
編譯 | 言征
最近,ChatGPT Plus 的用戶一直反映該平臺及其底層 LLM (GPT-4) 的性能嚴重下降(編程準確率也暴降13%)。
這是繼最近一系列更新之后的結果,包括為 Plus 訂閱者提供網絡瀏覽和擴展插件訪問權限。在這些更新之后,該服務的工作量大大增加,人們開始注意到 GPT-4 異常快速的響應時間突然變得不那么令人“驚艷”了。
如果功能和性能受到限制,那么有些人開始取消他們的 Plus 訂閱當然是有道理的。許多人將轉向開源 AI 語言模型,似乎成了無聲的回應。
一、網友主流觀點
目前對此,不少猜測和假想充斥在有關社區。有一些較為流行的觀點:ChatGPT 明顯的性能下降可能來自“模型的縮放痛苦”,即,降低 GPT-4 的推理能力似乎是平衡響應速度的一種可能的解決方法,對于 OpenAI 的開發人員來說,這是一個不難想到的解決方案。
還有評論指出,盡管互聯網接入帶來了額外好處, 最近甚至發現 OpenAI 的 GPT-4 在速度方面優于 Azure 的 GPT-4 模型,但 ChatGPT 的編碼輸出已經出現嚴重降級。
二、另一個原因:安全性AI對齊
再一個原因,近期,Sam Altman 和其他科技巨頭最近挺身而出,聲稱他們需要防止“AI 滅絕的風險”。這樣看來,ChatGPT 的推理和可用性下降,似乎與 AI 行業領導者承認“人工智能,尤其是新興的 AGI 的潛在危險性”的時間相吻合。
可能是由于 OpenAI 出于對安全性考量而對其所進行的過度 AI 對齊。簡單來說,AI 對齊就是確保人工智能系統的目標與人類價值觀一直,使其符合設計者的利益預期,不會產生意外的有害后果,例如輸出涉及種族、政治等敏感信息。
而就在近期,由微軟研究院發布的一篇論文中提到了這樣的觀點:對 AI 模型所進行的任何 AI 對齊,都會損失模型的準確性和性能。論文主要作者 Sebastien Bubeck 在一次發言中敘述了大模型經過 AI 對齊后所出現的問題。當接收到“利用 TikZ 繪圖工具繪制獨角獸”的指令后,未經 AI 對齊的 GPT-4 模型給出了這樣的結果。
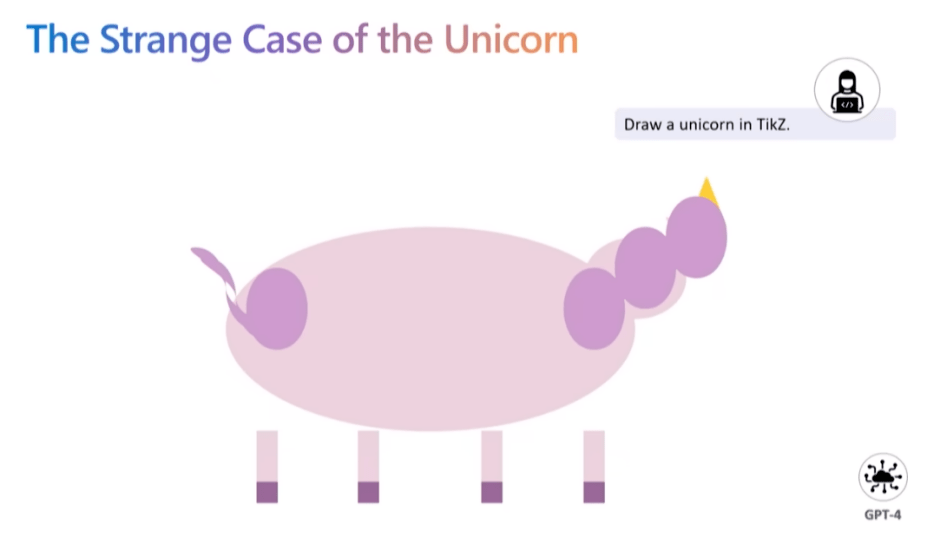
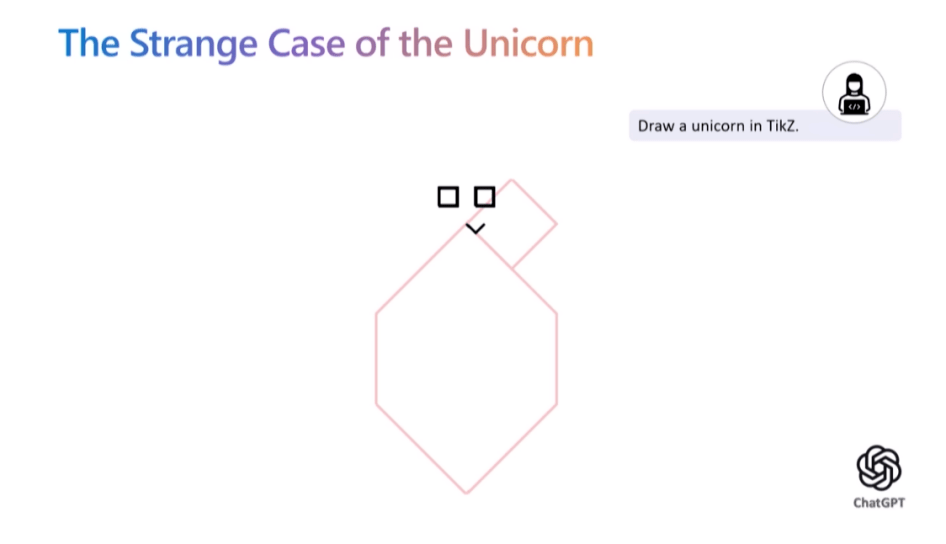
然而當實驗員將相同需求提供給集成 GPT-4 模型并進行了安全性 AI 對齊的ChatGPT 后,圖像的輸出質量卻下降了一大截。對此,Sebastien Bubeck 解釋稱,相較于 GPT-4,ChatGPT 利用了更多基于人類反饋的強化學習來構建護欄,然而根據古德哈特定律,獎勵模型并不是一個完美的代理,因此過度的 AI 對齊會阻礙模型對任務理解的真實程度。
三、Sam Altman 宣布新的 OpenAI 計劃
上周,Humanloop 的 CEO Raza 與 Sam Altman 和其他 20 位開發人員坐下來討論 OpenAI 的 API 及其產品計劃。Sam 非常開放,熱情討論了許多有關 OpenAI 很尖銳的問題。以下是要點:
1.OpenAI 目前嚴重受 GPU 限制
整個討論中出現的一個共同主題是,目前 OpenAI 非常受 GPU 限制,這推遲了他們的許多短期計劃。最大的客戶抱怨是關于 API 的可靠性和速度。Sam 承認他們的擔憂,并解釋說大部分問題是 GPU 短缺造成的。
更長的 32k 上下文還不能推廣給更多人。OpenAI 還沒有克服注意力的 O(n^2) 縮放,因此雖然看起來很有可能他們很快就會有 100k - 1M 令牌上下文窗口(今年)任何更大的東西都需要研究突破。
微調 API 目前也受到 GPU 可用性的瓶頸。他們還沒有使用適配器或LoRa等高效的微調方法,因此微調的運行和管理需要大量計算。將來會更好地支持微調。他們甚至可能舉辦社區貢獻模型的市場。
專用容量產品受 GPU 可用性的限制。OpenAI 還提供專用容量,為客戶提供模型的私有副本。要獲得這項服務,客戶必須愿意預先支付 10 萬美元。
2.OpenAI 的近期路線圖
Sam 分享了他所看到的 OpenAI 的 API 臨時近期路線圖。
2023
(1)更便宜更快的 GPT-4——這是他們的首要任務。總的來說,OpenAI 的目標是盡可能降低“智能成本”,因此隨著時間的推移,他們將努力繼續降低 API 的成本。
(2)更長的上下文窗口——在不久的將來,上下文窗口可能高達 100 萬個 token。
(3)F.NETuning API——微調 API 將擴展到最新的模型,但具體形式將取決于開發人員表示他們真正想要的東西。
(4)有狀態的 API——當你今天調用聊天 API 時,你必須反復傳遞相同的對話歷史并一次又一次地為相同的令牌付費。將來會有一個記住對話歷史記錄的 API 版本。
2024
(5)多模態——這是作為 GPT-4 版本的一部分進行演示的,但在更多 GPU 上線之前不能擴展到所有人。
3.插件“沒有 PMF”并且可能不會很快出現在 API 中
許多開發人員對通過 API 訪問 ChatGPT 插件很感興趣,但 Sam 表示他認為這些插件不會很快發布。除了瀏覽之外,插件的使用表明它們還沒有 PMF。他建議很多人認為他們希望他們的應用程序在 ChatGPT 中,但他們真正想要的是他們應用程序中的 ChatGPT。
4.OpenAI 將避免與他們的客戶競爭——除了 ChatGPT
不少開發人員表示,當 OpenAI 可能最終發布對他們具有競爭力的產品時,他們對使用 OpenAI API 進行構建感到緊張。Sam 表示 OpenAI 不會發布 ChatGPT 以外的更多產品。他說,偉大的平臺公司擁有殺手級應用程序的歷史由來已久,而 ChatGPT 將允許他們通過成為自己產品的客戶來改進 API。ChatGPT 的愿景是成為工作的超級智能助手,但還有許多 OpenAI 不會觸及的其他 GPT 用例。
5.需要監管,但也需要開源
雖然 Sam 呼吁對未來的模型進行監管,但他認為現有模型并不危險,并認為監管或禁止它們將是一個大錯誤。他重申了他對開源重要性的信念,并表示 OpenAI 正在考慮開源 GPT-3。他們尚未開源的部分原因是他懷疑有多少個人和公司有能力托管和服務大型 LLM。
6.大模型定律仍然成立
最近有很多文章聲稱“巨型 AI 模型的時代已經結束”。這并不準確。OpenAI 的內部數據表明,模型性能的比例定律繼續存在,使模型變大將繼續產生性能。
沒錯,擴展的速度無法維持,因為 OpenAI 在短短幾年內就將模型放大了數百萬倍,而這種做法在未來將無法持續。這并不意味著 OpenAI 不會繼續嘗試讓模型變得更大,這只是意味著它們的規模每年可能會增加一倍或三倍,而不是增加許多數量級。
擴大規模繼續起作用的事實對 AGI 開發的時間表具有重大影響。大模型假設是這樣一種想法,即我們可能擁有構建 AGI 所需的大部分內容,并且大部分剩余工作將采用現有方法并將它們擴展到更大的模型和更大的數據集。如果大模型時代已經結束,那么也就意味著 AGI 離我們更遠了。也就是說,大模型定律繼續成立的事實,強烈暗示了更短的 AGI 時間表。





