擊這里在線咨詢客服")

新智元報道
編輯:拉燕
【新智元導(dǎo)讀】UC伯克利華人博士生搞了個Gorilla,可以靈活調(diào)用各種API,性能超過GPT-4。
繼羊駝之后,又來了個以動物命名的模型,這次是大猩猩(Gorilla)。
雖說目前LLM風(fēng)頭正旺,進(jìn)展頗多,在各種任務(wù)中的性能表現(xiàn)也可圈可點(diǎn),但這些模型通過API調(diào)用有效使用工具的潛力還亟待挖掘。
即使對于今天最先進(jìn)的LLM,比如GPT-4,API調(diào)用也是一項(xiàng)具有挑戰(zhàn)性的任務(wù),主要是由于它們無法生成準(zhǔn)確的輸入?yún)?shù),并且LLM容易對API調(diào)用的錯誤使用產(chǎn)生幻覺。
這不,研究人員搞了個Gorilla,一個經(jīng)過微調(diào)的基于LLaMA的模型,它在編寫API調(diào)用上的性能甚至超過了GPT-4。
而當(dāng)與文檔檢索器相結(jié)合時,Gorilla同樣展示出了強(qiáng)大的性能,使用戶更新或版本變化變得更加靈活。
此外,Gorilla還大大緩解了LLM會經(jīng)常遇到的幻覺問題。
為了評估該模型的能力,研究人員還引入了API基準(zhǔn),一個由HuggingFace、TorchHub和TensorHub API組成的綜合數(shù)據(jù)集
Gorilla
LLMs的各項(xiàng)強(qiáng)大的能力不用再多介紹,包括自然對話能力、數(shù)學(xué)推理能力,以及程序合成在能力什么的。
然而,盡管性能強(qiáng)大,但LLM仍然會受到一些限制。并且,LLM也需要重新訓(xùn)練以及時更新他們的知識庫,以及推理能力。
通過授權(quán)LLM可使用的工具,研究人員可以允許LLM訪問巨大的、不斷變化的知識庫,完成復(fù)雜的計算任務(wù)。
通過提供對搜索技術(shù)和數(shù)據(jù)庫的訪問,研究人員可以增強(qiáng)LLM的能力,以處理更大和更動態(tài)的知識空間。
同樣,通過提供計算工具的使用,LLM也可以完成復(fù)雜的計算任務(wù)。
因此,科技巨頭已經(jīng)開始嘗試整合各類插件,使LLM能夠通過API調(diào)用外部工具。
從一個規(guī)模較小的手工編碼的工具,到能夠調(diào)用一個巨大的、不斷變化的云API空間,這種轉(zhuǎn)變可以將LLM轉(zhuǎn)變?yōu)橛嬎慊A(chǔ)設(shè)施,以及網(wǎng)絡(luò)所需的主要界面。
從預(yù)訂整個假期到舉辦一次會議的任務(wù),可以變得像與能夠訪問航班、汽車租賃、酒店、餐飲和娛樂網(wǎng)絡(luò)API的LLM交談一樣簡單。
然而,許多先前的工作將工具整合到LLM中,考慮的是一小套有據(jù)可查的API,可以很容易地注入到提示中。
支持一個由潛在的數(shù)百萬個變化的API組成的網(wǎng)絡(luò)規(guī)模的集合,需要重新思考研究人員如何整合工具的方法。
現(xiàn)在已經(jīng)不可能在一個單一的環(huán)境中描述所有的API了。許多API會有重疊的功能,有細(xì)微的限制和約束。在這種新的環(huán)境中簡單地評估LLM需要新的基準(zhǔn)。
在本文中,研究人員探索了使用自我結(jié)構(gòu)微調(diào)和檢索的方法,以使LLM能夠準(zhǔn)確地從使用其API和API文檔表達(dá)的大量、重疊和變化的工具集中進(jìn)行選擇。
研究人員通過從公共模型中心刮取ML API(模型)來構(gòu)建API Bench,這是一個具有復(fù)雜且經(jīng)常重疊功能的大型API語料庫。
研究人員選擇了三個主要的模型中心來構(gòu)建數(shù)據(jù)集:TorchHub、TensorHub和HuggingFace。
研究人員詳盡地包括了TorchHub(94個API調(diào)用)和TensorHub(696個API調(diào)用)中的每一個API調(diào)用。
對于HuggingFace,由于模型的數(shù)量很大,所以研究人員選擇了每個任務(wù)類別中下載最多的20個模型(總共925個)。
研究人員還使用Self-Instruct為每個API生成了10個用戶問題的prompt。
因此,數(shù)據(jù)集中的每個條目都成為了一個指令參考API對。研究人員采用常見的AST子樹匹配技術(shù)來評估生成的API的功能正確性。
研究人員首先將生成的代碼解析成AST樹,然后找到一個子樹,其根節(jié)點(diǎn)是研究人員關(guān)心的API調(diào)用,然后使用它來索引研究人員的數(shù)據(jù)集。
研究人員檢查LLMs的功能正確性和幻覺問題,反饋相應(yīng)的準(zhǔn)確性。然后,研究人員再對Gorilla進(jìn)行微調(diào),這是一個基于LLaMA-7B的模型,使用研究人員的數(shù)據(jù)集進(jìn)行文檔檢索的操作。
研究人員發(fā)現(xiàn),Gorilla在API功能準(zhǔn)確性以及減少幻覺錯誤方面明顯優(yōu)于GPT-4。
研究人員在圖1中展示了一個實(shí)例。

此外,研究人員對Gorilla進(jìn)行的檢索感知訓(xùn)練使得該模型能夠適應(yīng)API文檔的變化。
最后,研究人員還展示了Gorilla理解和推理約束的能力。
另外,在幻覺方面,Gorilla也表現(xiàn)出色。
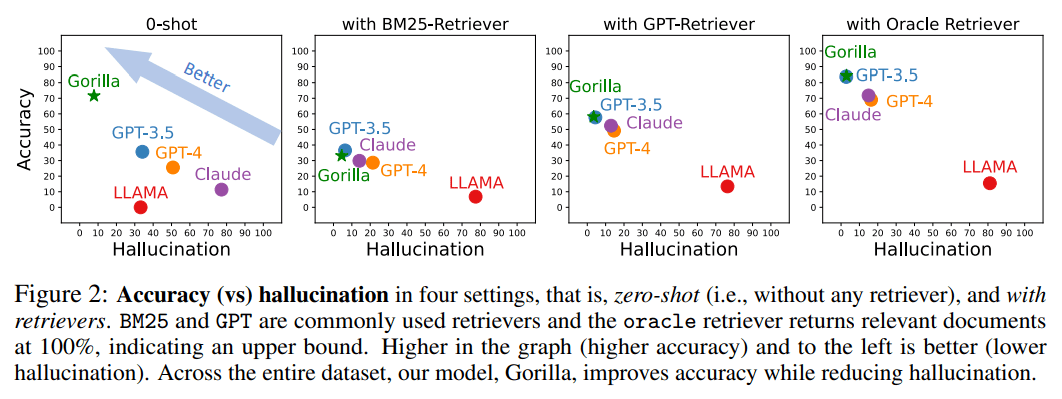
下圖是精度和幻覺在四種情況下的對比,零樣本(即,沒有任何檢索器)以及使用BM25、GPT和Oracle的檢索器。
其中BM25和GPT是常用的檢索器,而Oracle檢索器則會以100%的相關(guān)性返回相關(guān)文檔,表示一種上限。
圖中準(zhǔn)確性更高、幻覺更少的即為效果更好。
在整個數(shù)據(jù)集中,Gorilla在提高準(zhǔn)確性的同時減少了幻覺。
為了收集數(shù)據(jù)集,研究人員細(xì)致地記錄了HuggingFace的The Model Hub、PyTorch Hub和TensorFlow Hub模型的所有在線模型。
然而,其中很多模型的文檔都不咋樣。
為了過濾掉這些質(zhì)量不高的模型,研究人員最終從每個領(lǐng)域挑選出前20個模型。
研究人員考慮了多模態(tài)數(shù)據(jù)的7個領(lǐng)域,CV的8個領(lǐng)域,NLP的12個領(lǐng)域,音頻的5個領(lǐng)域,表格數(shù)據(jù)的2個領(lǐng)域,以及強(qiáng)化學(xué)習(xí)的2個領(lǐng)域。
過濾后,研究人員從HuggingFace得到了總共925個模型。TensorFlow Hub的版本分為v1和v2。
最新的版本(v2)總共有801個模型,研究人員處理了所有的模型。在過濾掉幾乎沒有信息的模型后,剩下了626個模型。
與TensorFlow Hub類似,研究人員從Torch Hub得到95個模型。
在self-instruct范式的指導(dǎo)下,研究人員采用GPT-4來生成合成指令數(shù)據(jù)。
研究人員提供了三個語境中的例子,以及一個參考的API文檔,并責(zé)成模型生成調(diào)用API的真實(shí)用例。
研究人員特別指示該模型在創(chuàng)建指令時不要使用任何API名稱或提示。研究人員為三個模型中心的每一個構(gòu)建了六個例子(指令-API對)。
這18個點(diǎn),是唯一手工生成或者修改過的數(shù)據(jù)。
而Gorilla,則是檢索感知的LLaMA-7B模型,專門用于API調(diào)用。
如圖3所示,研究人員采用自我構(gòu)造來生成{指令,API}對。
為了對LLaMA進(jìn)行微調(diào),研究人員將其轉(zhuǎn)換為用戶——代理的聊天式對話,其中每個數(shù)據(jù)點(diǎn)都是一個對話,用戶和代理輪流交談。
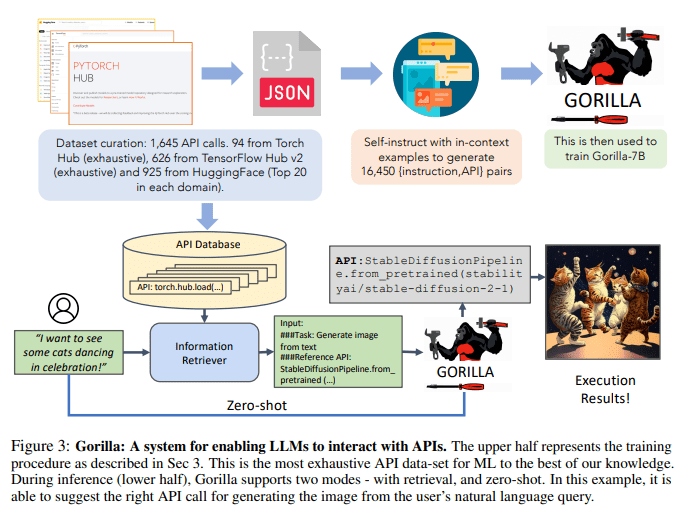
然后研究人員在基礎(chǔ)的LLaMA-7B模型上進(jìn)行標(biāo)準(zhǔn)的指令微調(diào)。在實(shí)驗(yàn)中,研究人員在有和沒有檢索器的情況下分別訓(xùn)練了Gorilla。
由于API的功能是一種通用語言,使不同的系統(tǒng)之間能夠進(jìn)行有效地溝通,正確使用API可以提高LLM與更廣泛的工具進(jìn)行互動的能力。
在研究人員收集的三個大規(guī)模數(shù)據(jù)集中,Gorilla的性能超過了最先進(jìn)的LLM(GPT-4)。Gorilla產(chǎn)生了可靠的API調(diào)用ML模型,且沒有產(chǎn)生幻覺,并能在挑選API時滿足約束條件。
由于希望找到一個具有挑戰(zhàn)性的數(shù)據(jù)集,研究人員選擇了ML APIs,因?yàn)樗鼈兊墓δ芟嗨啤W⒂贛L領(lǐng)域的API的潛在缺點(diǎn)是,如果在有傾向的數(shù)據(jù)上進(jìn)行訓(xùn)練,它們就有可能產(chǎn)生有偏見的預(yù)測,可能對某些子群體不利。
為了消除這種顧慮并促進(jìn)對這些API的深入了解,研究人員正在發(fā)布更加廣泛的數(shù)據(jù)集,其中包括超過11000個指令——API對。
在下圖這個示例中,研究人員使用抽象語法樹(AST)子樹匹配來評估API調(diào)用的正確性。
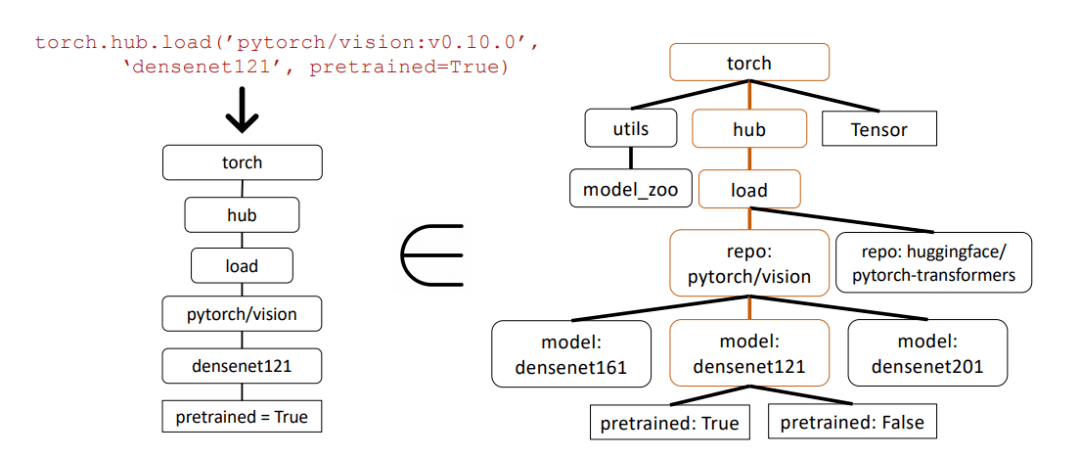
抽象語法樹是源代碼結(jié)構(gòu)的樹形表示,有助于更好地分析和理解代碼。
首先,研究人員從Gorilla返回的API調(diào)用(左側(cè))構(gòu)建相關(guān)的API樹。然后將其與數(shù)據(jù)集進(jìn)行比較,以查看API數(shù)據(jù)集是否具有子樹匹配。
在上面的示例中,匹配的子樹以棕色突出顯示,表示API調(diào)用確實(shí)是正確的。其中PretrAIned=True是一個可選參數(shù)。
這一資源將為更廣泛的社區(qū)提供服務(wù),作為研究和衡量現(xiàn)有API的寶貴工具,為更公平和優(yōu)化使用機(jī)器學(xué)習(xí)做出貢獻(xiàn)。
參考資料:
https://arxiv.org/pdf/2305.15334.pdf





