擊這里在線咨詢(xún)客服")

新智元報(bào)道
編輯:桃子
【新智元導(dǎo)讀】手寫(xiě)提示既費(fèi)時(shí)又費(fèi)力,微軟研究人員的APO算法提供了一種自動(dòng)化的解決方案。無(wú)需調(diào)整超參數(shù)或模型訓(xùn)練,APO可以顯著提高提示的性能,并具有可解釋性。
模型調(diào)教得好不好,提示(prompt)最重要。
在優(yōu)化和改進(jìn)提示工程的過(guò)程中,提示變得越來(lái)越精巧、復(fù)雜。

據(jù)google Trends,提示工程在過(guò)去的6個(gè)月受歡迎程度急劇上升,到處都是關(guān)于提示的教程和指南。
比如,一個(gè)在網(wǎng)上爆火的提示工程指南Github已經(jīng)狂瀾28.5k星。
然而,完全用試錯(cuò)法開(kāi)發(fā)提示可能不是最有效的策略。
為了解決這個(gè)問(wèn)題,微軟研究人員開(kāi)發(fā)了一種全新提示優(yōu)化方法,稱(chēng)為自動(dòng)提示優(yōu)化(APO)。

論文地址:https://arxiv.org/pdf/2305.03495.pdf
手寫(xiě)提示省了
近來(lái),各種跡象表明,在大規(guī)模網(wǎng)絡(luò)文本中訓(xùn)練的大型語(yǔ)言模型在跨越各種NLP任務(wù)中有時(shí)表現(xiàn)不佳。
這些LLMs都是通過(guò)提示來(lái)遵循人的指令。然而,編寫(xiě)這些自然語(yǔ)言提示仍然是一個(gè)手工試錯(cuò)的過(guò)程,需要人們付出巨大努力,甚至還得具備專(zhuān)業(yè)知識(shí)。
因此,還得需要自動(dòng),或半自動(dòng)的程序來(lái)幫助程序員寫(xiě)出最好的提示。

最近的一些研究,通過(guò)訓(xùn)練輔助模型,或?qū)μ崾具M(jìn)行可微表示來(lái)研究這個(gè)問(wèn)題。
然而,這些工作假定可以訪問(wèn)到LLM的內(nèi)部狀態(tài)變量,而實(shí)操的人通常通過(guò)API與LLM進(jìn)行交流。
其他的工作則通過(guò)強(qiáng)化學(xué)習(xí)或LLM基礎(chǔ)反饋對(duì)提示進(jìn)行離散操做。
這些算法也可能需要對(duì)LLM的低級(jí)訪問(wèn),還會(huì)產(chǎn)生不可理解的輸出,或依賴(lài)于無(wú)方向蒙特卡羅搜索(monte-carlo search)的語(yǔ)義空間上的提示。
對(duì)此,微軟研究人員提出了自動(dòng)提示優(yōu)化(APO),一個(gè)通用的和非參數(shù)提示優(yōu)化算法。
APO是一種受數(shù)值梯度下降(numerical gradient descent)啟發(fā)的通用非參數(shù)提示優(yōu)化算法,旨在自動(dòng)化和改進(jìn)LLM的快速開(kāi)發(fā)過(guò)程。

APO算法的整體框架
這一算法建立在現(xiàn)有的自動(dòng)化方法的基礎(chǔ)上,包括訓(xùn)練輔助模型,或提示的可微表示,以及使用強(qiáng)化學(xué)習(xí)或基于LLM的反饋進(jìn)行離散操作。
與以前的方法不同,APO通過(guò)在基于文本的蘇格拉底對(duì)話(Socratic dialogue)中使用梯度下降法來(lái)解決離散優(yōu)化的障礙。
它用LLM反饋代替了差異,用LLM編輯代替了反向傳播。
更具體來(lái)講,該算法首先利用小批量的訓(xùn)練數(shù)據(jù)獲得自然語(yǔ)言「梯度」,以描述給定提示中缺陷的。
這些梯度指導(dǎo)編輯過(guò)程,在梯度的相反語(yǔ)義方向上編輯當(dāng)前提示符。
然后,再進(jìn)行更廣泛的集束搜索(beam search),以擴(kuò)大提示的搜索空間,將提示最佳化問(wèn)題轉(zhuǎn)化為集束候選的選擇問(wèn)題。
非參數(shù)「梯度下降」的離散提示優(yōu)化
自動(dòng)提示優(yōu)化框架假設(shè)可以訪問(wèn)由輸入和輸出文本對(duì)(數(shù)字、類(lèi)別、匯總等)組成的初始提示

和
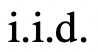
訓(xùn)練數(shù)據(jù):。
要注意的是,所有提示p都是從相干自然語(yǔ)言的空間中提取的。
研究人員假設(shè)訪問(wèn)了一個(gè)黑盒LLM API,,它返回由連接p和x組成的提示符可能的文本延續(xù)y (例如,少樣本提示符和輸入示例,或Chatbot角色和對(duì)話歷史)。
在這種情況下,APO算法迭代精化了提示
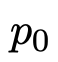
以產(chǎn)生,對(duì)于某些度量函數(shù)

和域內(nèi)測(cè)試或開(kāi)發(fā)數(shù)據(jù)

,這是最佳提示的一個(gè)近似。
梯度下降
在研究的設(shè)置中,梯度下降法是指 (1) 用一批數(shù)據(jù)評(píng)估提示符的過(guò)程,(2) 創(chuàng)建一個(gè)局部丟失信號(hào),其中包含關(guān)于如何改進(jìn)當(dāng)前提示符的信息,然后 (3) 在開(kāi)始下一次迭代之前,在梯度的相反語(yǔ)義方向編輯提示符。
在此,研究人員使用一對(duì)靜態(tài)LLM提示來(lái)完成這個(gè)過(guò)程,如圖所示。
第一個(gè)提示是創(chuàng)建丟失信號(hào)「梯度」,叫做

。
雖然特定的內(nèi)容可能會(huì)有所不同,但是

必須始終考慮當(dāng)前提示

,以及

在一小批數(shù)據(jù)(特別是錯(cuò)誤數(shù)據(jù)集)上的行為,并生成缺陷的自然語(yǔ)言摘要。這個(gè)摘要變成了梯度。
就像傳統(tǒng)的梯度一樣,梯度表示參數(shù)空間中的一個(gè)方向,這會(huì)使模型用當(dāng)前提示描述缺陷的自然語(yǔ)言空間變得更糟糕。
第二個(gè)提示符叫做
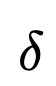
,雖然這個(gè)提示符也是變化的,但它必須始終采用梯度和當(dāng)前提示符,然后在與相反的語(yǔ)義方向上對(duì)執(zhí)行編輯,即修復(fù)指示的問(wèn)題。
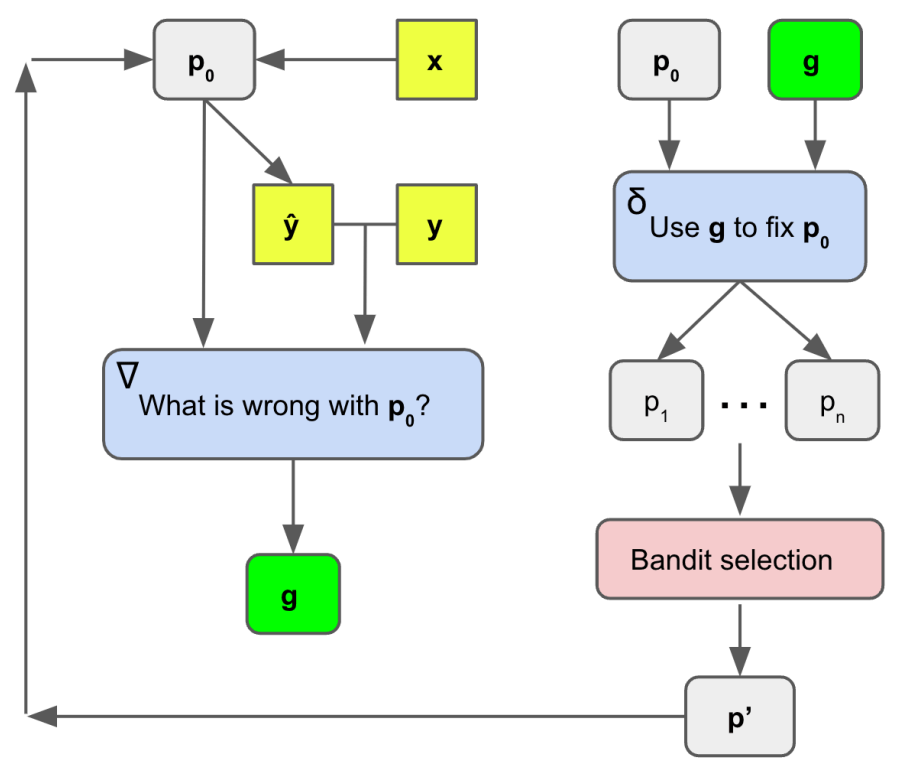
與傳統(tǒng)的機(jī)器學(xué)習(xí)設(shè)置不同,研究人員并沒(méi)有生成一個(gè)單一的梯度或編輯,而是生成了一些方向,可以改善當(dāng)前的提示。
集束搜索
接下來(lái),研究者描述了梯度下降用于指導(dǎo)集束搜索在提示符空間上的運(yùn)行。這個(gè)集束搜索是提示訓(xùn)練算法的外部循環(huán)。

集束搜索是一個(gè)迭代優(yōu)化過(guò)程,在每次迭代中,當(dāng)前提示符用于生成許多新的候選提示符。
接下來(lái),一個(gè)選擇過(guò)程就是用來(lái)決定哪些提示,值得繼續(xù)進(jìn)行到下一次迭代。這個(gè)循環(huán)允許對(duì)多個(gè)提示符候選進(jìn)行增量改進(jìn)和探索。
實(shí)驗(yàn)評(píng)估
為了評(píng)估 APO 的有效性,微軟研究小組將其與三種最先進(jìn)的NLP任務(wù)即時(shí)學(xué)習(xí)基線進(jìn)行了比較,包括越獄檢測(cè)、仇恨語(yǔ)音檢測(cè)、假新聞檢測(cè)和諷刺檢測(cè)。
APO在所有四個(gè)任務(wù)中都持續(xù)超越基線,在蒙特卡洛(MC)和強(qiáng)化學(xué)習(xí)(RL)基線上取得了顯著的進(jìn)步。
平均而言,APO比MC和RL基線分別提高了3.9%和8.2% ,比原始提示

提高了15.3% ,比AutoGPT提高了15.2%。
結(jié)果表明,提出的算法可以提高初始提示輸入31%的性能,超過(guò)最先進(jìn)的提示學(xué)習(xí)基線平均4-8% ,而依賴(lài)較少的LLM API調(diào)用。
此外,研究人員還展示了優(yōu)化過(guò)程的可解釋性,并調(diào)查了算法的缺點(diǎn)。
值得注意的是,這些改進(jìn)是在沒(méi)有額外的模型訓(xùn)練或超參數(shù)優(yōu)化的情況下完成的,這表明了APO如何有效改進(jìn)了LLM的提示。
對(duì)于提示工程來(lái)說(shuō),APO的出現(xiàn)是非常興奮的。
APO通過(guò)使用梯度下降法和集束搜索自動(dòng)化快速優(yōu)化提示過(guò)程,減少了快速開(kāi)發(fā)所需的人力和時(shí)間。
實(shí)證結(jié)果表明,該模型能夠在一系列自然語(yǔ)言處理任務(wù)中迅速提高質(zhì)量。

越獄是一項(xiàng)新的任務(wù),目標(biāo)是確定用戶(hù)對(duì)LLM的輸入是否代表越獄攻擊。我們將越獄攻擊定義為一種用戶(hù)互動(dòng)策略,旨在讓AI打破自己的規(guī)則。
發(fā)現(xiàn)微軟研究員帶來(lái)的改變游戲規(guī)則的自動(dòng)提示優(yōu)化(APO)!一個(gè)強(qiáng)大的通用框架,用于優(yōu)化LLM提示。
參考資料:
https://arxiv.org/pdf/2305.03495.pdf





