將數據進行簡單的指標匯總,應用端實時展示指標結果;
- 多維分析類:提供數據的多維度組合分析(切片、切塊、鉆取、旋轉等),其中多維分析模型可以作為BI的報表數據基礎;
- 產品應用類:標簽畫像系統可以基于數倉經過處理的數據,提供宏觀畫像和微觀畫像分析;知識圖譜可以基于數倉清理后的數據,進行實體和關系的構建;
- 數據服務類:為外部提供接口形式的數據查詢和傳輸,或者進行大批量數據的數據庫導入導出服務;
(下)數據治理
| 為什么要進行數據治理
將分散、多樣化的核心數據通過數據治理技術手段和產品工具進行優化,形成企業內的數據管理體系,并結合企業組織結構,形成數據管控執行體系,在企業內部持續運行、提升挖掘數據的應用價值。
數據治理最終達成的目標可以歸為以下六點:
- 統一:統一數據標準,建立統一的數據資產管理體系;
- 質量:提高數據的質量,包括準確性、一致性、及時性;
- 成本:優化數據生命周期,降低數據管理和運維成本;
- 安全:確保數據安全性,加強數據訪問控制;
- 增值:保證數據資產的有效利用和價值最大化,保證數據資產的保值和增值;
- 應用:輸出并支撐上層的企業內外部應用。
| 如何進行數據治理?
數據治理的三要素:數據標準、數據質量稽核、元數據管理。下面逐一展開來講。
數據標準
從業務角度定義,如設備類、會員類數據,不同渠道來源但同一含義的要統一口徑規范、數據與數據之間的規范;
從技術角度定義,表、字段、字段格式等都要統一規范,如:ID信息、手機號、身份證號等。
數據標準來源可以是國家標準、行業標準,也可以是基于業務的企業標準。
定義完數據標準后,對于新新建設的數據平臺,要采用統一的數據標準;對于已存在的業務系統,在不影響線上的原則上,逐步數據標準接軌。標準執行后,要長期稽核監測,并輸出數據標準校核報告。

圖:數據標準管理周期
數據質量稽核
以數據標準為數據管控的入口,依據數據標準定數據質量檢核規則。對于數據的稽核,有以下八類稽核規則,前六類是單表級校驗,后兩類是多表級校驗:
- 記錄數校驗:稽核單表內寫入的數值是否在指定的閾值范圍內;
- 空值校驗:稽核某一列數據是否含有空值;
- 唯一性校驗:稽核某一列的數據是否都唯一;
- 數據格式校驗:稽核某一列的數據是否符合指定格式規范,如手機號格式校驗;
- 準確性校驗:稽核某一列的數值是否在一定范圍內(包括維度和閾值);
- 波動值校驗:監測某一列的記錄數或某字段數據值,與歷史的業務周期的數值波動是否異常;
- 一致性校驗(多表):多表間的數據是否一致;
- 邏輯性校驗(多表):校驗稽核表與參照表里某一列或某幾列數據的表達式進行比較,檢查數據邏輯是否正確。例如“可視電話用戶情況統計”表中的字段“總的出賬用戶”>=“可視電話用戶使用特征統計”表中的字段“記錄中總的出賬用戶”。
元數據管理
元數據就是定義數據的數據,比如一本書的書名、作者、出版社、出版時間都是元數據。
- 血緣分析:血緣分析是指從某一實體出發,往回追溯其處理過程,直到數據系統的數據源接口,以衡量數據的置信度、質量等。
- 影響分析:影響分析是指從某一實體出發,尋找依賴該實體的處理過程實體或其他實體。重點關注數據流向,把控源頭實體發生變更時對下游實體的影響。如移動用戶話務信息表->移動大客戶信息表->前端展示的競爭專題/用戶分析 或 決策專題/市場分析。
Garbage in,Garbage out。這個是永恒的真理。只有將底層的基礎數據管理好,才能更有效的支撐上層的大數據應用。
作者:Herman Lee 沉淀個人的產品方法論





