
西風 發(fā)自 凹非寺
量子位 | 公眾號 QbitAI
GPT-4官方使用指南炸裂登場啦!
你沒聽錯,這次不需要自己做筆記了,OpenAI親自幫你整理了一份。
據(jù)說匯聚了大伙兒6個月的使用經(jīng)驗,你、我、他的提示訣竅都融匯其中。
雖然總結下來只有 六大策略,但該有的細節(jié)可絕不含糊。
不僅普通GPT-4用戶可以在這份秘籍中get提示技巧,或許應用開發(fā)者也可以找到些許靈感。
網(wǎng)友們紛紛評論,給出了自己的“讀后感”:
好有意思啊!總結來說,這些技巧的核心思想主要有兩點。一是我們得寫得更具體一些,給一些細節(jié)的提示。其次,對于那些復雜的任務,我們可以把它們拆分成一些小的提示來完成。
OpenAI表示,這份攻略目前僅針對GPT-4。(當然,你也可以在其它GPT模型上試試?)
趕緊瞧瞧,這份秘籍里究竟都有啥好東西。
6大干貨技巧全在這 策略一:寫清楚指令
要知道,模型可不會“讀心術”,所以你得把你的要求明明白白地寫出來。
當模型輸出變得太啰嗦時,你可以要求它回答簡潔明了。相反地,如果輸出太過簡單,你可以毫不客氣地要求它用專業(yè)水平來寫。
如果你對GPT輸出的格式不滿意,那就先給它展示你期望的格式,并要求它以同樣的方式輸出。
總之,盡量別讓GPT模型自己去猜你的意圖,這樣你得到的結果就更可能符合你的預期了。
實用技巧:
1、有細節(jié)才能得到更相關的答案
為了使輸出和輸入具有強相關性,一切重要的細節(jié)信息,都可以喂給模型。
比如你想讓GPT-4:總結會議記錄
就可以盡可能在表述中增加細節(jié):
將會議記錄總結成一段文字。然后編寫一個Markdown列表,列出與會人員及其主要觀點。最后,如果與會人員有關于下一步行動的建議,請列出來。

2、要求模型扮演特定角色
通過改變系統(tǒng)消息(system message),GPT-4會更容易扮演特定的角色,比在對話中提出要求的重視程度更高。
如規(guī)定它要回復一個文件,這份文件中的每個段落都要有好玩的評論:
3、用分隔符清晰標示輸入的不同部分
用"""三重引號"""、<XML標記> 、節(jié)標題等分隔符標記出文本的不同部分,可以更便于模型進行不同的處理。在復雜的任務中,這種標記細節(jié)就顯得格外重要。
4、明確指定完成任務所需的步驟
有些任務按步驟進行效果更佳。因此,最好明確指定一系列步驟,這樣模型就能更輕松地遵循這些步驟,并輸出理想結果。比如在系統(tǒng)消息中設定按怎樣的步驟進行回答。

5、提供示例
如果你想讓模型輸出按照一種不是能夠很好描述出來的特定樣式,那你就可以提供示例。如提供示例后,只需要告訴它“教我耐心”,它就會按照示例的風格,將其描述得生動形象。

6、指定所需輸出長度
你還可以要求模型具體生成多少個單詞、句子、段落、項目符號等。但是,在要求模型生成特定數(shù)量的單詞/字的時候,它有可能不會那么精準。
策略二:提供參考文本
當涉及到深奧的話題、引用和URL等內容時,GPT模型可能會一本正經(jīng)地胡說八道。
為GPT-4提供可以參考的文本,能夠減少虛構性回答的出現(xiàn),使回答的內容更加可靠。
實用技巧:
1、讓模型參照參考資料進行回答
如果我們能夠向模型提供一些和問題有關的可信信息,就可以指示它用提供的信息來組織回答。
2、讓模型引用參考資料進行回答
如果在上面的對話輸入中已經(jīng)補充了相關信息,那么我們還可以直接要求模型在回答中引用所提供的信息。
這里要注意的是,可以通過編程,對讓模型對輸出中引用的部分進行驗證注釋。

策略三:拆分復雜任務
相比之下,GPT-4在應對復雜任務時出錯率更高。
然而,我們可以采取一種巧妙的策略,將這些復雜任務重新拆解成一系列簡單任務的工作流程。
這樣一來,前面任務的輸出就可以被用于構建后續(xù)任務的輸入。
就像在軟件工程中將一個復雜系統(tǒng)分解為一組模塊化組件一樣,將任務分解成多個模塊,也可以讓模型的表現(xiàn)更好。
實用技巧:
1、進行意圖分類
對于需要處理不同情況的大量具有獨立性的任務,可以先對這些任務進行分類。
然后,根據(jù)分類來確定所需的指令。
比如,對于客戶服務應用程序,可以進行查詢分類(計費、技術支持、賬戶管理、一般查詢等)。
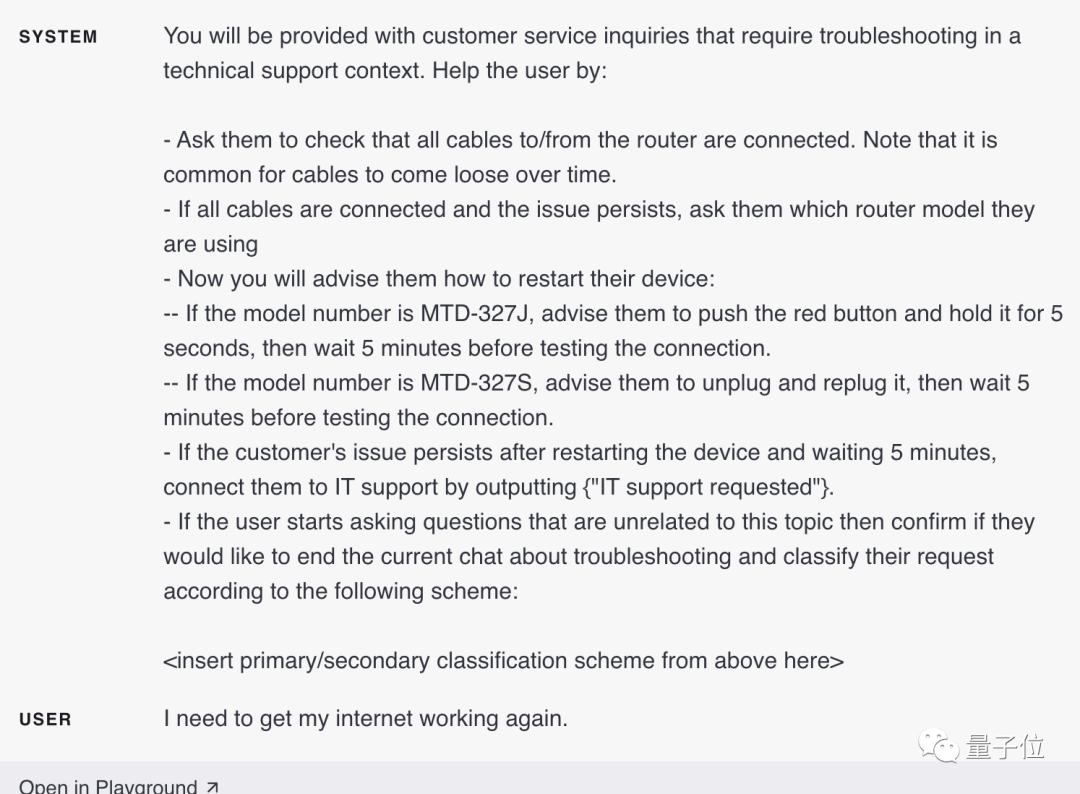
當用戶提出:
我需要讓我的互聯(lián)網(wǎng)重新恢復正常。
根據(jù)用戶查詢的分類,可以鎖定用戶的具體訴求了,就可以向GPT-4提供一組更具體的指令,來進行下一步操作。
例如,假設用戶需要在“故障排除”方面尋求幫助。
就可以設定下一步的方案:
要求用戶檢查路由器的所有電纜是否已連接……
2、對先前對話進行概括或篩選
由于GPT-4的對話窗口是有限制的,上下文不能太長,不能在一個對話窗口中無限進行下去。
但也不是沒有解決辦法。
方法之一是對先前的對話進行概括。一旦輸入的文本長度達到預定的閾值,就可以觸發(fā)一個查詢,概括對話的一部分,被概括出來的這部分內容可以變成系統(tǒng)消息的一部分。
此外,可以在對話過程中就在后臺對前面的對話進行概括。
另一種方法是檢索先前的對話,使用基于嵌入的搜索實現(xiàn)高效的知識檢索。
3、逐段概括長文檔,并遞歸構建完整概述
還是文本過長的問題。
比如你要讓GPT-4概括一本書,就可以使用一系列查詢來概括這本書的每個部分。
然后將部分概述連接起來進行總結,匯成一個總的答案。
這個過程可以遞歸進行,直到整本書被概括。
但是有些部分可能要借前面部分的信息才能理解后續(xù)部分,這里有一個技巧:
在概括當前內容時,將文本中當前內容之前的內容概述一起總結進來,進行概括。
簡單來說,用前面部分的“摘要”+當前部分,然后進行概括。
OpenAI之前還使用基于GPT-3訓練的模型,對概括書籍的效果進行了研究。
策略四:給GPT時間“思考”
如果讓你計算17乘28,你可能不會立刻知道答案,但是可以通過一些時間計算出來。
同樣的道理,當GPT-4接收到問題時,它并不會花時間仔細思考,而是試圖立刻給出答案,這樣就可能導致推理出錯。
因此,在讓模型給出答案前,可以先要求它進行一系列的推理過程,幫助它通過推理來得出正確的答案。
實用技巧:
1、讓模型制定解決方案
你可能有時候會發(fā)現(xiàn),當我們明確指示模型在得出結論之前從基本原理出發(fā)進行推理時,我們可以獲得更好的結果。
比如說,假設我們希望模型評估學生解答數(shù)學問題的方案。
最直接的方法是簡單地詢問模型學生的解答是否正確。

在上圖中,GPT-4認為學生的方案是正確的。
但實際上學生的方案是錯誤的。
這時候就可以通過提示模型生成自己的解決方案,來讓模型成功注意到這一點。

在生成了自己的解決方案,進行一遍推理過后,模型意識到之前學生的解決方案不正確。
2、隱藏推理過程
上面講到了讓模型進行推理,給出解決方案。
但在某些應用中,模型得出最終答案的推理過程不適合與用戶共享。
比如,在作業(yè)輔導中,我們還是希望鼓勵學生制定自己的解題方案,然后得出正確答案。但模型對學生解決方案的推理過程可能會向學生揭示答案。
這時候我們就需要模型進行“內心獨白”策略,讓模型將輸出中要對用戶隱藏的部分放入結構化格式中。
然后,在向用戶呈現(xiàn)輸出之前,對輸出進行解析,并且僅使部分輸出可見。
就像下面這個示例:
先讓模型制定自己的解決方案(因為學生的有可能是錯的),然后與學生的解決方案進行對比。
如果學生的答案中哪一步出錯了,那就讓模型針對這一步給出一點提示,而不是直接給學生完整的正確的解決方案。
如果學生還是錯了,那就再進行上一步的提示。

還可以使用“查詢”策略,其中除了最后一步的查詢以外,所有查詢的輸出都對用戶隱藏。
首先,我們可以要求模型自行解決問題。由于這個初始查詢不需要學生的解決方案,因此可以省略掉。這也提供了額外的優(yōu)勢,即模型的解決方案不會受到學生解決方案偏見的影響。
接下來,我們可以讓模型使用所有可用信息來評估學生解決方案的正確性。

最后,我們可以讓模型使用自己的分析來構建導師的角色。
你是一名數(shù)學導師。如果學生回答有誤,請以不透露答案的方式向學生進行提示。如果學生答案無誤,只需給他們一個鼓勵性的評論。
3、詢問模型是否遺漏了內容
假設我們正在讓GPT-4列出一個與特定問題相關的源文件摘錄,在列出每個摘錄之后,模型需要確定是繼續(xù)寫入下一個摘錄,還是停止。
如果源文件很大,模型往往會過早地停止,未能列出所有相關的摘錄。
在這種情況下,通常可以讓模型進行后續(xù)查詢,找到它在之前的處理中遺漏的摘錄。
換而言之,模型生成的文本有可能很長,一次性生成不完,那么就可以讓它進行查驗,把遺漏的內容再補上。

策略五:其它工具加持
GPT-4雖然強大,但并非萬能。
我們可以借助其他工具來補充GPT-4的不足之處。
比如,結合文本檢索系統(tǒng),或者利用代碼執(zhí)行引擎。
在讓GPT-4回答問題時,如果有一些任務可以由其他工具更可靠、更高效地完成,那么我們可以將這些任務交給它們來完成。這樣既能發(fā)揮各自的優(yōu)勢,又能讓GPT-4發(fā)揮最佳水平。
實用技巧:
1、使用基于嵌入的搜索實現(xiàn)高效的知識檢索
這一技巧在上文中已經(jīng)有所提及。
若在模型的輸入中提供額外的外部信息,有助于模型生成更好的回答。
例如,如果用戶詢問關于一部特定電影的問題,將關于電影的信息(例如演員、導演等)添加到模型的輸入中可能會很有用。
嵌入可用于實現(xiàn)高效的知識檢索,可以在模型運行時動態(tài)地將相關信息添加到模型的輸入中。
文本嵌入是一種可以衡量文本字符串相關性的向量。相似或相關的字符串將比不相關的字符串更緊密地結合在一起。加上快速向量搜索算法的存在,意味著可以使用嵌入來實現(xiàn)高效的知識檢索。
特別的是,文本語料庫可以分成多個部分,每個部分可以進行嵌入和存儲。然后,給定一個查詢,可以進行向量搜索以找到與查詢最相關的語料庫中的嵌入文本部分。
2、使用代碼執(zhí)行進行更準確的計算或調用外部API
不能僅依靠模型自身進行準確地計算。
如果需要,可以指示模型編寫和運行代碼,而不是進行自主計算。
可以指示模型將要運行的代碼放入指定的格式中。在生成輸出后,可以提取和運行代碼。生成輸出后,可以提取并運行代碼。最后,如果需要,代碼執(zhí)行引擎(即Python/ target=_blank class=infotextkey>Python解釋器)的輸出可以作為下一個輸入。
代碼執(zhí)行的另一個很好的應用場景是調用外部API。
如果將API的正確使用方式傳達給模型,它可以編寫使用該API的代碼。
可以通過向模型演示文檔和/或代碼示例來指導模型如何使用API。
在這里OpenAI提出了特別警告??:
策略六:系統(tǒng)地測試更改執(zhí)行模型生成的代碼在本質上來說并不安全,任何試圖執(zhí)行此操作的應用程序中都應采取預防措施。特別是,需要一個沙盒代碼執(zhí)行環(huán)境來限制不受信任的代碼可能造成的危害。
有時候很難確定一個改變是會讓系統(tǒng)變得更好還是更差。
通過觀察一些例子有可能會看出哪個更好,但是在樣本數(shù)量較少的情況下,很難區(qū)分是真的得到了改進,還是只是隨機運氣。
也許這個“改變”能夠提升某些輸入的效果,但卻會降低其它輸入的效果。
而評估程序(evaluation procedures,or “evals”)對于優(yōu)化系統(tǒng)設計來說非常有用。好的評估有以下幾個特點:
1)代表現(xiàn)實世界的用法(或至少是多種用法)
2)包含許多測試用例,可以獲得更大的統(tǒng)計功效(參見下表)
3)易于自動化或重復

對輸出的評估可以是由計算機進行評估、人工評估,或者兩者結合進行。計算機可以使用客觀標準自動評估,也可以使用一些主觀或模糊的標準,比如說用模型來評估模型。
OpenAI提供了一個開源軟件框架——OpenAI Evals,提供了創(chuàng)建自動評估的工具。
當存在一系列質量同樣高的輸出時,基于模型的評估就會很有用。
實用技巧:
1、參考黃金標準答案評估模型輸出
假設已知問題的正確答案應參考一組特定的已知事實。
然后,我們可以詢問模型答案中包含多少必需的事實。
例如,使用下面這個系統(tǒng)消息,
給出必要的既定事實:
尼爾·阿姆斯特朗是第一個在月球上行走的人。
尼爾·阿姆斯特朗第一次登上月球的日期是1969年7月21日。
如果答案中包含既定給出的事實,模型會回答“是”。反之,模型會回答“否”,最后讓模型統(tǒng)計有多少“是”的答案:

下面是包含兩點既定事實的示例輸入(既有事件,又有時間):
僅滿足一個既定事實的示例輸入(沒有時間):
而下面這個示例輸入,不包含任何一個既定事實:
這種基于模型的評估方法有許多可能的變化形式,需要跟蹤候選答案與標準答案之間的重疊程度,并追蹤候選答案是否與標準答案的有相矛盾的地方。

比如下面的這個示例輸入,其中包含不合標準的答案,但與專家答案(標準答案)并不矛盾:

下面是這個示例輸入,其答案與專家答案直接矛盾(認為尼爾·阿姆斯特朗是第二個在月球上行走的人):

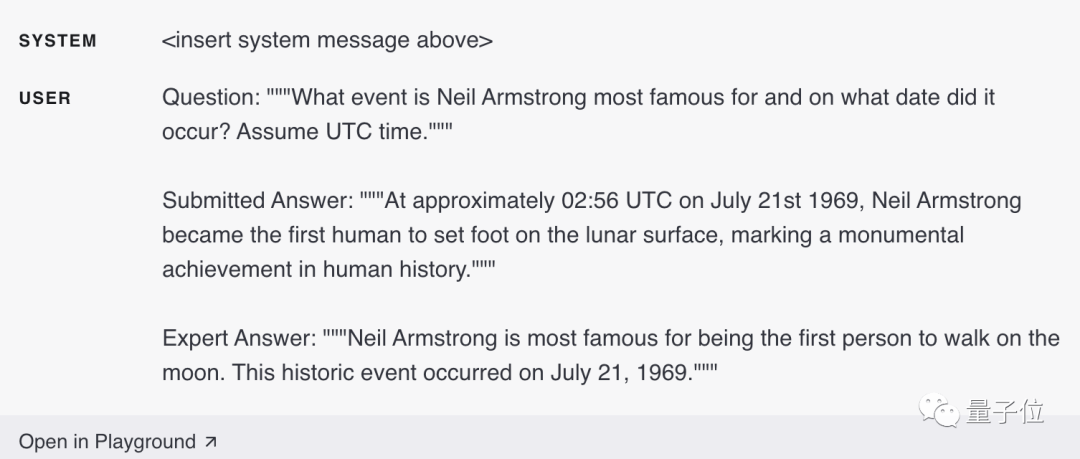
最后一個是帶有正確答案的示例輸入,該輸入還提供了比必要內容更多的詳細信息(時間精確到了02:56,并指出了這是人類歷史上的一項不朽成就):
傳送門:
https://Github.com/openai/evals (OpenAIEvals)
參考鏈接:
[1]https://platform.openai.com/docs/guides/gpt-best-practices
[2]https://www.reddit.com/r/OpenAI/comments/141yheo/openai_recently_added_a_gpt_best_practices_guide/
— 完—





