
在自然語言處理領域,大語言模型是一類十分重要的技術。顧名思義,大語言模型指的是比較“大”的(神經網絡)語言模型,它們以自上文推理詞語概率為核心任務。隨著機器學習和深度學習技術的不斷發展,人工智能的應用范圍越來越廣泛,而大語言模型則成為了自然語言處理、文本生成和對話系統等領域的重要組成部分。那么,你知道什么是大語言模型嗎?
自然語言處理是人工智能領域的一個重要分支,它涉及了對自然語言的理解、生成和推斷等任務。在這個領域中,大語言模型被認為是目前最先進的技術之一。它是一種基于神經網絡的語言模型,可以根據上文預測下一個單詞或短語的出現概率。這項技術需要大量的數據進行訓練,以便從數據中學習到普遍的規律。
隨著時間的推移,大語言模型不斷發展壯大,并且各種改進版本相繼問世。其中最為著名的是GPT(Generative Pre-trAIned Transformer)系列模型。這個系列的模型使用了Transformer架構,是一種基于注意力機制的神經網絡架構,它在自然語言處理中表現出色。而GPT-1則是GPT系列模型的第一個版本,其結構主要由多層自回歸式的Transformer組成。
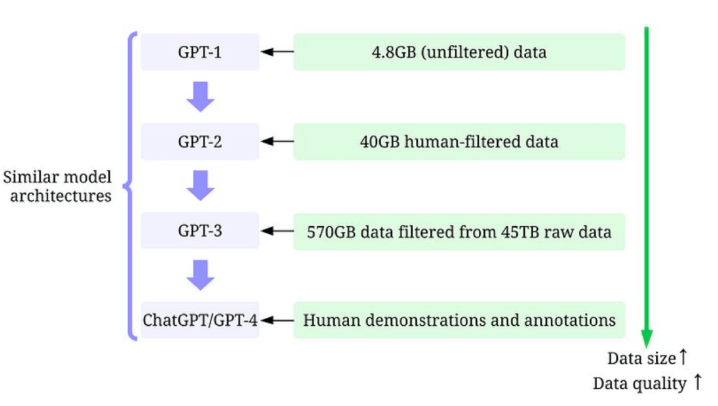
GPT-1采用了預訓練的方式進行學習,即在大規模語料庫上進行訓練。該模型的輸入是文本序列,輸出則是下一個單詞或短語的概率分布。這些模型的優勢在于可以利用海量的數據進行訓練,從而學習到一些常見的語言規律和模式。此外,GPT-1還可以進行文本生成、分類和序列標注等任務,表現優異。
GPT系列模型的后續版本主要區別在于它們具有更多的參數。例如,GPT-2的參數數量是GPT-1的10倍,為1.5億個。GPT-2采用了更多的自注意力頭,使得模型能夠學習到更加復雜的語言結構。同時,它還具有Zero-shot Learning和Few-Shot Learning技術,可以更好地適應新任務的執行和學習。

而GPT-3則是GPT系列模型的最大版本,其參數數量高達1750億個。GPT-3不僅在文本生成方面表現出色,還可以進行問答、對話等更為復雜的任務。該模型擁有很強的適應性和靈活性,且能夠從零樣本或少樣本學習中進行新任務的執行和學習。
總的來說,大語言模型的發展讓自然語言處理領域取得了巨大的進展,使得我們可以更加高效地處理文本和自然語言相關的任務。隨著技術的不斷創新和突破,我們相信大語言模型將會在未來發揮出更加重要的作用。通過更好地研究和應用大語言模型,我們有望解決更多實際問題,使得機器學習和人工智能更加貼近現實生活,更好地服務于人類社會。





