
作者 | 百度智能小程序團(tuán)隊
導(dǎo)讀
introduction
本文首先介紹了分布式服務(wù)下日志服務(wù)建設(shè)的挑戰(zhàn),然后介紹了下業(yè)內(nèi)ELK的通用解決方案及與天眼日志服務(wù)的差異性,接下來詳細(xì)介紹了天眼日志服務(wù)平臺的整體架構(gòu),如何做采集、傳輸、檢索、隔離、清理等機(jī)制的,最后對日志服務(wù)與大模型進(jìn)行結(jié)合,不斷探索效能的提升。
全文11796字,預(yù)計閱讀時間30分鐘。
GEEK TALK
01
分布式服務(wù)下日志服務(wù)挑戰(zhàn)
分布式服務(wù)系統(tǒng)中,每個服務(wù)有大量的服務(wù)器,而每臺服務(wù)器每天都會產(chǎn)生大量的日志。我們面臨的主要挑戰(zhàn)有:
1、日志量巨大:在分布式服務(wù)環(huán)境中,日志分散在多個節(jié)點上,每個服務(wù)都會產(chǎn)生大量的日志,因此需要一種可靠的機(jī)制來收集和聚合日志數(shù)據(jù)。
2、多樣化的日志格式:不同的服務(wù)可能使用不同的日志格式,例如日志輸出的字段、順序和級別等,這會增加日志服務(wù)的開發(fā)和維護(hù)難度。
3、日志服務(wù)的可擴(kuò)展性和可靠性:隨著分布式服務(wù)數(shù)量的增加和規(guī)模的擴(kuò)大,日志服務(wù)需要能夠進(jìn)行橫向擴(kuò)展和縱向擴(kuò)展,以保證其性能和可靠性。
所以我們該如何提供分布式系統(tǒng)下高效、低延遲、高性能的日志服務(wù)呢?
GEEK TALK
02
業(yè)內(nèi)ELK通用解決方案
2.1 Elastic Stack發(fā)展歷程
2.2 Elastic Stack組件架構(gòu)圖
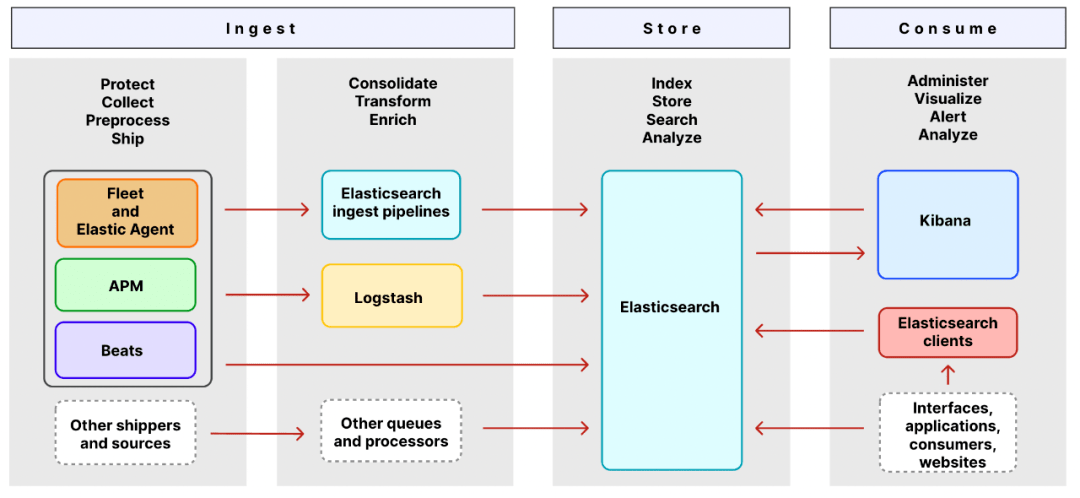
2.2.1 Ingest組件
Ingest是獲取日志數(shù)據(jù)的相關(guān)組件。
shippers和 sources是收集的原始日志組件,承接著原始日志(log文件日志、系統(tǒng)日志、網(wǎng)絡(luò)日志等)采集和發(fā)送,其中 Elastic Agent、APM、Beats 收集和發(fā)送日志、指標(biāo)和性能數(shù)據(jù)。
queues和 processors是原始日志數(shù)據(jù)的處理管道,使用這些組件可以定制化的對原始日志數(shù)據(jù)進(jìn)行處理和轉(zhuǎn)換,在存儲之前可以模板化數(shù)據(jù)格式,方便elasticsearch更好的承接存儲和檢索功能。
Elastic Agent是一種使用單一、統(tǒng)一的方式,為主機(jī)添加對日志、指標(biāo)和其他類型數(shù)據(jù)的監(jiān)控。它還可以保護(hù)主機(jī)免受安全威脅、從操作系統(tǒng)查詢數(shù)據(jù)、從遠(yuǎn)程服務(wù)或硬件轉(zhuǎn)發(fā)數(shù)據(jù)等等。每個代理都有一個策略,可以向其中添加新數(shù)據(jù)源、安全保護(hù)等的集成。
Fleet能夠集中管理Elastic Agent及其策略。使用 Fleet 可以監(jiān)控所有 Elastic Agent 的狀態(tài)、管理agent策略以及升級 Elastic Agent 二進(jìn)制文件或集成。
Elastic APM是一個基于 Elastic Stack 構(gòu)建的應(yīng)用程序性能監(jiān)控系統(tǒng)。通過收集有關(guān)傳入請求、數(shù)據(jù)庫查詢、緩存調(diào)用、外部 HTTP 請求等響應(yīng)時間的詳細(xì)性能信息,實時監(jiān)控軟件服務(wù)和應(yīng)用程序。
Beats 是在服務(wù)器上作為代理安裝的數(shù)據(jù)發(fā)送器,用于將操作數(shù)據(jù)發(fā)送到 Elasticsearch。Beats 可用于許多標(biāo)準(zhǔn)的可觀察性數(shù)據(jù)場景,包括審計數(shù)據(jù)、日志文件和日志、云數(shù)據(jù)、可用性、指標(biāo)、網(wǎng)絡(luò)流量和 windows 事件日志。
Elasticsearch Ingest Pipelines可以在將數(shù)據(jù)存儲到 Elasticsearch 之前對數(shù)據(jù)執(zhí)行常見的轉(zhuǎn)換。將一個或多個“處理器”任務(wù)配置為按順序運(yùn)行,在將文檔存儲到 Elasticsearch 之前對文檔進(jìn)行特定更改。
Logstash是一個具有實時數(shù)據(jù)收集引擎。它可以動態(tài)地統(tǒng)一來自不同來源的數(shù)據(jù),并將數(shù)據(jù)規(guī)范化到目的地。Logstash 支持豐富的輸入、過濾器和輸出插件。
2.2.2 Store組件
Store是承接日志存儲和檢索組件,這里是使用的Elasticsearch承接該功能。
Elasticsearch是 Elastic Stack 核心的分布式搜索和分析引擎。它為所有類型的數(shù)據(jù)提供近乎實時的搜索和分析。無論結(jié)構(gòu)化或非結(jié)構(gòu)化文本、數(shù)字?jǐn)?shù)據(jù)還是地理空間數(shù)據(jù),Elasticsearch 都可以以支持快速搜索的方式高效地存儲和索引這些數(shù)據(jù)。Elasticsearch 提供了一個 REST API,使您能夠在 Elasticsearch 中存儲和檢索數(shù)據(jù)。REST API 還提供對 Elasticsearch 的搜索和分析功能的訪問。
2.2.3 Consumer組件
Consumer是消費(fèi)store存儲數(shù)據(jù)的組件,這里組要有可視化的 kibana和 Elasticsearch Client。
Kibana是利用 Elasticsearch 數(shù)據(jù)和管理 Elastic Stack 的工具。使用它可以分析和可視化存儲在 Elasticsearch 中的數(shù)據(jù)。
Elasticsearch Client提供了一種方便的機(jī)制來管理來自語言(如 JAVA、Ruby、Go、Python/ target=_blank class=infotextkey>Python 等)的 Elasticsearch 的 API 請求和響應(yīng)。

2.3 天眼對比ELK差異
1、接入便捷性
ELK:方案依賴完整流程部署準(zhǔn)備,操作配置復(fù)雜,接入跑通耗時長。
天眼:只需簡單三步配置,頁面申請產(chǎn)品線接入、頁面獲取產(chǎn)品線Appkey、依賴管理中增加天眼SDK依賴并配置appkey到系統(tǒng)配置中。
2、資源定制化
ELK:資源修改、配置每次都需要重啟才能生效,不支持多資源配置化選擇。
天眼:產(chǎn)品線接入時可以選擇使用業(yè)務(wù)自身傳輸、存儲資源或自動使用系統(tǒng)默認(rèn)資源,資源切換只需頁面簡單配置并即時自動生效。
3、擴(kuò)容成本與效率
ELK:方案僅支持單個業(yè)務(wù)產(chǎn)品線,其他業(yè)務(wù)產(chǎn)線接入需重新部署一套,資源無法共享,擴(kuò)容需手動增加相應(yīng)實例等。
天眼:資源集中管理,產(chǎn)品線動態(tài)接入,資源動態(tài)配置即時生效,大部分資源自動共享同時又支持資源獨(dú)享配置;擴(kuò)容直接通過平臺頁面化操作,簡單便捷。
4、日志動態(tài)清理
ELK:依賴人工發(fā)現(xiàn)、手動清理和處理資源占用。
天眼:自動化監(jiān)測ES集群概況,自動計算資源占用情況,當(dāng)達(dá)到監(jiān)控閾值時自動執(zhí)行時間最早的索引資源清理。
5、自適應(yīng)存儲
ELK:傳統(tǒng)方案受限于存儲資源空間和成本,存儲成本高、可保存的數(shù)據(jù)量有限。
天眼:實現(xiàn)了日志轉(zhuǎn)存文件及從文件自動化恢復(fù),日志存儲成本低,存儲周期長。
天眼通過自建分布式日志平臺,有效的解決ELK日志方案下存在的缺陷問題;當(dāng)前天眼日志量級:日均10TB日志量,并發(fā)QPS:10w+,接入產(chǎn)品線數(shù):1000+。
GEEK TALK
03
天眼
3.1 天眼系統(tǒng)架構(gòu)
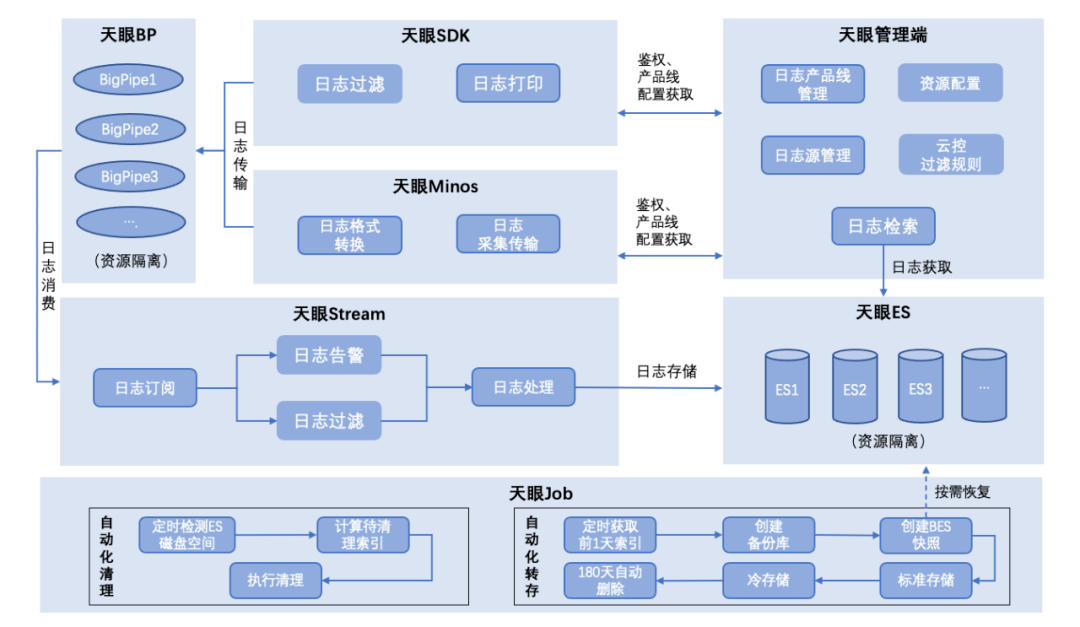
上圖為完整的天眼核心系統(tǒng)架構(gòu),概述如下:
1、天眼日志采集支持SDK及監(jiān)聽日志文件兩種方式,其中SDK主要通過實現(xiàn)日志插件接口獲得完整日志結(jié)構(gòu)信息,并傳輸至天眼日志傳輸管道;獲得的日志信息LogEvent結(jié)構(gòu)完整,同時基于LogEvent增加了產(chǎn)品線標(biāo)識等字段,為日志隔離和檢索提供核心依據(jù);監(jiān)聽日志文件方式實現(xiàn)業(yè)務(wù)方0開發(fā)成本接入,僅需簡單配置即可實現(xiàn)日志接入,支持產(chǎn)品線字段標(biāo)識的同時,日志消息體解析也實現(xiàn)了正則匹配規(guī)則自動化匹配。
2、天眼日志傳輸采用高并發(fā)性能隊列Disruptor,并且二次采用高性能隊列Bigpipe實現(xiàn)日志傳輸異步解耦,解決了傳統(tǒng)隊列因加鎖和偽共享等問題帶來的性能缺陷;同時在傳輸過程中提供日志過濾和日志告警規(guī)則配置化自動化執(zhí)行。
3、天眼日志存儲通過輪詢消費(fèi)Bigpipe日志消息,最終寫入ES的BulkProcessor,由ES自動調(diào)度并發(fā)寫入ES進(jìn)行存儲;在日志傳輸和存儲過程中實現(xiàn)了日志傳輸資源與存儲資源隔離,根據(jù)產(chǎn)品線配置自動化選擇傳輸與存儲資源。
4、天眼自動化清理實現(xiàn)在存儲資源有限的情況下自適應(yīng)存儲,自動化轉(zhuǎn)存與恢復(fù)實現(xiàn)了在ES資源有限情況下低成本長時間存儲解決方案。
3.2 天眼日志采集
日志平臺核心目的是采集分布式場景下的業(yè)務(wù)日志進(jìn)行集中處理和存儲,采集方式主要包含如下:
1、借助常見日志框架提供的插件接口,在生成日志事件的同時執(zhí)行其他自定義處理邏輯,例如log4j2提供的Appender等。
2、通過各種攔截器插件在固定位置攔截并主動生成和打印業(yè)務(wù)日志,將這類日志信息主動發(fā)送至日志消息傳輸隊列中供消費(fèi)使用,常見的如http、rpc調(diào)用鏈請求與返回信息打印,以及MyBatis執(zhí)行過程SQL明細(xì)打印等。
3、監(jiān)聽日志文件寫入,從文件系統(tǒng)上的一個文件進(jìn)行讀取,工作原理有些類似UNIX的tAIl -0F命令,當(dāng)日志寫入本地文件時捕獲寫入行內(nèi)容并進(jìn)行其他自定義處理,例如將日志行信息發(fā)送至消息隊列供下游使用。
4、syslog:監(jiān)聽來自514端口的syslog消息,并將其轉(zhuǎn)換為RFC3164格式。
更多可用的日志采集實現(xiàn)方式,可以參考:Input Plugins
下面以天眼日志采集為例詳細(xì)介紹日志采集實現(xiàn)過程:
天眼平臺供支持兩類日志采集實現(xiàn)方式,一類是SDK、一類是minos(百度自研的新一代的流式日志傳輸系統(tǒng))。
3.2.1 天眼SDK日志采集
天眼SDK日志采集方式為通過Java SDK方式向業(yè)務(wù)方提供日志采集組件實現(xiàn),達(dá)到自動收集業(yè)務(wù)日志并自動傳輸?shù)哪康模缓诵姆譃閙essage日志流和trace日志流兩大塊:
1、message日志流主要通過日志框架提供的Appender接口實現(xiàn),共支持log4j、logback、log4j2等主流日志框架。
以logback為例,通過繼承并實現(xiàn)AppenderBase抽象類提供的append方法,在logback日志框架生成LogEvent后獲取日志事件對象并提交給LogbackTask執(zhí)行任務(wù)處理,在LogbackTask中可以對日志事件內(nèi)容進(jìn)行進(jìn)一步包裝完善,并執(zhí)行一些日志過濾策略等,最終得到的日志事件信息將直接發(fā)送至日志傳輸隊列進(jìn)行傳輸處理;
publicclassLogClientAppender< E> extendsAppenderBase< E> { privatestaticfinalLogger LOGGER = LoggerFactory.getLogger(LogClientAppender.class); @Override protectedvoidappend(E eventObject){ ILoggingEvent event = filter(eventObject); if(event != null) { MessageLogSender.getExecutor.submit( newLogbackTask(event, LogNodeFactory.getLogNodeSyncDto)); } } }2、trace日志流主要通過各類攔截器攔截業(yè)務(wù)請求調(diào)用鏈及業(yè)務(wù)執(zhí)行鏈路,通過獲取調(diào)用鏈詳細(xì)信息主動生成調(diào)用鏈日志事件,并發(fā)送至日志傳輸隊列進(jìn)行消費(fèi)使用,常見的調(diào)用鏈日志包含http與rpc請求及響應(yīng)日志、mybatis組件SQL執(zhí)行日志等;
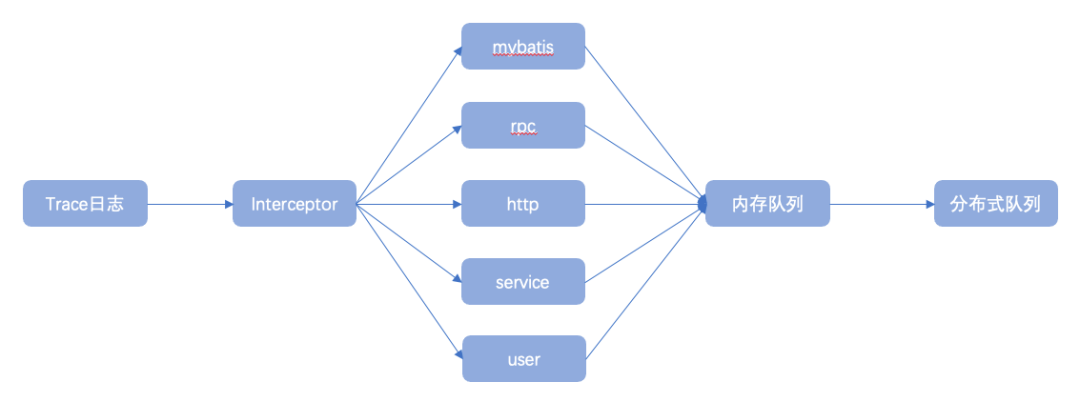
下圖為trace日志流實現(xiàn)類圖,描述了trace日志流抽象實現(xiàn)過程:
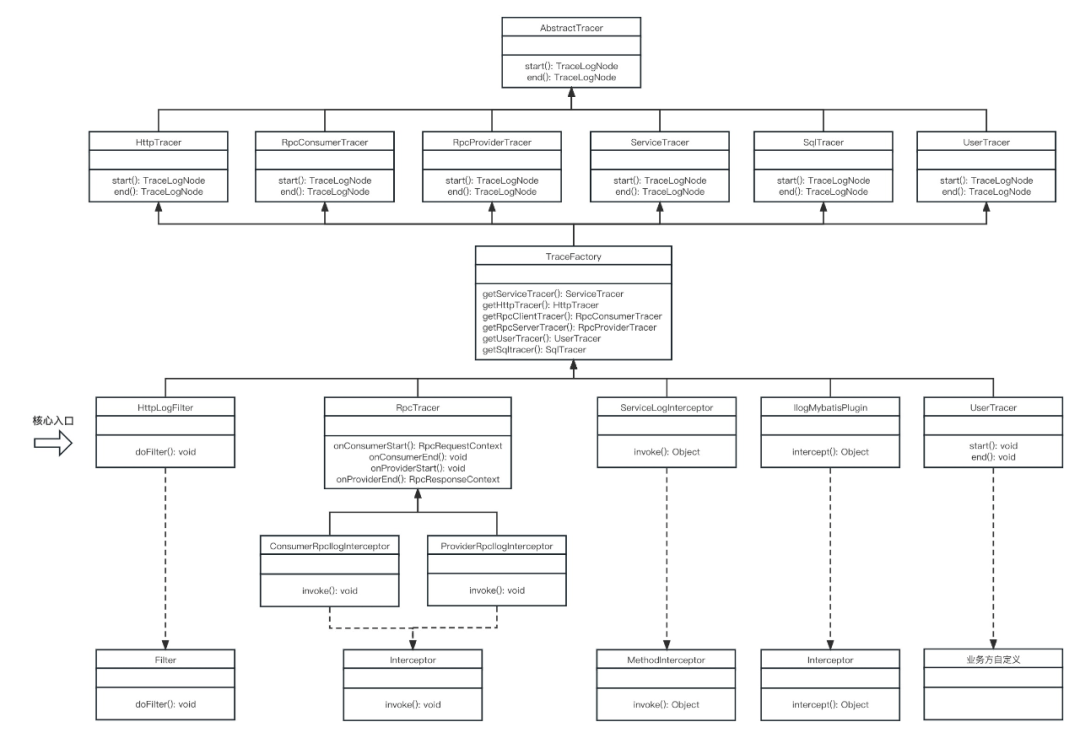
以mybatis為例,trace日志流核心攔截器實現(xiàn)類為IlogMybatisPlugin,實現(xiàn)ibatis Interceptor接口
核心代碼:
TraceFactory.getSqltracer.end( returnObj, className, methodName, realParams, dbType, sqlType, sql, sqlUrl)
在end方法中將SQL執(zhí)行過程中產(chǎn)生的各類信息通過參數(shù)傳入,并組裝成SqlLogNode(繼承至通用日志節(jié)點LogNode)發(fā)布到隊列。
使用時需要業(yè)務(wù)方手動將插件注冊到SqlSessionFactory,以生效插件:
sqlSessionFactory.getConfiguration.addInterceptor( newIlogMybatisPlugin);
3.2.2 天眼minos日志采集
minos日志采集主要是借助百度自研的minos數(shù)據(jù)傳輸平臺,實現(xiàn)機(jī)器實例上的日志文件信息實時傳輸至目的地,常見傳輸目的地有Bigpipe、HDFS、AFS等;目前天眼主要是通過將minos采集到的日志發(fā)送到Bigpipe實現(xiàn),并由后續(xù)的Bigpipe消費(fèi)者統(tǒng)一消費(fèi)和處理;同時針對日志來源為minos的日志在消費(fèi)過程中增加了日志解析與轉(zhuǎn)換策略,確保采集到的日志格式和SDK方式生成的日志格式基本一致;
在日志采集過程中,天眼如何解決平臺化標(biāo)識:
1、在產(chǎn)品線接入天眼時,天眼給對應(yīng)產(chǎn)品線生成產(chǎn)品線唯一標(biāo)識;
2、SDK接入方式下,產(chǎn)品線服務(wù)端通過系統(tǒng)變量配置產(chǎn)品線標(biāo)識,SDK在運(yùn)行過程中會自動讀取該變量值并設(shè)置到LogNode屬性中;
3、LogNode作為日志完整信息對象,在傳輸過程中最終存儲到ES,同時ES在建索引時為產(chǎn)品線唯一標(biāo)識分配字段屬性;
4、產(chǎn)品線唯一標(biāo)識貫穿整個分布式日志鏈路并和日志內(nèi)容強(qiáng)綁定。
3.3 高并發(fā)數(shù)據(jù)傳輸和存儲
在ELK方案中,生成的日志信息直接發(fā)送給logstash進(jìn)行傳輸,并寫入到es,整個過程基本為同步操作,并發(fā)性能完全依賴logstash服務(wù)端及ES服務(wù)端性能;
天眼則是通過異步方式解耦日志傳輸過程,以及在日志入口處引入Disruptor高性能隊列,并發(fā)性能直奔千萬級別;同時在Disruptor本地隊列之后再設(shè)計Bigpipe離線隊列,用來長效存儲和傳輸日志消息;以及引入兜底文件隊列BigQueue解決方案,處理在極少數(shù)異常情況下寫本地隊列或離線隊列失敗時的兜底保障,如下圖所示:
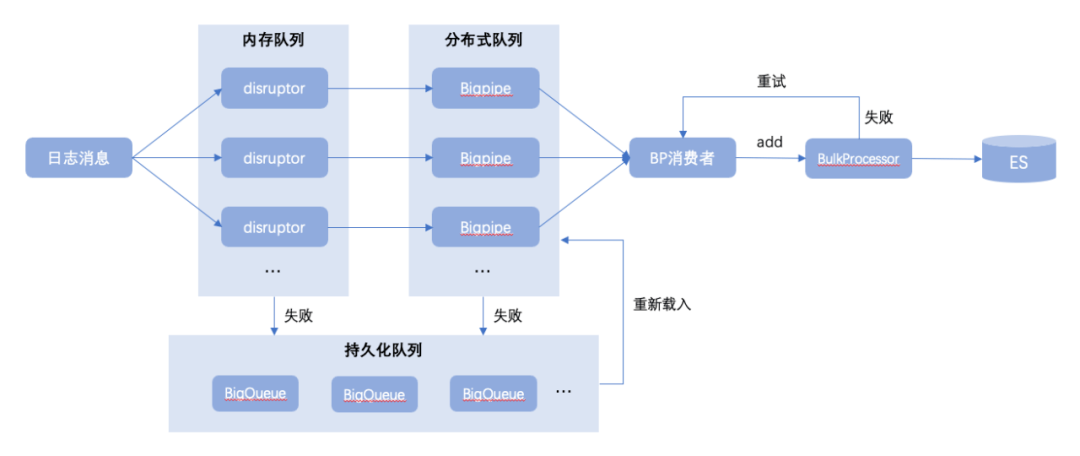
Disruptor是一個高性能的用于線程間消息處理的開源框架。Disruptor內(nèi)部使用了RingBuffer,它是Disruptor的核心的數(shù)據(jù)結(jié)構(gòu)。
Disruptor隊列設(shè)計特性:
固定大小數(shù)組:由于數(shù)組占用一塊連續(xù)的內(nèi)存空間,可以利用CPU的緩存策略,預(yù)先讀取數(shù)組元素附近的元素;
數(shù)組預(yù)填充:避免了垃圾回收代來的系統(tǒng)開銷;
緩存行填充:解決偽共享問題;
位操作:加快系統(tǒng)的計算速度;
使用數(shù)組+系列號的這種方法最大限度的提高了速度。因為如果使用傳統(tǒng)的隊列的話,在多線程環(huán)境下對隊列頭和隊列尾的鎖競爭是一種很大的系統(tǒng)開銷。
Bigpipe是一個分布式中間件系統(tǒng),支持Topic和Queue模型,不僅可以完成傳統(tǒng)消息隊列可以實現(xiàn)的諸如消息、命令的實時傳輸,也可以用于日志數(shù)據(jù)的實時傳輸。Bigpipe能夠幫助模塊間的通信實現(xiàn)解耦,并能保證消息的不丟不重;
BigQueue是基于內(nèi)存映射文件的大型、快速和持久隊列;
1、 快: 接近直接內(nèi)存訪問的速度,enqueue和dequeue都接近于O(1)內(nèi)存訪問。
2、 大:隊列的總大小僅受可用磁盤空間的限制。
3、 持久:隊列中的所有數(shù)據(jù)都持久保存在磁盤上,并且是抗崩潰的。
4、 可靠:即使您的進(jìn)程崩潰,操作系統(tǒng)也將負(fù)責(zé)保留生成的消息。
5、 實時:生產(chǎn)者線程產(chǎn)生的消息將立即對消費(fèi)者線程可見。
6、 內(nèi)存高效:自動分頁和交換算法,只有最近訪問的數(shù)據(jù)保留在內(nèi)存中。
7、 線程安全:多個線程可以同時入隊和出隊而不會損壞數(shù)據(jù)。
8、 簡單輕量:目前源文件個數(shù)12個,庫jar不到30K。
在采集到日志事件后,進(jìn)入傳輸過程中,天眼SDK中支持日志過濾規(guī)則策略匹配,針對命中策略的日志進(jìn)行過濾,實現(xiàn)過程如下圖所示:
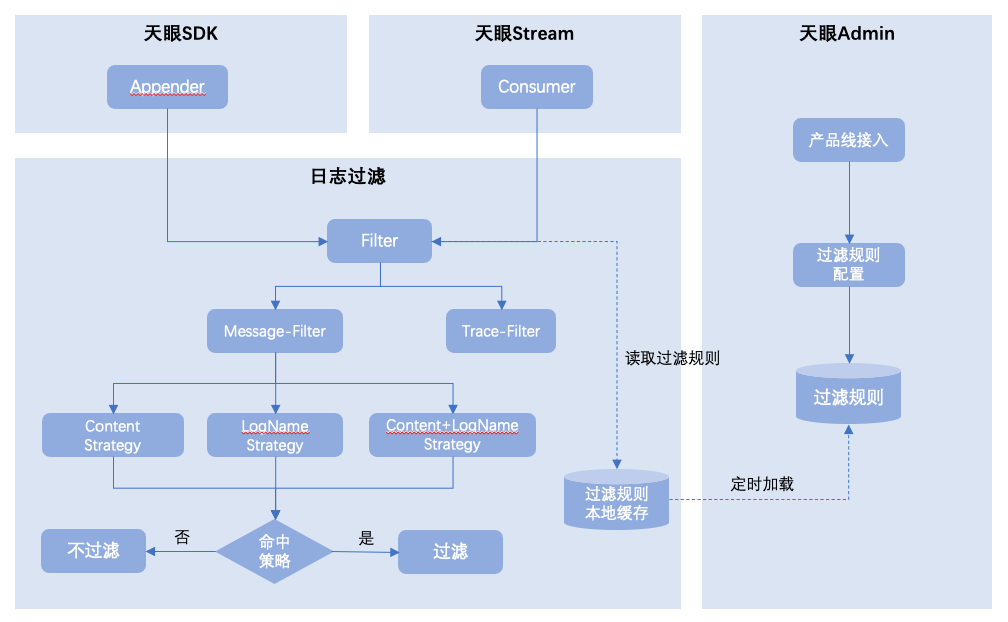
3.4 天眼日志檢索
基于天眼鏈路最終存儲到ES的日志數(shù)據(jù),天眼平臺提供了可視化日志檢索頁面,能夠根據(jù)產(chǎn)品線唯一標(biāo)識(日志源ID)指定業(yè)務(wù)范圍進(jìn)行檢索,同時支持各種檢索條件,效果如下圖所示:
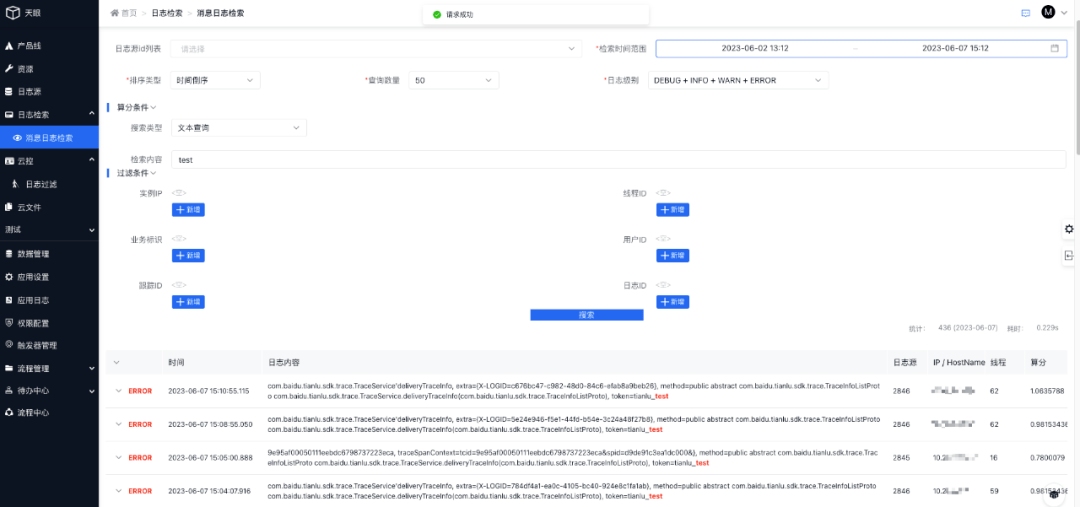
3.4.1 檢索條件詳解
日志源id列表:獲取日志源對應(yīng)的日志
檢索時間范圍:日志的時間范圍
排序類型:日志的存入時間/日志存入的算分
查詢數(shù)量:查詢出多少數(shù)量的日志
日志級別:查詢什么級別的日志,如:DEBUG / INFO / WARN / ERROR
算分條件:支持五種算分查詢,文本查詢、等值查詢、短語查詢、前綴查詢、邏輯查詢;五選一
過濾條件:?只顯示符合過濾條件信息的日志
3.4.2 算分條件檢索詳細(xì)說明
支持五種算分查詢:文本查詢、等值查詢、短語查詢、前綴查詢、邏輯查詢。五選一
搜索內(nèi)容字段: message、exception
"message": { "type": "text", "fields": { "raw": { "type": "keyword", "ignore_above": 15000 } }, "analyzer": "my_ik_max_word", "search_analyzer": "my_ik_smart" }, "exception": { "type": "text", "analyzer": "my_ik_max_word", "search_analyzer": "my_ik_smart" }說明:
- "analyzer": "my_ik_max_word":底層使用ik_max_word,message和exception信息在存儲是會以最細(xì)粒度拆詞進(jìn)行存儲;
- "search_analyzer": "my_ik_smart":底層使用ik_smart,在查詢內(nèi)容是,會將查詢內(nèi)容以最粗粒度拆分進(jìn)行查詢。
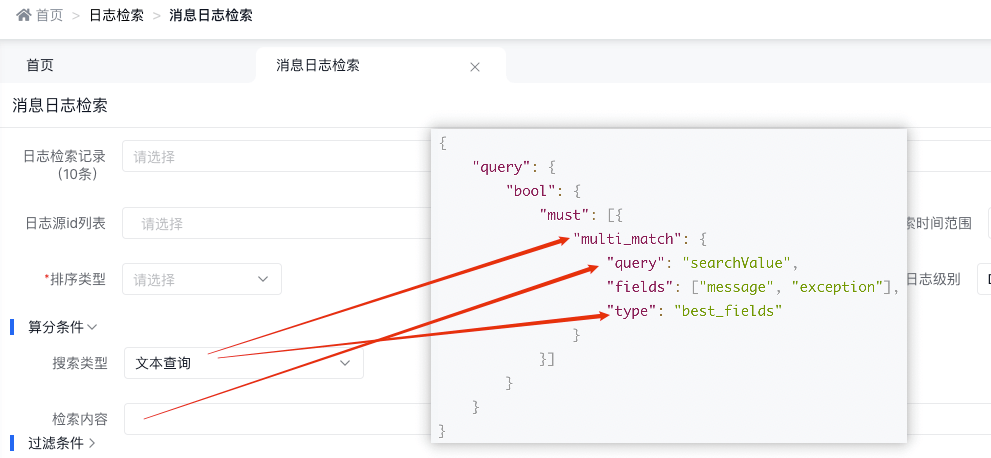
3.4.2.1 文本查詢
底層實現(xiàn)原理
{ "query": { "bool": { "must": [{ "multi_match": { "query": "searchValue", "fields": [ "message", "exception"], "type": "best_fields" } }] } } }天眼管理端對應(yīng)圖
使用說明:
- multi_match中的best_fields會將任何與查詢匹配的文檔作為結(jié)果返回,但是只使用最佳字段的 _score 評分作為評分結(jié)果返回
3.4.2.2 等值查詢
底層實現(xiàn)原理
{ "query": { "bool": { "must": [{ "multi_match": { "query": "searchValue", "fields": [ "message", "exception"], "type": "best_fields", "analyzer": "keyword" } }] } } }天眼管理端對應(yīng)圖
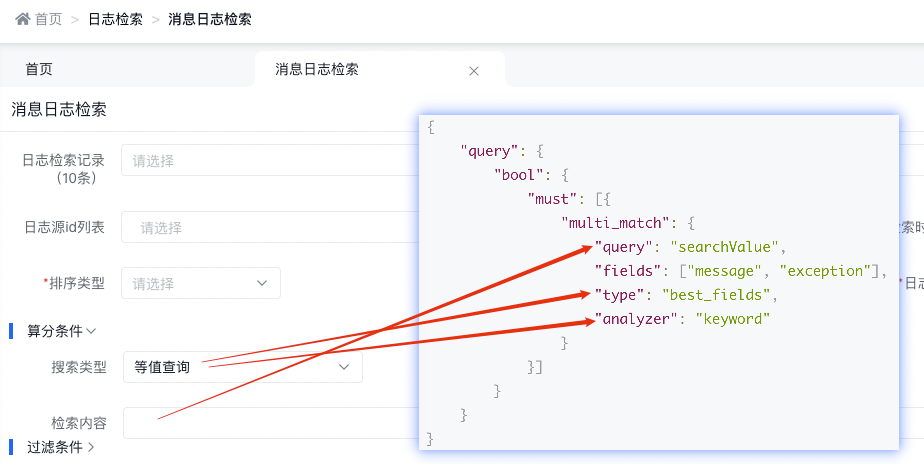
使用說明:
- multi_match中的best_fields會將任何與查詢匹配的文檔作為結(jié)果返回,但是只使用最佳字段的 _score 評分作為評分結(jié)果返回
- 設(shè)置 analyzer 參數(shù)來定義查詢語句時對其中詞條執(zhí)行的分析過程
- Keyword Analyzer - 不分詞,直接將輸入當(dāng)做輸出
3.4.2.3 短語查詢
底層實現(xiàn)原理
{ "query": { "bool": { // 短語查詢 "must": [{ "multi_match": { "query": "searchValue", "fields": [ "message", "exception"], "type": "phrase", "slop": 2 } }] } } }天眼管理端對應(yīng)圖
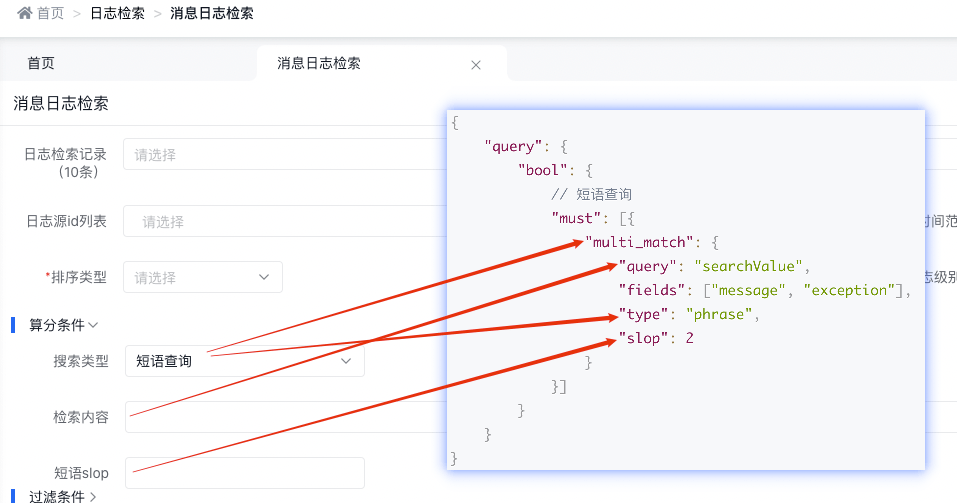
使用說明:
- phrase 在 fields 中的每個字段上均執(zhí)行 match_phrase 查詢,并將最佳字段的 _score 作為結(jié)果返回
- 默認(rèn)使用 match_phrase 時會精確匹配查詢的短語,需要全部單詞和順序要完全一樣,標(biāo)點符號除外
- slop指查詢詞條相隔多遠(yuǎn)時仍然能將文檔視為匹配 什么是相隔多遠(yuǎn)? 意思是說為了讓查詢和文檔匹配你需要移動詞條多少次?以 "I like swimming and riding!" 的文檔為例,想匹配 "I like riding",只需要將 "riding" 詞條向前移動兩次,因此設(shè)置 slop 參數(shù)值為 2, 就可以匹配到。
3.4.2.4 前綴查詢
底層實現(xiàn)原理
{ "size": 50, "query": { "bool": { // 前綴查詢 "must": [{ "multi_match": { "query": "searchValue", "fields": [ "message", "exception"], "type": "phrase_prefix", "max_expansions": 2 } }] } } }天眼管理端對應(yīng)圖
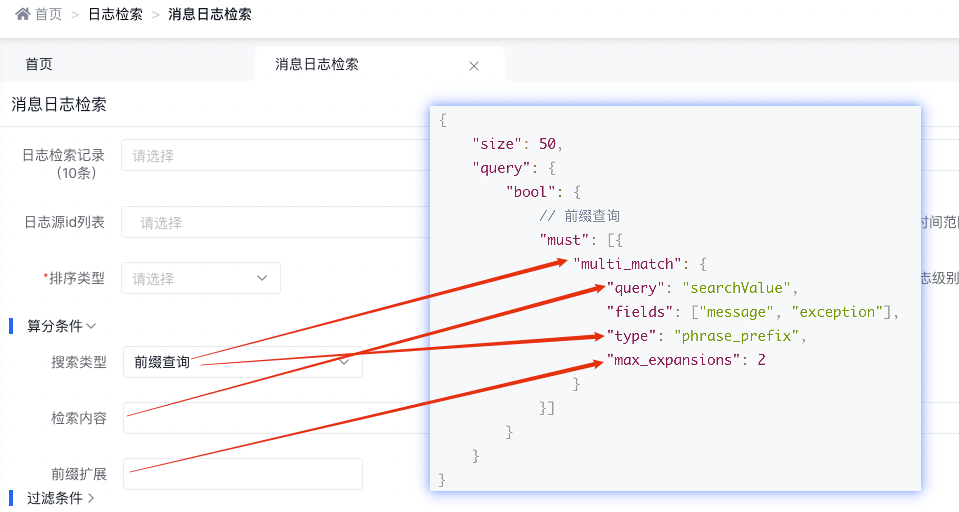
使用說明:
- phrase_prefix 在 fields 中的字段上均執(zhí)行 match_phrase_prefix 查詢,并將每個字段的分?jǐn)?shù)進(jìn)行合并
- match_phrase_prefix 和 match_phrase 用法是一樣的,區(qū)別就在于它允許對最后一個詞條前綴匹配,例如:查詢 I like sw 就能匹配到I like swimming and riding。
- max_expansions 說的是參數(shù) max_expansions 控制著可以與前綴匹配的詞的數(shù)量,默認(rèn)值是 50。以 I like swi 查詢?yōu)槔鼤炔檎业谝粋€與前綴 swi 匹配的詞,然后依次查找搜集與之匹配的詞(按字母順序),直到?jīng)]有更多可匹配的詞或當(dāng)數(shù)量超過 max_expansions 時結(jié)束。
- match_phrase_prefix 用起來非常方便,能夠?qū)崿F(xiàn)輸入即搜索的效果,但是也會出現(xiàn)問題。 假如說查詢 I like s 并且想要匹配 I like swimming ,結(jié)果是默認(rèn)情況下它會搜索出前 50 個組合,如果前 50 個沒有 swimming ,那就不會顯示出結(jié)果。只能是用戶繼續(xù)輸入后面的字母才可能匹配出結(jié)果。
3.4.2.5 邏輯查詢
底層實現(xiàn)原理
{ "query": { "bool": { // 邏輯查詢 "must": [{ "simple_query_string": { "query": "searchValue", "fields": [ "message", "exception"] } }] } } }天眼管理端對應(yīng)圖:
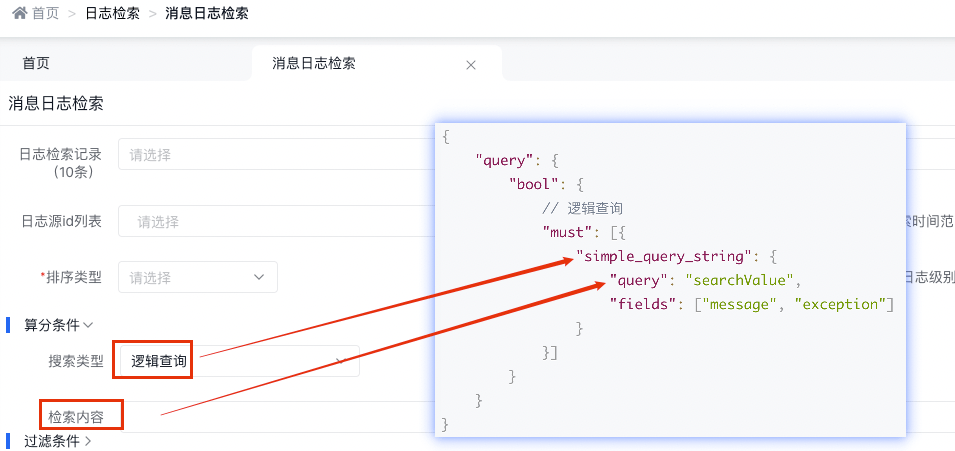
simple_query_string查詢支持以下操作符(默認(rèn)是OR),用于解釋查詢字符串中的文本:
- + AND
- | OR
- - 非
- " 包裝許多標(biāo)記以表示要搜索的短語
- * 在術(shù)語的末尾表示前綴查詢
- ( and ) 表示優(yōu)先級
- ~N 在一個單詞之后表示編輯距離(模糊)
- ~N 在短語后面表示溢出量
官方使用文檔:https://www.elastic.co/guide/en/elasticsearch/reference/6.8/query-dsl-simple-query-string-query.html
使用示例解釋:
GET /_search { "query": { "simple_query_string": { "fields": [ "content"], "query": "foo bar -baz" } }這個搜索的目的是只返回包含foo或bar但不包含baz的文檔。然而,由于使用了OR的default_operator,這個搜索實際上返回了包含foo或bar的文檔以及不包含baz的文檔。要按預(yù)期返回文檔,將查詢字符串更改為foo bar +-baz。
3.5 日志資源隔離
在龐大的企業(yè)級軟件生產(chǎn)環(huán)境下,業(yè)務(wù)系統(tǒng)會產(chǎn)生海量日志數(shù)據(jù)。一方面,隨著業(yè)務(wù)方的不斷增加,日志系統(tǒng)有限的資源會被耗盡,導(dǎo)致服務(wù)不穩(wěn)定甚至宕機(jī)。另一方面,不同業(yè)務(wù)的日志量級、QPS 存在差異,極端情況下不同業(yè)務(wù)方會對共享資源進(jìn)行競爭,導(dǎo)致部分業(yè)務(wù)的日志查詢延時變高。這對日志系統(tǒng)的資源管理帶來了挑戰(zhàn)。
天眼平臺采用資源隔離的方式解決此問題,來為業(yè)務(wù)提供實時、高效、安全的存儲與查詢服務(wù)。
資源隔離主要圍繞著日志的傳輸資源與日志的存儲資源進(jìn)行。業(yè)務(wù)方在接入天眼系統(tǒng)時,可以根據(jù)業(yè)務(wù)需要在平臺交互界面,進(jìn)行傳輸資源與存儲資源的隔離配置,這種隔離資源的配置方式避免了共享資源競爭導(dǎo)致的日志延遲增加與潛在的日志丟失問題。
具體的隔離實現(xiàn)方案如圖 3.5.1 所示,主要包括以下步驟:
1、業(yè)務(wù)方生產(chǎn)日志:如 3.2 介紹到的,業(yè)務(wù)方運(yùn)行時產(chǎn)生的日志可以通過 SDK 或 minos 的方式將日志傳輸至分布式隊列 BP 中;
4、天眼平臺分發(fā)日志:日志分發(fā)器會不斷從綁定的內(nèi)存通道中拉取日志事件,并通過 ES 客戶端對日志進(jìn)行存儲,如果存儲失敗則會觸發(fā)相應(yīng) backoff 策略,例如異常行為記錄;
5、業(yè)務(wù)方日志查詢:日志存儲至 ES 集群之后,業(yè)務(wù)方可以通過平臺界面便捷地進(jìn)行日志查詢。
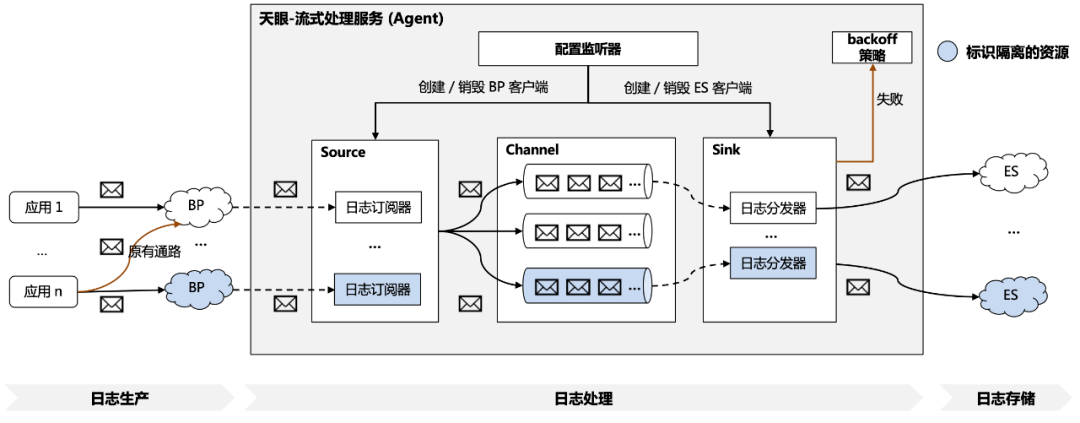
△3.5.1 天眼-資源隔離方案
可見在復(fù)雜的多應(yīng)用場景下,隔離資源機(jī)制是一種高效管理日志系統(tǒng)資源的方式。天眼日志系統(tǒng)提供了靈活的資源配置來避免資源浪費(fèi),提供了共享資源的隔離來降低業(yè)務(wù)方日志查詢的延遲、提升日志查詢的安全性,進(jìn)而推動業(yè)務(wù)的增長和運(yùn)營效率。
3.6 日志動態(tài)清理與存儲降級
隨著業(yè)務(wù)的長期運(yùn)行與發(fā)展,日志量級也在不斷增加。一方面,針對近期產(chǎn)生的日志,業(yè)務(wù)方有迫切的查詢需求。針對產(chǎn)生較久的日志,迫于監(jiān)管與審計要求也有低頻率訪問的訴求。如何在成本可控并且保證平臺穩(wěn)定的前提下,維護(hù)這些海量日志并提供查詢服務(wù)對日志系統(tǒng)而言也是一個挑戰(zhàn)。
天眼平臺通過資源清理機(jī)制和日志存儲降級機(jī)制來解決這個問題。
資源清理機(jī)制主要用作 ES 集群的索引清理。隨著日志量的增加,集群的資源占用率也在增加,在極端情況下,過高的磁盤與內(nèi)存占用率會導(dǎo)致 ES 服務(wù)的性能下降,甚至服務(wù)的宕機(jī)。資源清理機(jī)制會定期查詢 ES 集群的資源占用情況,一旦集群的磁盤資源超過業(yè)務(wù)方設(shè)定的閾值,會優(yōu)先清理最舊的日志,直到資源占用率恢復(fù)正常水平。
存儲降級機(jī)制主要用作 ES 集群的索引備份與恢復(fù)。將日志長期存儲在昂貴的 ES 集群中是一種資源浪費(fèi),也為日志系統(tǒng)增加了額外的開銷。存儲降級機(jī)制會定期對 ES 集群進(jìn)行快照,然后將快照轉(zhuǎn)存到更低開銷的大對象存儲服務(wù)(BOS)中,轉(zhuǎn)存之后的快照有 180 天的有效期以應(yīng)對審查與監(jiān)管。當(dāng)業(yè)務(wù)方需要查詢降級存儲后的日志時,只需要從大對象存儲服務(wù)中拉取快照,再恢復(fù)到 ES 集群以提供查詢能力。
具體的資源清理機(jī)制與存儲降級機(jī)制如圖 3.6.1 所示,主要包括以下步驟:
1、集群狀態(tài)查詢:資源清理任務(wù)通過定期查詢集群信息的方式監(jiān)測資源占用率,當(dāng)資源占用率超過業(yè)務(wù)方設(shè)定的閾值時會觸發(fā)資源清理;
2、集群索引清理:通過查詢索引信息并進(jìn)行資源占用情況計算,再根據(jù)時間倒序刪除依次最舊的索引,直到滿足設(shè)定的閾值;
3、集群索引備份:存儲降級任務(wù)會定期對集群進(jìn)行快照請求,然后將快照文件轉(zhuǎn)存到低開銷的大文件存儲服務(wù)中完成存儲的降級;
4、集群索引恢復(fù):在業(yè)務(wù)方需要查詢降級存儲后的日志時,服務(wù)會將快照文件從大文件存儲服務(wù)中拉取目標(biāo)快照,再通過快照恢復(fù)請求對快照進(jìn)行恢復(fù),以提供業(yè)務(wù)方查詢。
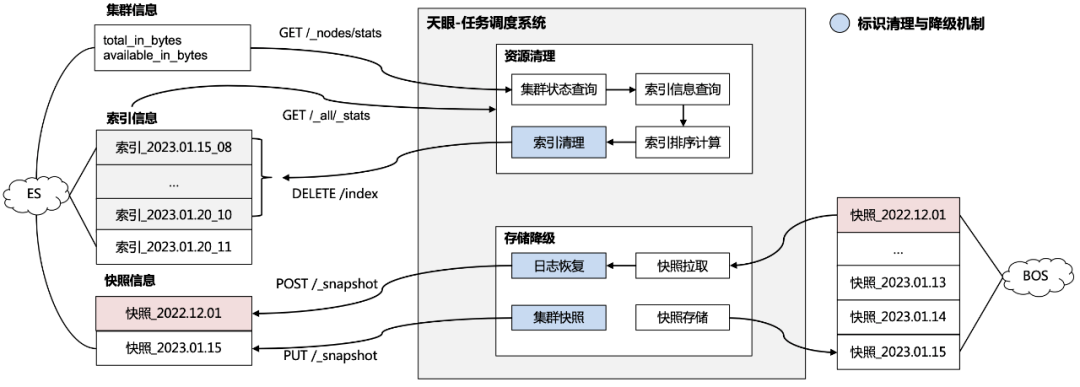
△3.6.1天眼-日志動態(tài)清理與存儲降級方案
可見在面對海量日志的存儲與查詢,通過資源清理機(jī)制可以防止集群資源過載同時提升日志檢索效率,通過存儲降級機(jī)制可以提升資源利用率同時確保審計的合規(guī)性,從而在業(yè)務(wù)高速增長使用的同時保證日志系統(tǒng)的健壯性。
3.7 最佳實踐
基于前面提到的天眼平臺設(shè)計思想,結(jié)合其中部分能力展開介紹天眼在運(yùn)維管理方面的實踐。
3.7.1 天眼平臺化實踐
天眼通過抽象產(chǎn)品線概念,針對不同的接入方提供產(chǎn)品線接入流程,為業(yè)務(wù)生成產(chǎn)品線唯一標(biāo)識并與業(yè)務(wù)日志綁定;產(chǎn)品線相關(guān)流程如下:
1、產(chǎn)品線日志源申請流程
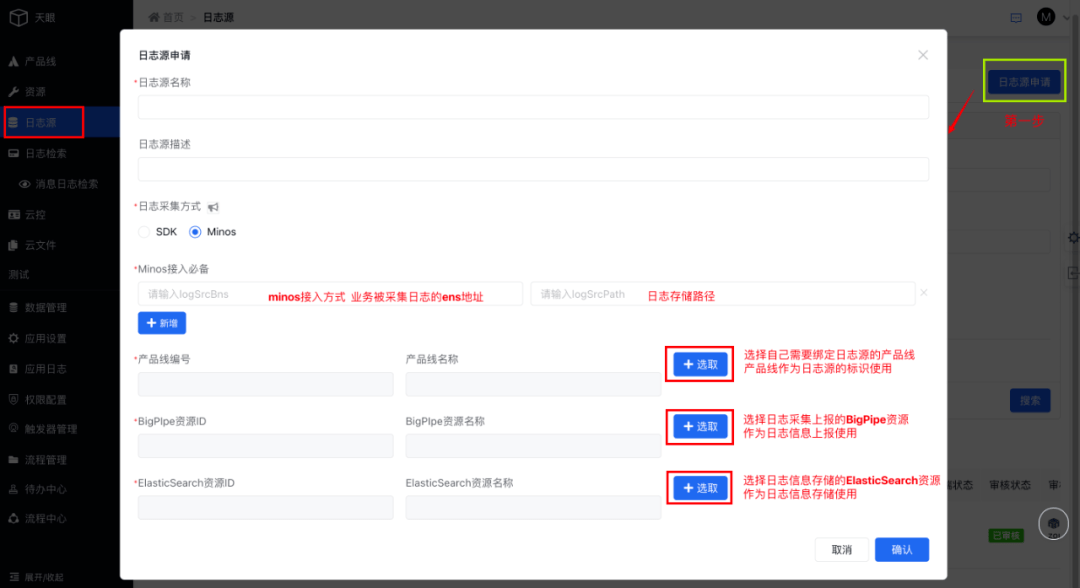
支持產(chǎn)品線選擇日志采集方式包含SDK、Minos兩種方式,選擇minos接入時,bns與日志存儲路徑必選,方便系統(tǒng)根據(jù)配置自動執(zhí)行日志采集。
同時在Bigpipe資源與ES資源方面,平臺支持多種資源隔離獨(dú)立使用,不同的產(chǎn)品線可以配置各自獨(dú)有的傳輸和存儲資源,保障數(shù)據(jù)安全性和穩(wěn)定性。
2、日志源申請后,需要管理員審核后才能進(jìn)行使用(申請后無需操作,僅需等待管理員通過審核后,進(jìn)行SDK接入)
access_key的值查看權(quán)限:僅日志源綁定產(chǎn)品線的經(jīng)理及接口人可查,access_key將作為產(chǎn)品線接入天眼鑒權(quán)的關(guān)鍵依據(jù)。
3.7.2 日志過濾實踐
產(chǎn)品線接口人可以基于自身產(chǎn)品線新增日志過濾規(guī)則配置,配置的規(guī)則將自動生效于日志采集傳輸流程中:
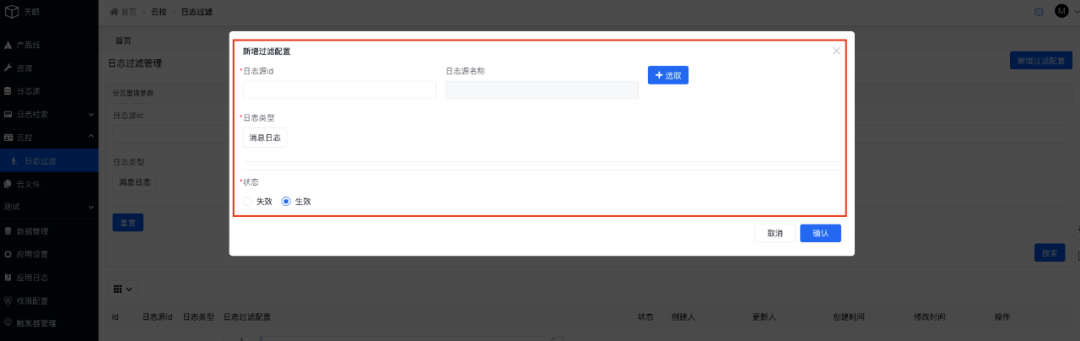
選擇消息日志后將彈出詳細(xì)過濾規(guī)則配置菜單,當(dāng)前系統(tǒng)共支持三種過濾規(guī)則,分別是按日志內(nèi)容、按日志名稱、按日志內(nèi)容和日志名稱組合三種方式:
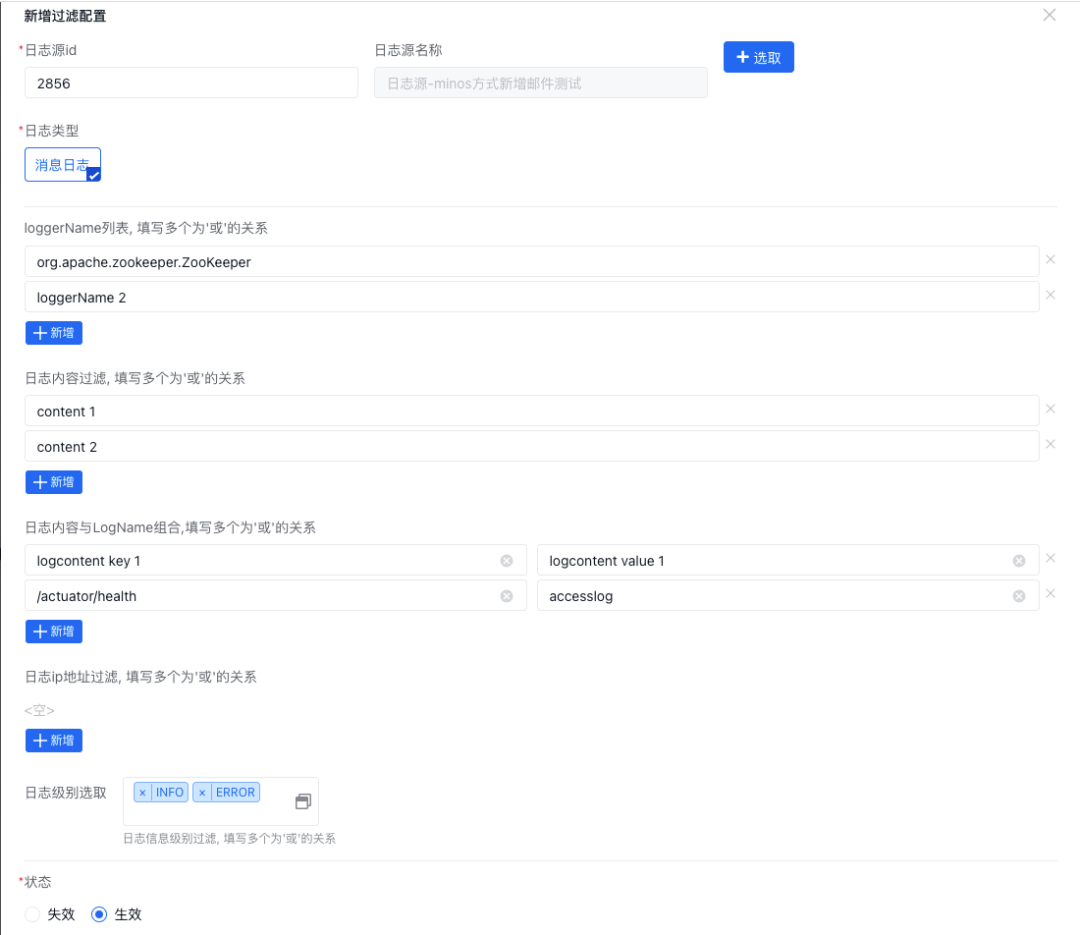
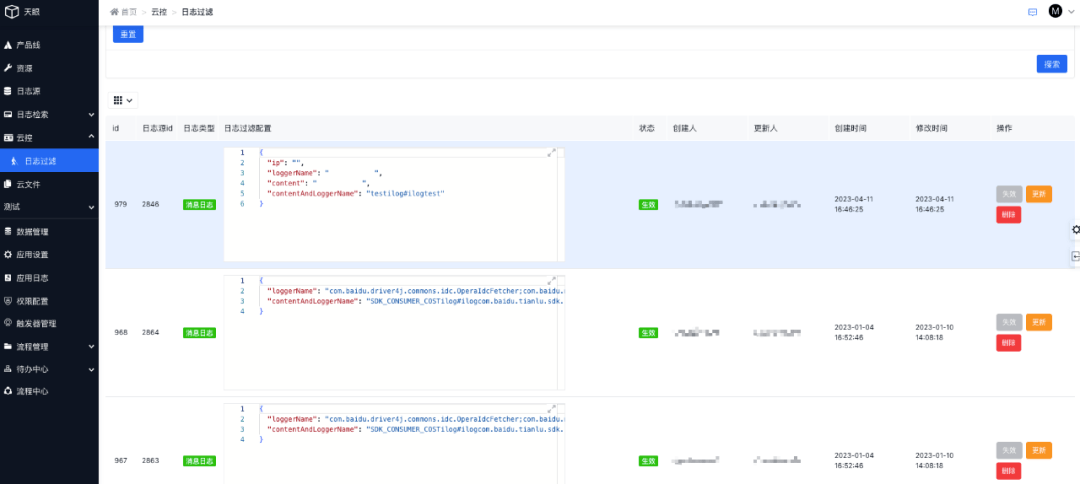
過濾規(guī)則配置完成后可以在列表管理每條規(guī)則:
GEEK TALK
04
思考與總結(jié)
隨著分布式業(yè)務(wù)系統(tǒng)的日益復(fù)雜,為業(yè)務(wù)方提供高效、低延遲、高性能的日志服務(wù)系統(tǒng)顯得尤為重要。本文介紹了天眼平臺是如何進(jìn)行日志采集、傳輸并支持檢索的,此外還通過支持日志的資源隔離,解耦各業(yè)務(wù)方的日志通路和存儲,從而實現(xiàn)業(yè)務(wù)日志的高效查詢和業(yè)務(wù)問題的高效定位。此外通過對日志進(jìn)行監(jiān)控可以主動發(fā)現(xiàn)系統(tǒng)問題,并通過告警日志的trace_id快速定位問題,從而提升問題發(fā)現(xiàn)導(dǎo)解決的效率。
2023 源創(chuàng)會線下重啟,基礎(chǔ)軟件技術(shù)面面談。





