擊這里在線咨詢客服")
GPT-4的發(fā)布給ChatGPT帶來了又一次飛躍,ChatGPT不僅支持文字輸入,還能看得懂圖片、甚至是漫畫、梗圖,以GPT-4為代表的多模態(tài)大模型非常強(qiáng)大。多模態(tài)大模型就是指模型可以處理多種結(jié)構(gòu)/類型的數(shù)據(jù),例如GPT-4,它既可以處理你輸入的文本,也可以處理你上傳的圖片。
那么,多模態(tài)到底意味著什么呢?
1. 什么是多模態(tài)?
人類有五種基本感官:觸覺、視覺、聽覺、嗅覺和味覺。與每一種感覺相關(guān)的感覺器官向大腦發(fā)送信息,幫助我們理解和感知我們周圍的世界。然而,事實(shí)上,除了這五種基本的感官之外,還有其他的人類感官是你生活中必不可少的。這些鮮為人知的感覺包括空間意識(shí)和平衡等。通過這些感官的交互,也就是多模態(tài),以下是最常見的幾種模態(tài):

GPT-4專注于語言和視覺作為一些基本的模態(tài)。所謂融合,是指將來自兩個(gè)或多個(gè)模態(tài)的信息合并以執(zhí)行預(yù)測(cè)任務(wù)。有兩種類型的融合:- 早期融合:模態(tài)將在訓(xùn)練早期就連接起來。- 晚期融合:我需要在每個(gè)模態(tài)早期進(jìn)行一些處理,然后再將它們組合起來。
看一些現(xiàn)實(shí)世界的例子,了解什么是MMML應(yīng)用:

2. 單模態(tài)分類模型及一些基本概念
從單模態(tài)的分類模型開始,分析視覺、文本和聲音模態(tài)的基本處理方法,還試圖澄清了數(shù)據(jù)集、最近鄰居、神經(jīng)網(wǎng)絡(luò)基礎(chǔ)、推理和模型參數(shù)等相關(guān)術(shù)語和概念。
2.1 單模態(tài)的分類模型
從一種模態(tài)的分類模型開始,例如視覺分類,給定一張圖片,它是不是一只狗呢?

這是三個(gè)二維矩陣疊加在一起形成的彩色圖像,如何解決這個(gè)圖像分類問題呢?因?yàn)榇蠖鄶?shù)神經(jīng)網(wǎng)絡(luò)或分類器只接受二維矩陣,為了制作這個(gè)輸入向量,需要將這個(gè)三維向量分解并將它們疊加在一起,就像下面的圖像所示的那樣。然后,才能能夠通過多分類輸出來獲取目標(biāo)的對(duì)象分類。

對(duì)于單模態(tài)模型,首先有一個(gè)輸入,可以是如上所述的3D矩陣,然后將其傳遞到已經(jīng)訓(xùn)練好的模型中,得到一個(gè)分類(單類或多類)或回歸輸出。
對(duì)于單詞、句子或段落這樣的模態(tài)而言,有兩種類型:書面(文本)和聲音(轉(zhuǎn)錄)。舉個(gè)例子,假設(shè)從一段文本中提取了一個(gè)單詞,想要了解這是正面還是負(fù)面的情緒。該怎么做呢?

為了簡(jiǎn)單起見,可以使用one-hot向量,這是一個(gè)非常長(zhǎng)的向量,其長(zhǎng)度是字典的長(zhǎng)度。這個(gè)字典是我們的模型從訓(xùn)練集中創(chuàng)建的,計(jì)算出它所發(fā)現(xiàn)的所有去重后的單詞。對(duì)于每一個(gè)單詞,在向量中有一個(gè)索引條目。需要注意的是,某些非常低頻的詞語,可能不在字典中。
用這個(gè)one-hot向量將作為最大熵模型的輸入向量,進(jìn)而進(jìn)行情緒分類,命名實(shí)體分類(名字 vs 地方 vs 實(shí)體),或者詞性標(biāo)注(動(dòng)詞,名詞,形容詞)等。如果想要更細(xì)粒度地按單詞運(yùn)行模型,就可以這樣做。
但是,如果想要處理更大量的文本,比如一句話或一段話,該怎么辦呢?
可以將輸入向量變成一個(gè)詞袋向量,但它仍然是一種one-shot編碼,現(xiàn)在對(duì)目標(biāo)文檔中的每個(gè)單詞進(jìn)行編碼,如果一個(gè)維度上有這個(gè)單詞就是1,否則就是0。然后可以運(yùn)行同樣的任務(wù),就像上面做的情緒分類一樣。

最后,在看看聲音模態(tài)。假設(shè)正在聆聽一個(gè)音頻,基本上,音頻是一個(gè)非常長(zhǎng)的一維向量,可以使用此向量并運(yùn)行分類問題以轉(zhuǎn)錄語音。在實(shí)踐中,人們用時(shí)間窗口在音頻信號(hào)中切片,并開始處理該數(shù)據(jù)集以創(chuàng)建Spectogram。在這個(gè)音頻中,檢查獲取了多少低頻與高頻成分,以千赫為記錄在Spectogram中。然后,我們將這個(gè)Spectogram轉(zhuǎn)換為模型的輸入向量。
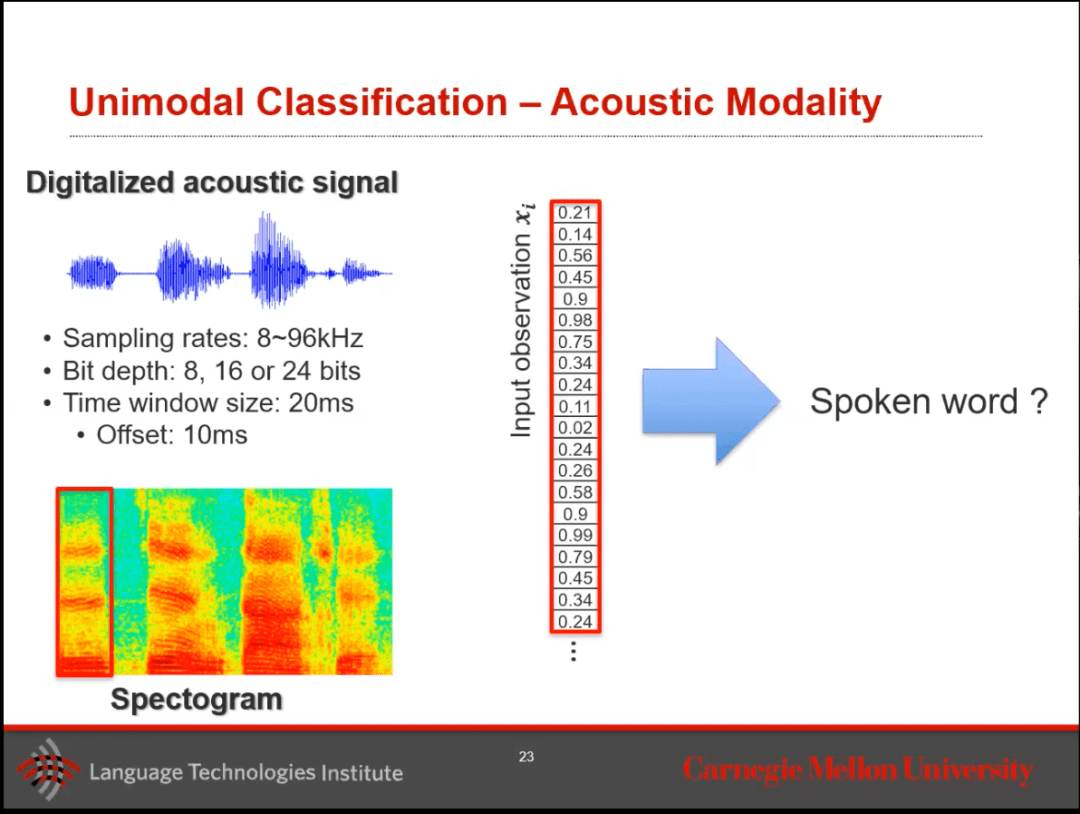
除了僅僅進(jìn)行轉(zhuǎn)錄外,還可以使用這些模型來獲取情感分類或語音質(zhì)量。
2.2 相關(guān)術(shù)語
數(shù)據(jù)集是帶有標(biāo)簽的樣本集合,包括:
- 訓(xùn)練集:在這個(gè)訓(xùn)練集上學(xué)習(xí)分類器
- 驗(yàn)證集:通過查看L1或L2函數(shù)在此處選擇最佳的超參數(shù),基本上希望看到哪些超參數(shù)會(huì)帶來最佳的結(jié)果。
- 測(cè)試集:在這個(gè)保留的測(cè)試集上評(píng)估分類器。
最近鄰居:最簡(jiǎn)單但仍然是最有效的分類器之一。 - 在訓(xùn)練時(shí)間,時(shí)間復(fù)雜度為O(1),測(cè)試時(shí)間為O(N) - 它使用距離度量來找到最近的鄰居。 - 它將使用L1(曼哈頓)或L2(歐幾里得)距離。
2.3 神經(jīng)網(wǎng)絡(luò)基礎(chǔ)
根據(jù)激活函數(shù)的不同,一個(gè)神經(jīng)元可以被稱為一個(gè)線性分類器。神經(jīng)網(wǎng)絡(luò)中每個(gè)部分的組成和功能如下:
1)定義一個(gè)神經(jīng)元的得分函數(shù),目標(biāo)是預(yù)測(cè)該類別標(biāo)簽的得分。例如,對(duì)于圖像分類問題“這是一只狗、貓、鳥還是豬?”,可以將為鴨子、貓、鳥和豬各設(shè)置一個(gè)神經(jīng)元。具有線性激活函數(shù)的神經(jīng)元如下圖所示:

接下來,在這里學(xué)習(xí)權(quán)重和偏置值。
- 定義損失函數(shù)(可能是非線性的)
- 優(yōu)化參數(shù)的權(quán)重(考慮梯度下降)
然后,考慮多層前饋神經(jīng)網(wǎng)絡(luò)。
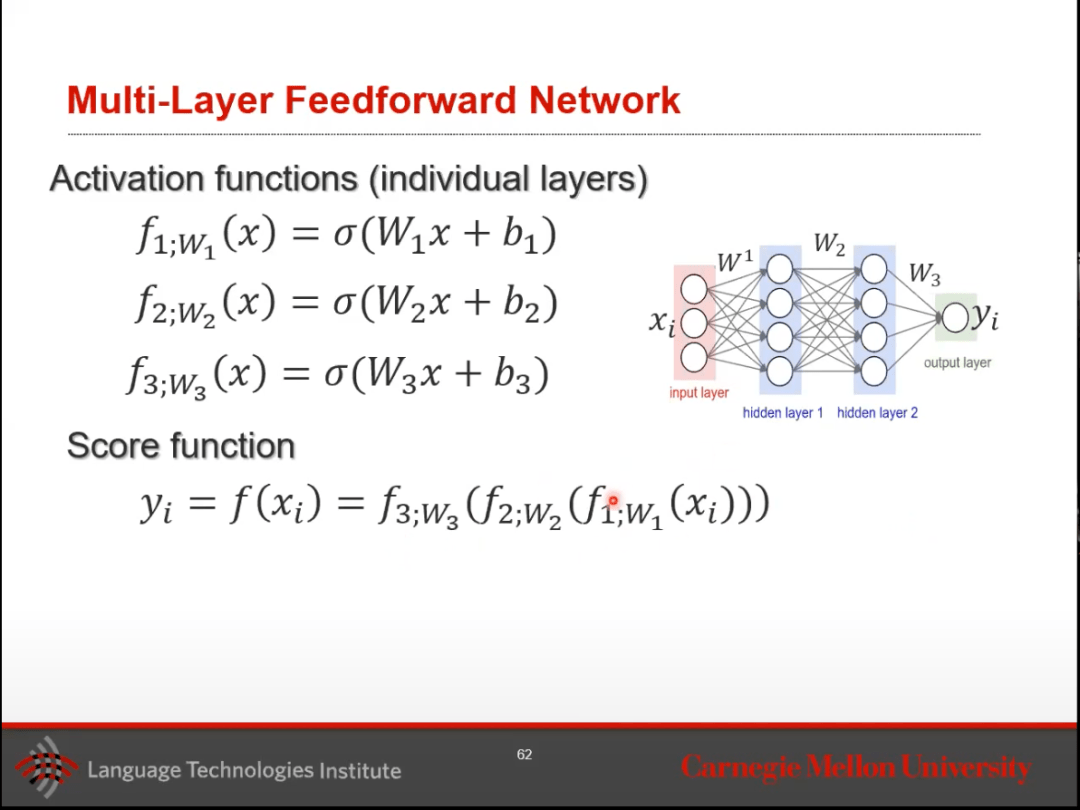
這個(gè)多層網(wǎng)絡(luò)由一個(gè)輸入層,幾個(gè)隱藏層,以及一個(gè)可能包含激活函數(shù)的輸出層組成。每個(gè)前面的隱藏層的輸出作為后面層的輸入。
最后,我還有兩個(gè)概念需要澄清:
- 推理:用于測(cè)試。推理可以被看作是通過輸入獲得評(píng)分/輸出的過程。它既是獲得這個(gè)分?jǐn)?shù)的行為,也涉及到它的使用。
- 模型參數(shù):在訓(xùn)練時(shí)使用,將使用基于梯度的方法進(jìn)行優(yōu)化。基本上,需要有固定訓(xùn)練的數(shù)據(jù),通過學(xué)習(xí)得到最小損失的權(quán)重和偏差。

3. 多模態(tài)機(jī)器學(xué)習(xí)的核心問題
多模態(tài)是一種新的AI/ target=_blank class=infotextkey>人工智能范式,其中各種模態(tài)(文本、語音、視頻、圖像)與多種智能處理算法結(jié)合,以實(shí)現(xiàn)更高的性能。
業(yè)界有多種實(shí)現(xiàn)多模態(tài)的方式,通過多模態(tài)機(jī)器學(xué)習(xí),希望確保該空間中的相似性對(duì)應(yīng)著相應(yīng)概念的相似性,通過存在的其他模態(tài), 給出缺失的模態(tài)內(nèi)容。多模態(tài)應(yīng)用目前包括各種任務(wù),如信息檢索、映射和融合。
在多模態(tài)機(jī)器學(xué)習(xí)中,大約有五個(gè)核心問題——表示、翻譯、對(duì)齊、融合和協(xié)同學(xué)習(xí)。
3.1 多模態(tài)的數(shù)據(jù)表達(dá)
多模態(tài)數(shù)據(jù)的最大挑戰(zhàn)是以一種方式總結(jié)來自多個(gè)模態(tài)(或視圖)的信息,以便綜合使用互補(bǔ)信息,同時(shí)過濾掉冗余的模態(tài)部分。由于數(shù)據(jù)的異質(zhì)性,一些挑戰(zhàn)自然而然地出現(xiàn),包括不同類型的噪聲、模態(tài)(或視圖)的對(duì)齊以及處理缺失數(shù)據(jù)的技術(shù)。目前,主要有兩種的方法來完成多模態(tài)表達(dá):聯(lián)合表達(dá)和協(xié)調(diào)表達(dá)。
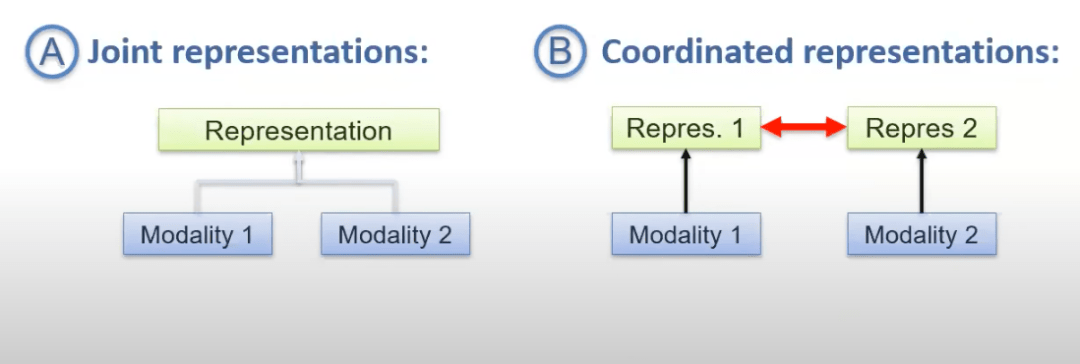

協(xié)調(diào)表達(dá)
多模態(tài)數(shù)據(jù)必須在非常弱的(它們的空間不重疊)或非常強(qiáng)的(最終成為聯(lián)合表示)之間協(xié)調(diào),通過結(jié)構(gòu)化的協(xié)調(diào)來完成嵌入。

協(xié)調(diào)表達(dá)涉及將所有形式投射到它們的空間中,但這些空間使用約束進(jìn)行協(xié)調(diào)。這種方法對(duì)根本上非常不同并且可能不適用于聯(lián)合空間的形式更有用。由于自然界中形式的多樣性,協(xié)調(diào)表達(dá)在多模態(tài)表示領(lǐng)域中比聯(lián)合表達(dá)具有巨大優(yōu)勢(shì),使用約束進(jìn)行協(xié)調(diào)是一種強(qiáng)大的方法。
聯(lián)合表達(dá)
聯(lián)合表達(dá)涉及將所有模態(tài)投影到一個(gè)共同的空間,同時(shí)保留來自給定模態(tài)的信息。訓(xùn)練和推理時(shí)需要所有模態(tài)的數(shù)據(jù),這可能會(huì)使處理缺失數(shù)據(jù)變得困難。另外,通過遞歸模型,可以在每個(gè)時(shí)間步融合模態(tài)的不同視圖,最終使用聯(lián)合表示完成手頭的任務(wù)(如分類,回歸等)。
對(duì)于所有模態(tài)在推斷時(shí)都存在的任務(wù),聯(lián)合表達(dá)更適合。另一方面,如果缺少其中一種模態(tài),則協(xié)調(diào)表達(dá)更適合。
3.2 多模態(tài)機(jī)器翻譯
多模態(tài)機(jī)器翻譯涉及從多個(gè)模態(tài)中提取信息,基于這樣的假設(shè),附加的模態(tài)將包含有用的輸入數(shù)據(jù)的替代視圖。在這個(gè)領(lǐng)域中最重要的任務(wù)是口語翻譯、圖像引導(dǎo)翻譯和視頻引導(dǎo)翻譯,它們分別利用音頻和視覺模態(tài)。這些任務(wù)與它們的單語對(duì)應(yīng)任務(wù)——語音識(shí)別、圖像字幕和視頻字幕——不同之處在于需要模型生成不同語言的輸出。(來源) 下面我們可以看到一個(gè)圖像字幕的例子出了大錯(cuò):
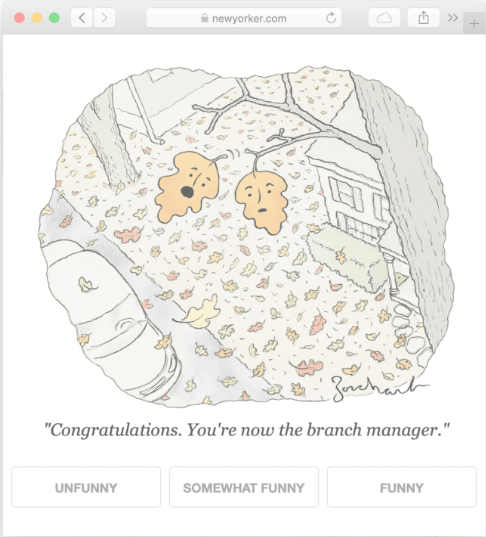
上述模型無法將視覺場(chǎng)景與語法句子進(jìn)行同步理解,這對(duì)于強(qiáng)大的多模態(tài)模型至關(guān)重要。多模態(tài)翻譯模型有兩種類型:基于示例的和生成式的。

基于示例的模型將存儲(chǔ)一個(gè)翻譯詞典,如上所示,然后將其從一種語言模態(tài)映射到另一種。在推理過程中,模型將從字典中提取最接近的匹配項(xiàng),或通過推斷字典提供的信息創(chuàng)建翻譯。這些模型需要存儲(chǔ)更多的信息,運(yùn)行速度非常緩慢。
生成模型在推理時(shí)不需要參考訓(xùn)練數(shù)據(jù)即可產(chǎn)生翻譯。生成模型有3個(gè)類別,分別是基于語法的、變壓器模型和連續(xù)生成模型。
3.3 多模態(tài)的對(duì)齊
多模態(tài)對(duì)齊是找到兩種或更多模態(tài)之間的關(guān)系和對(duì)應(yīng)。
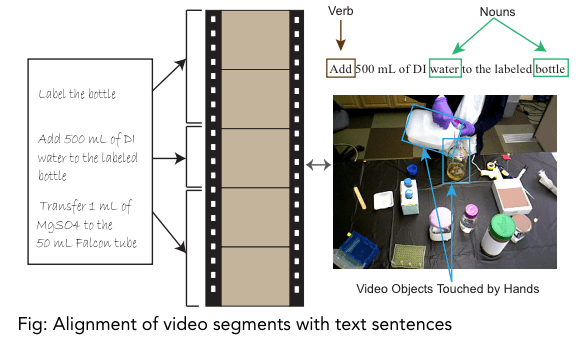
為了對(duì)齊不同的模態(tài),模型必須測(cè)量它們之間的相似度并處理長(zhǎng)距離依賴關(guān)系。多模態(tài)對(duì)齊涉及的其他困難包括缺乏注釋數(shù)據(jù)集、設(shè)計(jì)好的模態(tài)相似性度量以及存在多個(gè)正確的對(duì)齊方式。主要有兩種類型的多模態(tài)對(duì)齊:- 顯式對(duì)齊 :其目標(biāo)是找到模態(tài)之間的對(duì)應(yīng)關(guān)系,并對(duì)同一事件的不同模態(tài)數(shù)據(jù)進(jìn)行對(duì)齊。例如:將語音信號(hào)與轉(zhuǎn)錄對(duì)齊。- 隱式對(duì)齊 :對(duì)齊有助于解決不同任務(wù)時(shí)的模型(例如“注意力”模型)。它是多個(gè)下游任務(wù)(如分類)的先驅(qū)。例如:機(jī)器翻譯
3.4 多模態(tài)的融合
多模態(tài)融合可能是更重要的問題和挑戰(zhàn)之一。融合是將來自兩個(gè)或兩個(gè)以上模態(tài)的信息結(jié)合起來解決分類或回歸問題的實(shí)踐。使用多個(gè)模態(tài)提供更強(qiáng)大的預(yù)測(cè)能力,使我們能夠捕獲互補(bǔ)信息。即使其中一個(gè)模態(tài)缺失,多模態(tài)融合模型仍可使用。
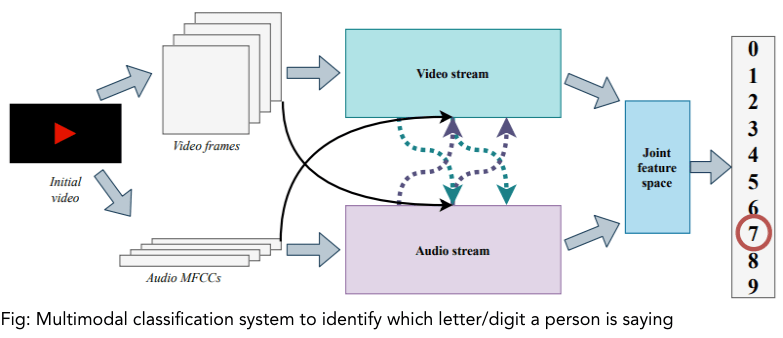
3.5 協(xié)同學(xué)習(xí)
協(xié)同學(xué)習(xí)是將學(xué)習(xí)或知識(shí)從一種模態(tài)轉(zhuǎn)移到另一種模態(tài)的挑戰(zhàn)。對(duì)于在資源有限的模態(tài)下建立模型——如缺乏注釋數(shù)據(jù)、嘈雜的輸入和不可靠的標(biāo)簽,從資源豐富的模態(tài)中轉(zhuǎn)移知識(shí)是相當(dāng)有用的。

小結(jié)
多模態(tài)機(jī)器學(xué)習(xí)是一種新的人工智能范式,結(jié)合各種模態(tài)和智能處理算法以實(shí)現(xiàn)更高的性能。多模態(tài)機(jī)器學(xué)習(xí)中的核心問題包括表示、翻譯、對(duì)齊、融合和協(xié)同學(xué)習(xí)。其中,多模態(tài)數(shù)據(jù)的表達(dá)是最大的挑戰(zhàn)之一,需要使用聯(lián)合表達(dá)和協(xié)調(diào)表達(dá)等方法。多模態(tài)機(jī)器翻譯涉及從多個(gè)模態(tài)中提取信息,基于這樣的假設(shè),附加的模態(tài)將包含有用的輸入數(shù)據(jù)的替代視圖。多模態(tài)對(duì)齊是找到兩種或更多模態(tài)之間的關(guān)系和對(duì)應(yīng),多模態(tài)融合可能是更重要的問題和挑戰(zhàn)之一,協(xié)同學(xué)習(xí)是將學(xué)習(xí)或知識(shí)從一種模態(tài)轉(zhuǎn)移到另一種模態(tài)的挑戰(zhàn)。





